Hadoop基本开发环境搭建(原创,已实践)
软件包:
hadoop-2.7.2.tar.gz
hadoop-eclipse-plugin-2.7.2.jar
hadoop-common-2.7.1-bin.zip
eclipse
jdk1.8.45
hadoop-2.7.2(linux和windows各一份)
Linux系统(centos或其它)
Hadoop安装环境
准备环境:
安装Hadoop,安装步骤参见Hadoop安装章节。
安装eclipse。
搭建过程如下:
1. 将hadoop-eclipse-plugin-2.7.2.jar拷贝到eclipse/dropins目录下。
2. 解压hadoop-2.7.2.tar.gz到E盘下。
3. 下载或者编译hadoop-common-2.7.2(由于hadoop-common-2.7.1可以兼容hadoop-common-2.7.2,因此这里使用hadoop-common-2.7.1),如果想编译可参考相关文章。
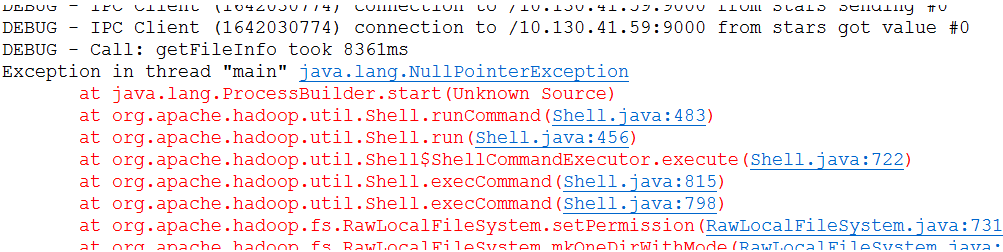
4. 将hadoop-common-2.7.1下的文件全部拷贝到E:\hadoop-2.7.2\bin下面,hadoop.dll在system32下面也要放一个,否则会报下图的错误:
并配置系统环境变量HADOOP_HOME:

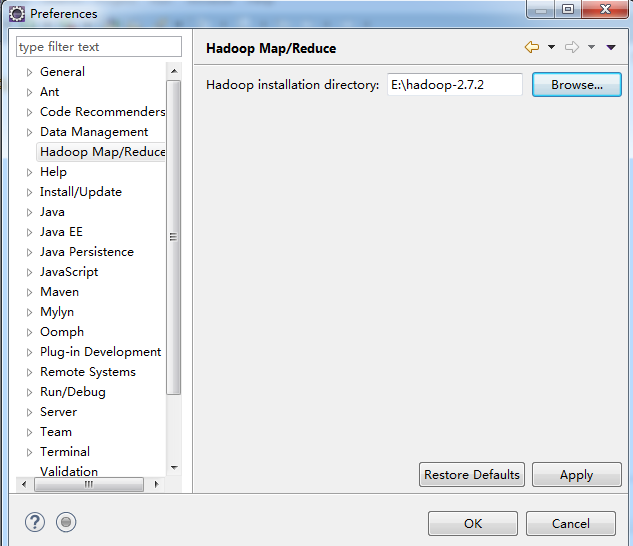
5. 启动eclipse,打开windows->Preferences的Hadoop Map/Reduce中设置安装目录:
6. 打开Windows->Open Perspective中的Map/Reduce,在此perspective下进行hadoop程序开发。
7. 打开Windows->Show View中的Map/Reduce Locations,如下图右键选择New Hadoop location…新建hadoop连接。
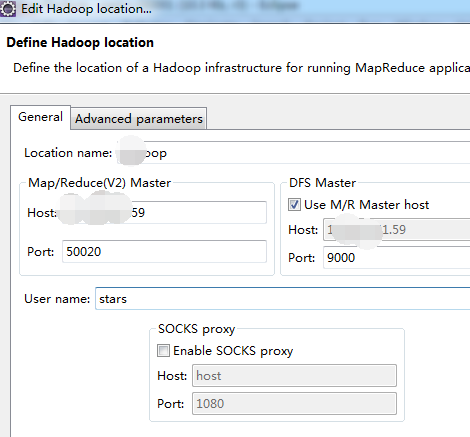
8. 

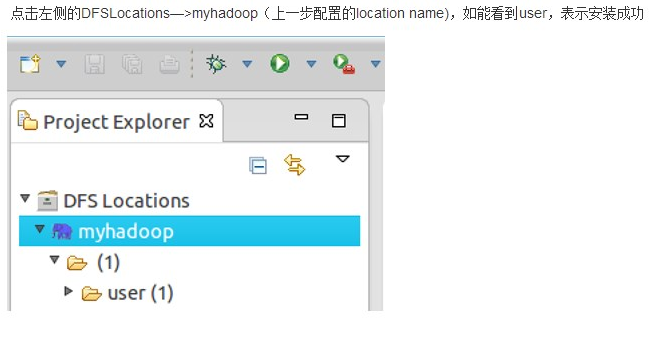
9. 新建工程并添加WordCount类:

10. 把log4j.properties和hadoop集群中的core-site.xml加入到classpath中。我的示例工程是maven组织,因此放到src/main/resources目录。
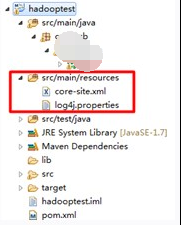
11. log4j.properties文件内容如下:
log4j.rootLogger=debug,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
log4j.logger.com.codefutures=DEBUG
12. 在HDFS上创建目录input
hadoop dfs -mkdir input
13. 拷贝本地README.txt到HDFS的input里
hadoop dfs -copyFromLocal /usr/local/hadoop/README.txt input
14. hadoop集群中hdfs-site.xml中要添加下面的配置,否则在eclipse中无法向hdfs中上传文件:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
15. 若碰到Cannot connect to VM com.sun.jdi.connect.TransportTimeoutException,则关闭防火墙。
16. 书写代码如下:
package com.hadoop.example; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount {
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context)
throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); System.out.print("--map: " + value.toString() + "\n");
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
System.out.print("--map token: " + word.toString() + "\n");
context.write(word, one); System.out.print("--context: " + word.toString() + "," + one.toString() + "\n");
}
}
} public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException { int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result); System.out.print("--reduce: " + key.toString() + "," + result.toString() + "\n");
}
} public static void main(String[] args) throws Exception { System.setProperty("hadoop.home.dir", "E:\\hadoop-2.7.2"); Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs(); if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
} Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setNumReduceTasks(2);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
17. 点击WordCount.java,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹,java application里面如果没有wordcount就先把当前project run--->java applation一下。
hdfs://localhost:9000/user/hadoop/input hdfs://localhost:9000/user/hadoop/output
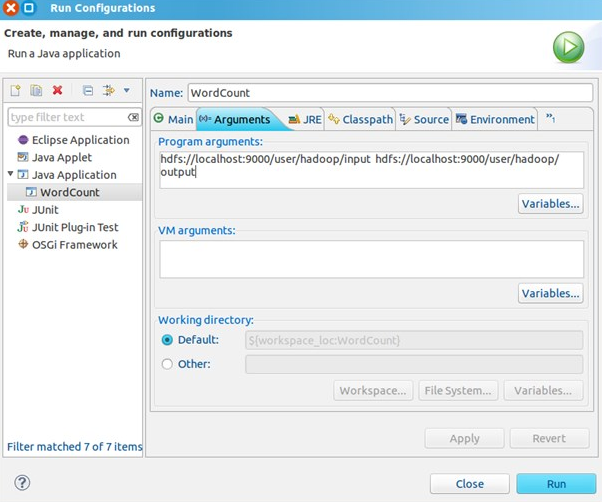
其中的localhost为hadoop集群的域名,也可以直接使用IP,如果使用域名的话需要编辑C:\Windows\System32\drivers\etc\HOSTS,添加IP与域名的映射关系
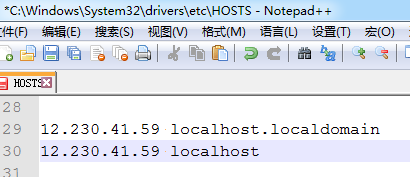
18. 运行完成后,查看运行结果:
方法1:
hadoop dfs -ls output
可以看到有两个输出结果,_SUCCESS和part-r-00000
执行hadoop dfs -cat output/*
方法2:

Hadoop基本开发环境搭建(原创,已实践)的更多相关文章
- eclipse+HBASE开发环境搭建(已实践)
开发准备: jdk1.8.45 hbase-1.2.2(windows下和linux个留一份) hadoop-2.7.2(linux一份) Linux系统(centos或其它) Hadoop安装环境 ...
- Hadoop Eclipse开发环境搭建
This document is from my evernote, when I was still at baidu, I have a complete hadoop developme ...
- Hadoop项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Mav ...
- (转)Hadoop Eclipse开发环境搭建
来源:http://www.cnblogs.com/justinzhang/p/4261851.html This document is from my evernote, when I was s ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- 【hadoop之翊】——windows 7使用eclipse下hadoop应用开发环境搭建
由于一些缘故,这节内容到如今才写.事实上弄hadoop有一段时间了,能够编写一些小程序了,今天来还是来说说环境的搭建.... 说明一下:这篇文章的步骤是接上一篇的hadoop文章的:http://bl ...
- ubuntu14.04 Hadoop单机开发环境搭建MapReduce项目
Hadoop官网:http://hadoop.apache.org/ 目前最新的版本是Hadoop 3.0.0-alpha1前提:java 1.6 版本以上 首先从官网下载压缩包(hadoop-3.0 ...
- hadoop本地开发环境搭建
1:下载hadoop2.7.3并解压 2:配置hadoop2.7.3环境变量 HADOOP_HOME %HADOOP_HOME%\bin 3:下载hadoop-eclipse-plugin插件 网址: ...
- hadoop 分布式开发环境搭建
一,安装java环境 添加java环境变量 vi /etc/profile # add by tank export JAVA_HOME=/data/soft/jdk/jdk1.7.0_71 ex ...
随机推荐
- html css基础(一)
1.HTML:做静态网页,是一种标签语言, HTML结构: 一个HTML文档由4个基本部分组成: ① 一个文档声明:<!DOCTYPE HTML> ② 一个html标签对:<html ...
- 复习php的一些函数
2014.07.04 查看ecshop的一些源码,学习了一些函数.
- [Poi2000]公共串 && hustoj2797
传送门:http://begin.lydsy.com/JudgeOnline/problem.php?id=2797 题目大意:给你几个串求出几个串中的最长公共子串. 题解:先看n最大才5,所以很容易 ...
- iOS 之 编外知识点
iOS 使用github iOS 开源库介绍 iOS 优质方案 iOS 开发framework 后端数据库使用 Bomb方案 iOS 错误及解决汇总 后台 之 Bmob 申请苹果企业账号
- django QuerySet里那些常用又不常见的技巧
QuerySet 像Entry.Objects.all(),这些操作返回的是一个QuerySet对象,这个对象比较特别,并不是执行Objects.all(),或者filter之后就会与数据库交互,具体 ...
- 利用python 实现微信公众号群发图片与文本消息功能
在微信公众号开发中,使用api都要附加access_token内容.因此,首先需要获取access_token.如下: #获取微信access_token def get_token(): paylo ...
- 设置与菜单项关联的Activity
有些时候,应用程序需要单击某个菜单项时启动其他Activity(包括其他Service).对于这种需求,Android设置不需要开发者编写任何事件处理代码,只要调用MenuItem的setIntent ...
- word中利用宏替换标点标点全角与半角
Alt+F11,然后插入-模块: 复制下面代码到编辑窗口: Sub 半角标点符号转换为全角标点符号() '中英互译文档中将中文段落中的英文标点符号替换为中文标点符号 Dim i As Paragrap ...
- HttpSesstionActivationLIstener示例
HttpSesstionActivationLIstener示例: http://www.cnblogs.com/xdp-gacl/p/3969249.html 钝化的session会已session ...
- Spring @Aspect进行类的接口扩展
Spring @Aspect进行类的接口扩展: XML: <?xml version="1.0" encoding="UTF-8"?> <be ...