数据库行转列、列转行,pivot透视多列

这就是典型的行转列问题。
首先说下最简单的思路 用union all
select year,sum(m1) m1,sum(m2) m2,sum(m3) m3,sum(m4) m4
from
(
select year,count m1,0 m2,0 m3,0 m4 from atest where month = 1
union all
select year,0 m1,count m2,0 m3,0 m4 from atest where month = 2
union all
select year,0 m1,0 m2,count m3,0 m4 from atest where month = 3
union all
select year,0 m1,0 m2,0 m3,count m4 from atest where month = 4
) group by year;
下面是高效的简洁的方法
select year,sum(decode(month,'1', count,null)) "m1",
sum(decode(month,'2', count,null)) "m2",
sum(decode(month,'3', count,null)) "m3",
sum(decode(month,'4', count,null)) "m4"
from atest
group by year
其中 DECODE函数是oracle特有的,跟case when 类似。Decode(表达式1(表达式1可以是查询结果或者列),值1,翻译值1,值2,翻译值2,缺省值)
例:select decode(a.brxb,1,’男’,2,’女’) from ms_brda a
如果不是oracle数据库就可以用case when代替
select year,sum(case month when '1'
then count else null end) "m1",
sum(case month when '2' then count else null end) "m2",
sum(case month when '3' then count else null end) "m3",
sum(case month when '4' then count else null end) "m4"
from atest
group by year
还有Oracle11g新出的pivot函数
Select * from
atest pivot(sum(count) for month in(‘1’ m1,’2’ m2,’3’ m3,’4’ m4));
Oracle 11g 行列互换 pivot 和 unpivot 说明
在Oracle 11g中,Oracle 又增加了2个查询:pivot(行转列) 和unpivot(列转行)
参考:http://blog.csdn.net/tianlesoftware/article/details/7060306、http://www.oracle.com/technetwork/cn/articles/11g-pivot-101924-zhs.html
google 一下,网上有一篇比较详细的文档:http://www.oracle-developer.net/display.php?id=506
pivot 列转行
测试数据 (id,类型名称,销售数量),案例:根据水果的类型查询出一条数据显示出每种类型的销售数量。
SQL
create table demo(id int,name varchar(20),nums int); ---- 创建表
insert into demo values(1, '苹果', 1000);
insert into demo values(2, '苹果', 2000);
insert into demo values(3, '苹果', 4000);
insert into demo values(4, '橘子', 5000);
insert into demo values(5, '橘子', 3000);
insert into demo values(6, '葡萄', 3500);
insert into demo values(7, '芒果', 4200);
insert into demo values(8, '芒果', 5500);
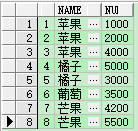
行转列查询
SQL
select * from (select name, nums from demo) pivot (sum(nums) for name in ('苹果' 苹果, '橘子', '葡萄', '芒果'));

注意: pivot(聚合函数 for 列名 in(类型)) ,其中 in(‘’) 中可以指定别名,in中还可以指定子查询,比如 select distinct code from customers 但是不能直接使用,需要使用动态SQL或者放在XML中
当然也可以不使用pivot函数,等同于下列语句,只是代码比较长,容易理解
SQL
------ 多项子查询
select * from (select sum(nums) 苹果 from demo where name='苹果'),(select sum(nums) 橘子 from demo where name='橘子'),
(select sum(nums) 葡萄 from demo where name='葡萄'),(select sum(nums) 芒果 from demo where name='芒果');
------ decode 函数利用
select sum(decode(name,'苹果',nums)) 苹果, sum(decode(name,'橘子',nums)) 橘子,
sum(decode(name,'葡萄',nums)) 葡萄, sum(decode(name,'芒果',nums)) 芒果 from demo
unpivot 行转列
顾名思义就是将多列转换成1列中去
案例:现在有一个水果表,记录了4个季度的销售数量,现在要将每种水果的每个季度的销售情况用多行数据展示。
创建表和数据

列转行查询
SQL
select id , name, jidu, xiaoshou from Fruit unpivot (xiaoshou for jidu in (q1, q2, q3, q4) )
注意: unpivot没有聚合函数,xiaoshou、jidu字段也是临时的变量
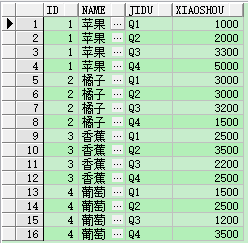
同样不使用unpivot也可以实现同样的效果,只是sql语句会很长,而且执行速度效率也没有前者高
SQL
select id, name ,'Q1' jidu, (select q1 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,'Q2' jidu, (select q2 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,'Q3' jidu, (select q3 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,'Q4' jidu, (select q4 from fruit where id=f.id) xiaoshou from Fruit f
XML类型
上述pivot列转行示例中,你已经知道了需要查询的类型有哪些,用in()的方式包含,假设如果您不知道都有哪些值,您怎么构建查询呢?
pivot 操作中的另一个子句 XML 可用于解决此问题。该子句允许您以 XML 格式创建执行了 pivot 操作的输出,在此输出中,您可以指定一个特殊的子句 ANY 而非文字值
示例如下:
SQL
select * from (
select name, nums as "Purchase Frequency"
from demo t
)
pivot xml (
sum(nums) for name in (any)
)
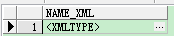
如你所见,列 NAME_XML 是 XMLTYPE,其中根元素是 <PivotSet>。每个值以名称-值元素对的形式表示。你可以使用任何 XML 分析器中的输出生成更有用的输出

结论
Pivot 为 SQL 语言增添了一个非常重要且实用的功能。您可以使用 pivot 函数针对任何关系表创建一个交叉表报表,而不必编写包含大量 decode 函数的令人费解的、不直观的代码。同样,您可以使用 unpivot 操作转换任何交叉表报表,以常规关系表的形式对其进行存储。Pivot 可以生成常规文本或 XML 格式的输出。如果是 XML 格式的输出,您不必指定 pivot 操作需要搜索的值域。
在这附上pivot in 多列,不固定列的动态实现方法
CREATE OR REPLACE PROCEDURE PIVOT_TEST IS
V_SQL VARCHAR2(2000);
CURSOR CURSOR_1 IS SELECT WM_CONCAT(''''|| ( SJWZ)||''''||'as '|| sjwz) SJWZ from (select distinct SJWZ from f_wz_lbmc where ckbh=2);
BEGIN
V_SQL := 'select * from (select sum(a.jhje) 金额 ,c.lbmc 类别名称 ,e.ksmc 科室名称,e.sjks 上级科室
from p_wz_ly02 a,d_wz_wpfl b,d_wz_lbmc c,p_wz_ly01 d,d_gy_ksdm e
where a.wpbh=b.wpbh
and b.lbbh=c.lbbh
and a.djbh=d.djbh
and d.ksdm=e.ksdm
and d.ckbh= 2
group by c.lbmc , e.ksmc,e.sjks
) pivot(sum(金额) for 类别名称 IN (';
FOR V_SJWZ IN CURSOR_1
LOOP
V_SQL := V_SQL ||V_SJWZ.SJWZ
;
END LOOP;
V_SQL := V_SQL || ')) ORDER BY 上级科室';
--DBMS_OUTPUT.PUT_LINE(V_SQL);
V_SQL := 'CREATE OR REPLACE VIEW PIVOT_TEST11 AS '|| V_SQL;
--DBMS_OUTPUT.PUT_LINE(V_SQL);
EXECUTE IMMEDIATE V_SQL;
END;
注意有时候会报权限不足错误,需要使用dba用户授权
Grant create any view to user;
还有一种在命令行(或者pl/sql的命令窗口)中实现的
clear columns
COLUMN temp_in_statement new_value str_in_statement
SQL> SELECT WM_CONCAT(''''||SJWZ||''''||'as '|| sjwz) as temp_in_statement from f_wz_lbmc where ckbh=1;
TEMP_IN_STATEMENT
--------------------------------------------------------------------------------
'燃料油料','办公用品','五金电料','房屋修缮','卫生用品','印刷品','被服材料','专项物质','其他'
SQL> select * from (select sum(a.jhje) 金额 ,c.lbmc 类别名称 ,e.ksmc 科室名称,e.sjks 上级科室
2 from p_wz_ly02 a,d_wz_wpfl b,d_wz_lbmc c,p_wz_ly01 d,d_gy_ksdm e
3 where a.wpbh=b.wpbh
4 and b.lbbh=c.lbbh
5 and a.djbh=d.djbh
下面是几个字符串转换函数
多行转字符串
这个比较简单,用||或concat函数可以实现
SQL
select concat(id,username) str from app_user ;
select id||username str from app_user;
字符串转多列
实际上就是拆分字符串的问题,可以使用 substr、instr、regexp_substr函数方式
字符串转多行
使用union all函数等方式
listagg函数
SQL
select listagg(ename,' , ') within group (order by ename) from emp;
语法: listagg(列名,分隔符) within group (order by 列名)
4、需要注意的事项如下:
(1). 必须得分组,也就是说group by是必须的。
(2). listagg函数的第一个参数是需要显示的字段,也就是log_name;第二个参数是数值之间的分隔符,可以是任意字符;同时还需要进行排序和分组within group (order by name)
wm_concat函数
首先让我们来看看这个神奇的函数wm_concat(列名),该函数可以把列值以","号分隔起来,并显示成一行,接下来上例子,看看这个神奇的函数如何应用准备测试数据
create table test(id number,name varchar2(20));
insert into test values(1,'a');
insert into test values(1,'b');
insert into test values(1,'c');
insert into test values(2,'d');
insert into test values(2,'e');
效果1 : 行转列 ,默认逗号隔开
SQL
select wm_concat(name) name from test;

效果2: 把结果里的逗号替换成"|"
SQL
select replace(wm_concat(name),',','|') from test;
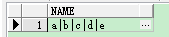
效果3: 按ID分组合并name
SQL
select id,wm_concat(name) name from test group by id;

sql语句等同于下面的sql语句
SQL
-------- 适用范围:8i,9i,10g及以后版本 ( MAX + DECODE )
select id, max(decode(rn, 1, name, null)) || max(decode(rn, 2, ','||name, null)) || max(decode(rn, 3, ','||name, null)) str
from (select id, name ,row_number() over(partition by id order by name) as rn from test) t group by id order by 1;
-------- 适用范围:8i,9i,10g及以后版本 ( ROW_NUMBER + LEAD )
select id, str from (select id,row_number() over(partition by id order by name) as rn,name || lead(',' || name, 1)
over(partition by id order by name) || lead(',' || name, 2) over(partition by id order by name) || lead(',' || name, 3)
over(partition by id order by name) as str from test) where rn = 1 order by 1;
-------- 适用范围:10g及以后版本 ( MODEL )
select id, substr(str, 2) str from test model return updated rows partition by(id) dimension by(row_number()
over(partition by id order by name) as rn) measures (cast(name as varchar2(20)) as str) rules upsert iterate(3)
until(presentv(str[iteration_number + 2], 1, 0)=0) (str[0] = str[0] || ',' || str[iteration_number + 1]) order by 1;
-------- 适用范围:8i,9i,10g及以后版本 ( MAX + DECODE )
select t.id id, max(substr(sys_connect_by_path(t.name, ','), 2)) str from (select id, name, row_number()
over(partition by id order by name) rn from test) t start with rn = 1 connect by rn = prior rn + 1 and id = prior id
group by t.id;
懒人扩展用法:
案例: 我要写一个视图,类似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多个字段,要是靠手工写太麻烦了,有没有什么简便的方法? 当然有了,看我如果应用wm_concat来让这个需求变简单,假设我的APP_USER表中有(id,username,password,age)4个字段。查询结果如下
SQL
/** 这里的表名默认区分大小写 */
select 'create or replace view as select '|| wm_concat(column_name) || ' from APP_USER' sqlStr
from user_tab_columns where table_name='APP_USER';

利用系统表方式查询
SQL
select * from user_tab_columns

数据库行转列、列转行,pivot透视多列的更多相关文章
- 微软BI 之SSIS 系列 - 在 SQL 和 SSIS 中实现行转列的 PIVOT 透视操作
开篇介绍 记得笔者在 2006年左右刚开始学习 SQL Server 2000 的时候,遇到一个面试题就是行转列,列转行的操作,当时写了很长时间的 SQL 语句最终还是以失败而告终.后来即使能写出来, ...
- SqlServer行转列(PIVOT),列转行(UNPIVOT)总结
PIVOT用于将列值旋转为列名(即行转列) 语法: table_source PIVOT( 聚合函数(value_column) FOR pivot_column IN(<column_list ...
- SQL 行转列 列转行 PIVOT UNPIVOT
1.基础表 2.行转列,注意ISNULL函数的使用,在总成绩的统计中,ISNULL(-,0) 有必要使用 3.列转行,对列语文.数学.英语.政治,进行列转行,转为了2列,score scname 这两 ...
- Sql Server 列转行 Pivot使用
今天正好做 数据展示,用到了列转行,行转列有多种方式,Pivot是其中的一种,Povit 是sql server 2005以后才出现的功能, 下面的业务场景: 每个月,进货渠道的总计数量[Total] ...
- 列转行pivot函数在SQL Sever里面和Oracle里面的用法区别
首先pivot是一个列转行的函数,反向用是unpivot(行转列). 在SQL sever中可以这么写 SELECT * FROM [TABLE] /*数据源*/ AS A PIVOT ( MAX/* ...
- 数据库行转列的sql语句
问题描述 假设有张学生成绩表(CJ)如下Name Subject Result张三 语文 80张三 数学 90张三 物理 85李四 语文 85李四 数学 92李四 物理 82 现在 想写 sql 语句 ...
- PIVOT 用于将列值旋转为列名
PIVOT 用于将列值旋转为列名(即行转列),在 SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT 的一般语法是:PIVOT(聚合函数(列) FOR 列 in (…) )A ...
- 对于多个列的转行(一个值均匀分布在两个列中),对于个别字段通过取别名,join方式解决。
例如,这个表的结构: select r.* from RPDATA2016 r WHERE r.data_bbid='HY052' 如图 对于最后两列,如果是字符类型,会存在倒数第二列,是数字类型,会 ...
- 剑指offer系列——二维数组中,每行从左到右递增,每列从上到下递增,设计算法找其中的一个数
题目:二维数组中,每行从左到右递增,每列从上到下递增,设计一个算法,找其中的一个数 分析: 二维数组这里把它看作一个矩形结构,如图所示: 1 2 8 2 4 9 12 4 7 10 13 6 8 11 ...
随机推荐
- mock基本使用
**一.mock解决的问题** 开发时,后端还没完成数据输出,前端只好写静态模拟数据.数据太长了,将数据写在js文件里,完成后挨个改url.某些逻辑复杂的代码,加入或去除模拟数据时得小心翼翼.想要尽可 ...
- nginx-高并发配置 第七章
一 .nginx 服务配置优化: 1.nginx进程数,建议按照cpu数目来指定,一般为它的倍数.worker_processes 定义了nginx对外提供web服务时的worker进程数.最优值取决 ...
- UI自动化(四)css样式
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- JavaScript(数据类型、字符串操作)
JS基础 建议:一般情况下不在 head 标签中写 js 语句,因为该 js 语句会在 body 加载之前就执行,可能导致某些效果无效 // 单行注释 /*多行 * 注释*/ // 控制台输出语句 c ...
- Go 接口(interface)
文章转载地址:https://www.flysnow.org/2017/04/03/go-in-action-go-interface.html 1.什么是 interface? 简单的说,i ...
- Lintcode105 Copy List with Random Pointer solution 题解
[题目描述] A linked list is given such that each node contains an additional random pointer which could ...
- SpringMVC 拦截器HandlerInterceptor(一)
HandlerInterceptor 接口: 进入 Handler方法之前执行比如身份认证,如果认证通过表示当前用户没有登陆,需要此方法拦截不再向下执行 boolean preHandle(HttpS ...
- Harbor私有仓库中如何彻底删除镜像释放存储空间?
简介: Harbor私有仓库运行一段时间后,仓库中存有大量镜像,会占用太多的存储空间.直接通过Harbor界面删除相关镜像,并不会自动删除存储中的文件和镜像.需要停止Harbor服务,执行垃圾回收命令 ...
- ECharts注释
<!DOCTYPE html> <head> <meta charset="utf-8"> <title>ECharts</t ...
- Qgis练手
师妹推荐了一个神器 Qgis,因为看我拿Echarts和Excel缝缝补补效率实在太低下. 还记得,以前写过一个“echarts画中国地图并上色”的笔记,那个应付一下事还行,真正需要精细画图的时候还得 ...