音频标签化1:audioset与训练模型 | 音频特征样本
随着机器学习的发展,很多“历史遗留”问题有了新的解决方案。这些遗留问题中,有一个是音频标签化,即如何智能地给一段音频打上标签的问题,标签包括“吉他”、“男中音”、“流水声”、“嘻哈”、“节奏慢”、“重低音”等等,可以是多个标签。
一旦能正确的打上标签,特别是多个标签时,就能有效地应用于很多场景,比如分离出纯乐器的音频、聚合有男中音的音频、区分出有鸟叫的音频,等等。
本文从机器学习的思路,简单讲解如何解决音频标签化的问题。
如果想通过机器学习的办法来解决音频标签化的问题,那就跟其它问题的解决一样,需要考虑训练的模型,以及训练的样本。
(一)训练样本
这里的训练样本就是音频特征的数据集合。
音频特征有很多,比如频率、节拍、mfcc、过零率、短时能量、响度等等,其中的mfcc,是标签化的有效特征。那如何得到mfcc特征的数据集,是解决样本问题的关键。对于mfcc的概念,以及提取mfcc的办法,小程之前有介绍过,这里不再细说,读者可以关注“广州小程”微信公众号,并在相应的菜单项中查阅。
以下讲的音频特征都包括mfcc特征(也可以包括其它特征)。
为了得到音频特征的数据集(即训练样本),这里介绍两个办法,一个是自己找音频文件再提取出音频特征,另一个是使用google的audioset,这两个办法可以同时使用。当然,还有其它数据集可以使用,这个后续再介绍。
如果是自己找音频文件,则需要考虑找哪些音频文件。比如根据需要覆盖的种类,找一批有这个种类的音频文件,比如想提取“钢琴”的特征,就需要找一批钢琴曲(甚至对各个文件进行裁剪,剪切出有钢琴的片段)。根据机器学习的模型,选择是否需要同时叠加其它种类的特征。
在拿到音频文件后,可以使用VGGish模型来提取音频特征。大体的思路是,先把音频文件转换成mfcc图片,这时问题就变成了图片识别,跟音频已经没有关系,然后,图片需要进行切片,以960ms为一个切片,一个切片包括96个图片帧,一帧10ms,不重叠。每一帧都包括了64个mel频带。经过这个切片的处理后,就得到了音频特征的数据集。当然,对于96*64的切片,还可以用VGGish进一步处理,演变成适合自己模型的特征格式。
对应于VGG模型,有一个开源项目,地址是:
https://github.com/tensorflow/models/tree/master/research/audioset
对于音频特征的提取,除了VGG,还有其它的项目或模型也可以做到,这个小程另找机会来介绍。
另一个办法,是使用google的audioset。注意,google的audioset 是音频特征而非音频文件。
audioset是google在2017年开放的大规模的人工标签的音频数据集,包括人、动物、环境音、乐器与音乐流派等音频特征,一共有632个音频分类,超200万个样本(支持扩充),这些样本来源于YouTube的视频,当然经过了人工编辑。google这样描述这些样本分类,参考这个截图:
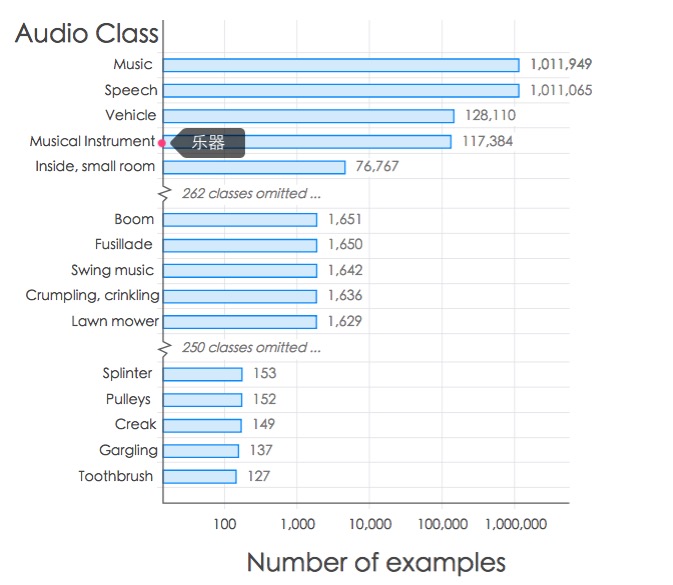
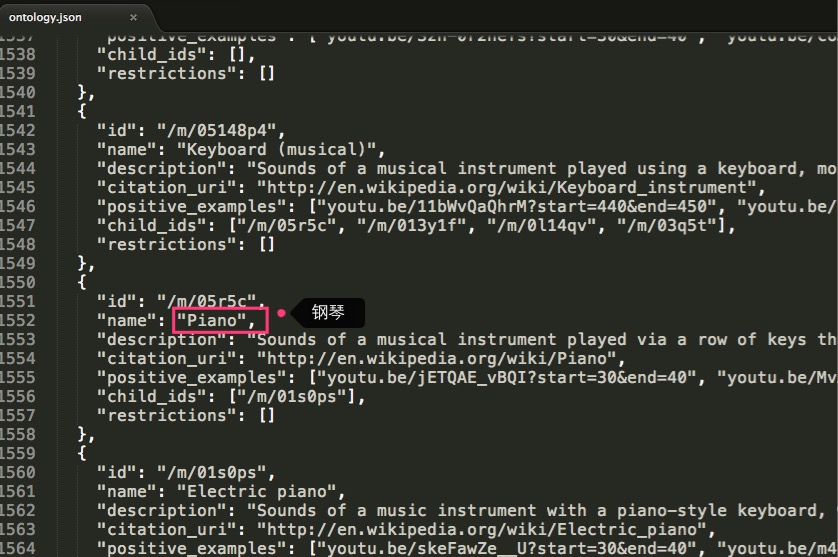
那具体有哪些分类标签呢,可参照这个文档的说明:https://github.com/audioset/ontology/blob/master/ontology.json,比如其中部分内容:
audioset的首页:
https://research.google.com/audioset/index.html
audioset的下载页面:
https://research.google.com/audioset/download.html
audioset数据集,包括两部分内容,一个是特征文件(超2G),这样下载:
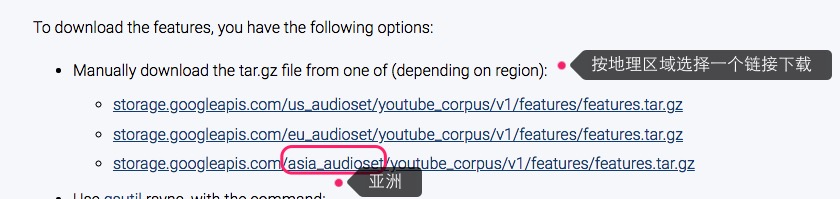
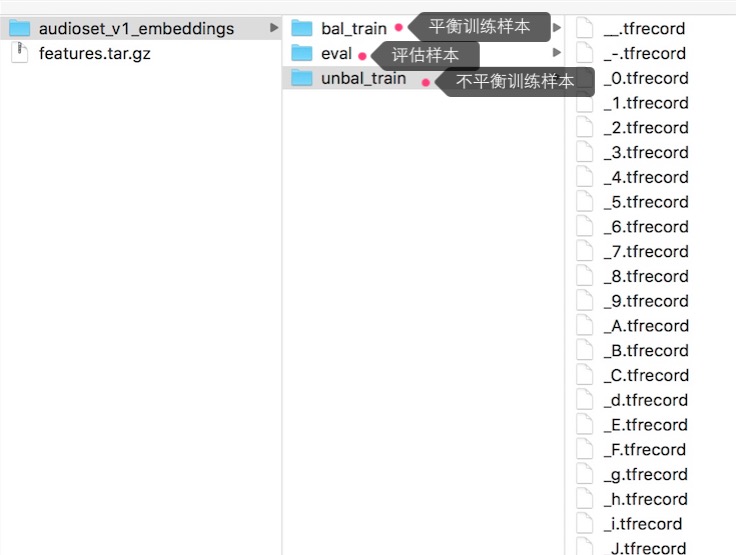
下载后的特征文件,是这个样子的(都是record file):
audioset的音频特征,是通过VGG模型生成的,是128维的特征值(是上面提到的96*64的向量的进一步的处理)。
audioset的另一部分内容,是样本的描述文件,内容包括每个样本对应的视频ID、起始与结束时间、标签ID(若干个),共有三个描述文件,如下面的截图说明:
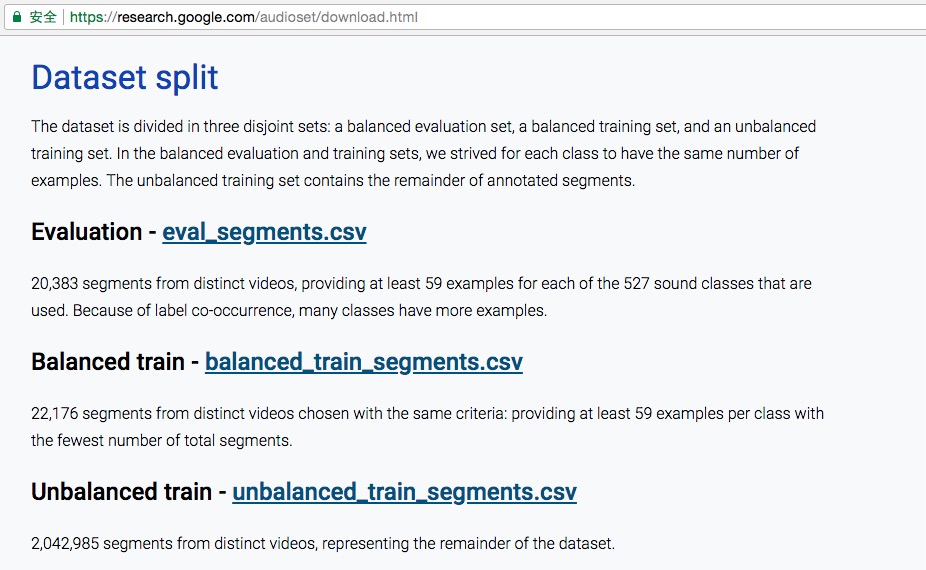
那描述文件中的标签ID是怎么关联到具体的含义的呢?下面的截图能说明其中的关联:
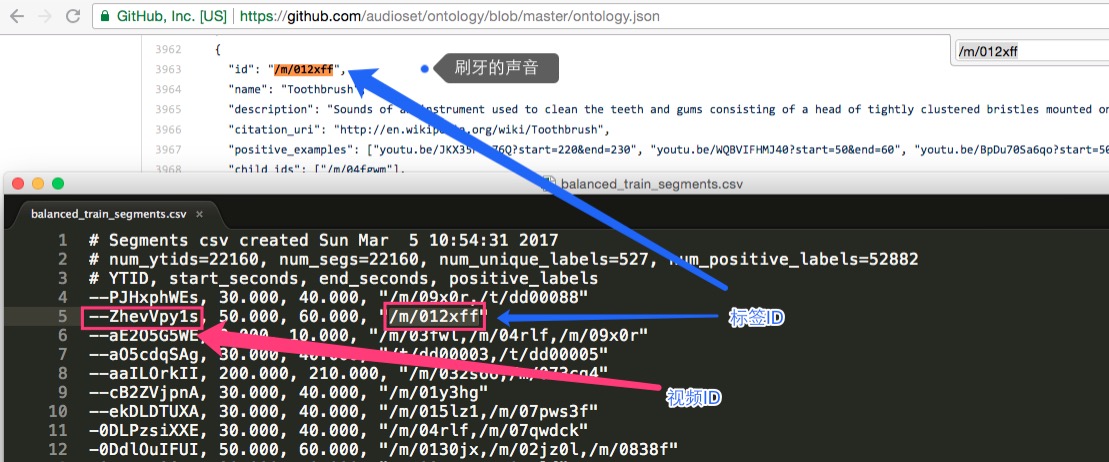
图中的标签含义,就是上面提到的“标签文档”,即:
https://github.com/audioset/ontology/blob/master/ontology.json
以上,介绍了如何获取音频特征数据集的问题,接下来,就是训练模型的事情。
(二)训练模型
对于不同的样本格式,选择不同的训练模型。
比如对于audioset,可以选择YouTube-8M训练模型,对应的开源的启动项目是:
https://github.com/google/youtube-8m
这个youtube-8m项目,训练样本可以包括audioset跟youtube-8m的数据集。而对于自定义的样本格式,就需要在开源项目的基础上自行修改。youtube-8m基于tersorflow,而自行修改的项目一般也是基于tensorflow或更抽象的tflearn。
在训练模型与训练样本准备好后,就可以开始训练的工作,训练的过程会产生系列的checkpoint,也就是一系列的预测模型,这时应该用测试样本就行检测,寻找到最佳的预测模型,这个预测模型就是最终实用的机器。
机器学习的实现过程,包括特征提取、数据集生成、训练模型生成与调整、分类样本的收集,等等,涉及到很多处理细节,这里不作展开了。
总结一下,本文简单介绍了音频标签化的实现,包括训练样本的准备与训练模型的确定这两部分的内容,这里提供了一个实现的思路,但未提及更多相关细节的处理。
音频标签化1:audioset与训练模型 | 音频特征样本的更多相关文章
- 音频标签化2:youtube-8m项目的训练、评估与测试
之前小程介绍了使用机器学习的办法来解决"音频标签化"的问题,并且提到了训练样本audioset跟youtube-8m的dataset,而训练模型上也提到了youtube-8m的模型 ...
- 音频标签化3:igor-8m项目的训练、评估与测试
上一节介绍了youtube-8m项目,这个项目以youtube-8m dataset(简称8m-dataset)样本集为基础,进行训练.评估与测试.youtube-8m设计用于视频特征样本,但实际也适 ...
- HTML5之Audio音频标签学习
HTML5中的新元素标签 src:音频文件路径. autobuffer:设置是否在页面加载时自动缓冲音频. autoplay:设置音频是否自动播放. loop:设置音频是否要循环播放. control ...
- H5 音频标签自定义样式修改以及添加播放控制事件
说明: 需求要求这个音频标签首先要是可适配移动端浏览器的,音频样式就是参考微信做的. 最终效果如下: 具体实现 思路: H5 的 <audio> 标签是由浏览器负责实现默认样式的.所以不同 ...
- Html5中 视频 音频标签 进度条问题
最近项目中使用Html5的video和audio标签来在线播放视频和音频文件,但是遇到个奇葩的问题,页面上播放之后进度条无效, 查看w3c之后发现html代码并没有什么不同,之后猜想如果用静态的htm ...
- HTML5视音频标签参考
本文将介绍HTML5中的视音频标签和对应的DOM对象.是相关资料的中文化版本,可以作为编写相关应用的简易中文参考手册. 一些约定 所有浏览器:指支持HTML5的常见桌面浏览器,包括IE9+.Firef ...
- H5 <audio> 音频标签自定义样式修改以及添加播放控制事件
H5 <audio> 音频标签自定义样式修改以及添加播放控制事件 Dandelion_drq 关注 2017.08.28 14:48* 字数 331 阅读 2902评论 3喜欢 3 说明: ...
- HTML5新增的音频标签、视频标签
我们所说的H5就是我们所说的HTML5中新增的语言标准 一.音频标签 在HTML5当中有一个叫做audio的标签,可以直接引入一段音频资源放到我们的网页当中 格式: <audio autopla ...
- IIS 配置 FTP 网站 H5 音频标签自定义样式修改以及添加播放控制事件
IIS 配置 FTP 网站 在 服务器管理器 的 Web服务器IIS 上安装 FTP 服务 在 IIS管理器 添加FTP网站 配置防火墙规则 说明:服务器环境是Windows Server 200 ...
随机推荐
- 为什么Firefox在SSH上这么慢?
为什么Firefox在SSH上这么慢? Modified on: Fri, 13 Jul 2018 18:37:30 +0800 我尝试使用 通过SSH启动Firefox ssh -X user@ho ...
- 教你轻松快速学会用Calibre TXT转MOBI
教你轻松快速学会TXT转为有目录的MOBI###授人以渔,lllll5500制作### 需使用软件按先后顺序如下:一.排版助手 官网http://www.gidot.net/typesetter/二. ...
- 在JSP页面获取集合的长度
在jsp页面上经常遇到得到集合长度.字符长度.字符切取等应用需,在2.0以前这种需是许多程序员对JSTL及为不满意的地方之一.为此在2.0 中添加了functions标签,其提供对以上需求的支持. 使 ...
- Alpha 冲刺 (5/10)
队名 火箭少男100 组长博客 林燊大哥 作业博客 Alpha 冲鸭鸭鸭鸭! 成员冲刺阶段情况 林燊(组长) 过去两天完成了哪些任务 协调各成员之间的工作 协助前后端接口的开发 测试项目运行的服务器环 ...
- selenium之生成html测试报告--testng.xsl
自制版制作步骤: 1.首先下载一个文件名为testng.xslt-1.1.zip testng.xslt-1.1我在印象笔记里面备份了一份 打开testng.xslt中lib文件夹,找到saxon-8 ...
- LOJ-10108(欧拉回路+并查集)一个图至少用几笔画成
题目链接:传送门 思路: 用并查集统计出每个区块奇数个节点的个数x,每个区块对笔画的贡献是max(x/2,1): 然后每个区块求和即可. #include<iostream> #inclu ...
- Win7 VS2015编译wxWidgets-3.1.0
下载 https://www.wxwidgets.org/downloads/ 打开SLN工程 D:\CPPLibs\wxWidgets-3.1.0\build\msw\wx_vc14.sln 编译 ...
- 用Rider写一个有IOC容器Autofac的.net core的程序
一:Autofac是一个和Java里的Spring IOC容器一样的东西,不过它确实没有Spring里的那么方便,主要是在于它没有提供足够的Api和扫描方式等等,不过优点是它比Spring要快很多,而 ...
- 【repost】H5总结
1.新增的语义化标签: <nav>: 导航 <header>: 页眉 <footer>: 页脚 <section>:区块 <article> ...
- MySQL—函数大全
一.数学函数: #ABS 绝对值函数 ) ; #BIN 返回二进制,OCT()八进制,hex十六进制 ); #ceiling 天花板整数,也就是大于x的整数 select CEILING(-13.5) ...