Hive环境的安装
hive是什么:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能(HQL)
hive有什么用
1.通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
2.可以用来进行数据提取转化加载(ETL)
3.可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制
4.允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
5.HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户
适用场景
1.Hive 并不能够在大规模数据集上实现低延迟快速的查询
2.Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(不包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)
1.首先需要搭建hadoop环境:hadoop集群的搭建
2.mysql数据库的安装:CentOS安装mysql源码包
3.创建Hive数据库
4.上传hive安装包到/sur/local/src中,并且解压缩
cd /usr/local/src
tar -zxvf apache-hive-2.0.1.0-bin.tar.gz
5.解压缩完成后,复制到上级目录
mv apache-hive-2.0.1.0-bin. ../
6.配置hive-site.xml
cd /usr/local/apache-hive-2.1.0-bin/conf
vim hive-site.xml
内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://guoyansi128:3306/hive?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>gys</value>
</property>
</configuration>
7.查看文件,是否有hive-site.xml

8.复制java connector到依赖库
下载mysql-connector-java-5.1.12.tar.gz,并且上传至/usr/local/src并且解压缩
tar -zxvf mysql-connector-java-tar.gz
复制其中的mysql-connector-java-5.1.12-bin.jar到/usr/local/apache-hive-2.0.1.0-bin/lib
cp mysql-connector-java-5.1.12-bin.jar /usr/local/apache-hive-2.0.1.0-bin/lib
9.修改 .bash_profile文件
vim /root/.bash_profile
在末尾添加
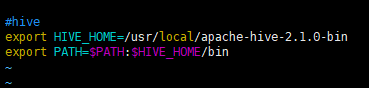
#hive
export HIVE_HOME=/usr/local/apache-hive-2.1.0-bin
export PATH=$PATH:$HIVE_HOME/bin
10.查看 mysql是否启动
service mysqld status //查看状态
service mysqld start //启动
service mysqld stop //停止
11.元数据库初始化
schematool -dbType mysql -initSchema
12.启动Hive
cd /usr/local/apache-hive-2.1.0-bin/bin
./hive
13.启动成功后会出现 hive> 表示环境安装成功

Hive的基本应用(Hive shell模式,命令行模式)
上面13是进入了Hive shell模式
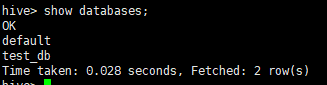
Hive shell模式(前面有hive>)查看数据库:
show databases;
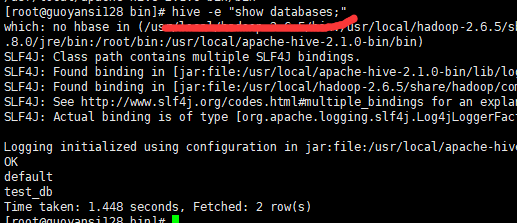
命令行模式查看databases;
hive -e "show databases;"
Hive环境的安装的更多相关文章
- Hive环境的安装部署(完美安装)(集群内或集群外都适用)(含卸载自带mysql安装指定版本)
Hive环境的安装部署(完美安装)(集群内或集群外都适用)(含卸载自带mysql安装指定版本) Hive 安装依赖 Hadoop 的集群,它是运行在 Hadoop 的基础上. 所以在安装 Hive 之 ...
- Hive 环境的安装部署
Hive在客户端上的安装部署 一.客户端准备: 到这我相信大家都已经打过三节点集群了,如果是的话则可以跳过一,直接进入二.如果不是则按流程来一遍! 1.克隆虚拟机,见我的博客:虚拟机克隆及网络配置 2 ...
- Windows环境下安装Hadoop+Hive的使用案例
Hadoop安装: 首先到官方下载官网的hadoop2.7.7,链接如下 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 找网盘的 ...
- 在Hadoop1.2.1分布式集群环境下安装hive0.12
在Hadoop1.2.1分布式集群环境下安装hive0.12 ● 前言: 1. 大家最好通读一遍过后,在理解的基础上再按照步骤搭建. 2. 之前写过两篇<<在VMware下安装Ubuntu ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 《Programming Hive》读书笔记(一)Hadoop和hive环境搭建
<Programming Hive>读书笔记(一)Hadoop和Hive环境搭建 先把主要的技术和工具学好,才干更高效地思考和工作. Chapter 1.Int ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- Spark环境搭建(四)-----------数据仓库Hive环境搭建
Hive产生背景 1)MapReduce的编程不便,需通过Java语言等编写程序 2) HDFS上的文缺失Schema(在数据库中的表名列名等),方便开发者通过SQL的方式处理结构化的数据,而不需要J ...
- Hive数据仓库工具安装
一.Hive介绍 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单SQL查询功能,SQL语句转换为MapReduce任务进行运行. 优点是可以通过类S ...
随机推荐
- 浅谈jQuery的promise
jquery中的Promise,也就是我们所知道的Deferred对象. 举例1: var data=""; function runAsync(){ var def = $.De ...
- Let me introduce myself
介绍自己,从开学到这上半学期结束,不知道说了多少个版本.开学军训,要自我介绍:军训结束,在班里要自我介绍:参加社团,面试要自我介绍.....不能说对每个人,至少对于我来说,在众人面前开口介绍自己,总还 ...
- Database Administration Statements
MySQL 5.5 Reference Manual / SQL Statement Syntax / Database Administration Statements / Table ...
- Linux3.10.0块IO子系统流程(7)-- 请求处理完成
和提交请求相反,完成请求的过程是从低层驱动开始的.请求处理完成分为两个部分:上半部和下半部.开始时,请求处理完成总是处在中断上下文,在这里的主要任务是将已完成的请求放到某个队列中,然后引发软终端让中断 ...
- 使用Git上传项目到Gitee
参考原文链接为:https://blog.csdn.net/qq944639839/article/details/79864081 1.打开GitBash 2. cd Client //进入工程目录 ...
- python 文件读写时用open还是codecs.open
当我面有数据需要保存时,第一时间一般会想到写到一个txt文件中,当然,数据量比较大的时候还是写到数据库比较方便管理,需要进行网络传输时要序列化,json化.下面主要整理一下平时用的最多的写入到文件中, ...
- 读txt文件乱码
/** * 读入TXT文件 */public static List<String> readFile(String pathName) {// 绝对路径或相对路径都可以,写入文件时演示相 ...
- 《深入.NET平台和C#编程》内部测试题-笔试试卷答案
1) 以下关于序列化和反序列化的描述错误的是( C). a) 序列化是将对象的状态存储到特定存储介质中的过程 b) 二进制格式化器的Serialize()和Deseria ...
- mysql数据库简单入门
1.xampp 跨平台 优点:兼容性高 2. apache(服务器) 著名的集成环境(也叫集成安装包) 功能:一般在网站上运行,优点:稳定 缺点:性能上有瓶颈 nginx 优点:快 3. mysql ...
- Python:从入门到实践--第十章--文件和异常--练习
#.python学习笔记:在文本编辑器中新创建一个文件,写几句话老总结你至此学到的python知识 #其中‘In Python you can’ 打头.将这个文件命名为learning_python. ...