图说论文《An Empirical Evaluation of In-Memory Multi-Version Concurrency Control》
本文从《 An Empirical Evaluation of In-Memory Multi-Version Concurrency Control》摘取部分图片,来介绍 MVCC。 该文从并发控制协议,版本存储模型,垃圾回收机制,索引机制四个方面阐述了 MVCC 的现状。
更多详细内容,请查看原文。
元数据

DBMS 一般会为每个数据版本维护一个用以协调并发事务的 Tuple 数据。 Tuple 版本的 Header 一般会包含以下四个元数据字段:
- txn-id: 该字段一般作为该版本 Tuple 版本的写锁。若 txn-id 字段为 Tid, 则表示 ID 为 Tid 的事务,获取了该 Tuple 版本的写锁;当写事务处理完成后, 该字段会被置为 0。
- begin-ts 和 end-ts:标识当前该 Tuple 版本的生命周期起止时间。当改 Tuple 版本被删除时, 它的 begin-ts 会被置为 INF。
- pointer:前置/后续邻居版本的地址。
并发控制协议
并发控制协议负责协调并发事务的执行。它确定是否允许某个事务访问或变更指定的 Tuple 版本,是否允许提交某个事务的变更。

MVTO(Timestamp Order)
- read-ts:Tuple 版本中新增 read-ts 字段作为读锁。当有事务发起读取操作时,会更新该字段为
m
a
x
(
T
i
d
max(T_{id}
max(Tid, read-ts)。仅在
T
i
d
T_{id}
Tid 大于 read-ts 时,事务才能对该 Tuple 版本发起变更操作。
- READ: 当事务 T 发起对 Tuple A 的 READ 请求,DBMS 会查找
[begin-ts, end-ts]区间包含 Tid 的物理 Tuple 版本执行 READ 操作。如 Fig 2(a) 中, 事务 T 的 READ A 能操作 Ax 的条件是T
i
d
∈
[
10
,
20
]
T_{id}\in[10, 20]
Tid∈[10,20]。
- WRITE: Fig 2(a) 中,事务 T 获取了
B
x
B_{x}
Bx 的写锁且
T
i
d
T_{id}
Tid 大于
B
x
B_{x}
Bx 的 read-ts,因此该事务可以创建新的 Tuple 版本
B
x
+
1
B_{x+1}
Bx+1。
MVOCC(Optimistic Concurrency Control)
MVOCC 假定事务的冲突的概率很小,因此在读写过程中不会对 Tuple 版本加锁。它将事务分成三个阶段。
- READ 阶段/Normal Processing 阶段:事务在本阶段正常执行读写操作,并且不会阻塞在当前阶段。
- VALIDATION 阶段/Preparation 阶段:事务在这个阶段会决定是否提交或终止。
- WRITE 阶段/Postprocessing阶段:如果事务提交成功,本阶段会将原 Tuple 版本(
B
x
B_{x}
Bx)的 end-ts 设为
T
i
d
T_{id}
Tid ,将新创建的Tuple版本(
B
x
+
1
B_{x+1}
Bx+1) 的 begin-ts 和 end-ts 分别设为
T
i
d
T_{id}
Tid 和
I
N
F
INF
INF.

MV2PL(Two-phase Locking)
Tuple 的写锁就是它的 txn-id 字段, 为了增加读锁功能,DBMS 需要为 Tuple 增加 read-cnt 字段作为读锁,该字段用于记录正在读取改 Tuple 的事务数。
- READ 操作: Fig 2 中,对于 Tuple A 进行读操作, DBMS 会通过对比事务的
T
i
d
T_{id}
Tid 和元组的 begin-ts 字段来搜索一个可见的版本。如果它找到一个有效的版本且该 Tuple 的 txn-id 字段等于零(没有被其他事务持有写锁),DBMS就会增加该 Tuple 的 read-cnt 字段(持有读锁)。
- WRITE操作:Fig 2 中,仅在
B
x
B_{x}
Bx 的 read-cnt 和 txn-id 都为零(读写锁都未被其他事务持有)的情况下,才可以对其执行更新操作。当一个事务提交时,会被分配一个唯一时间戳(
T
c
o
m
m
i
t
T_{commit}
Tcommit),用以更新该事务创建的 Tuple 版本的 begin-ts 字段。最后释放该事务的所有锁。
Serialization Certifier
通过维护一个序列化图来感知和处理可能存在事务冲突的场景。
版本存储模型
DBMS 的版本存储模型确定系统如何存储这些版本以及每个版本包含哪些信息。
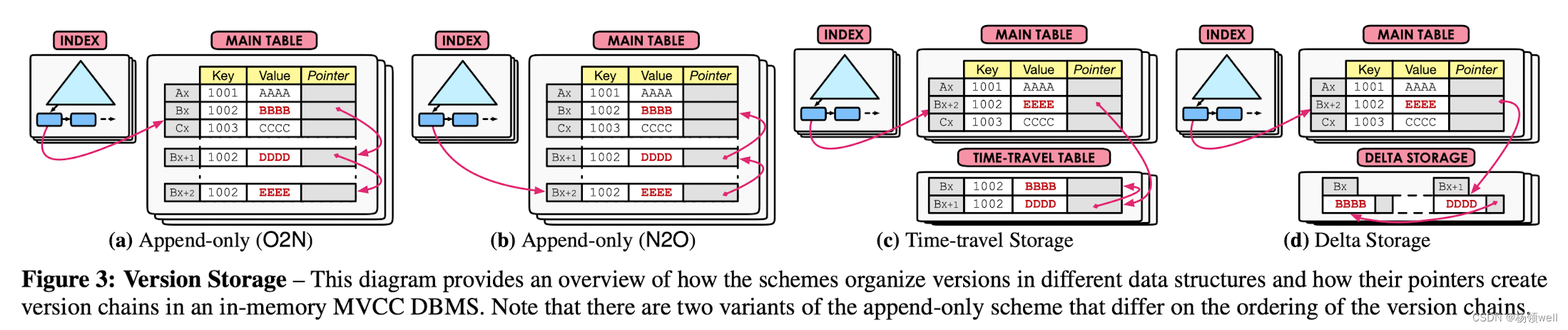
Append-only Storage
在 Append-only Storage 模型下, 所有的 Tuple 版本都存储在相同存储空间。更新一个现有的 Tuple,DBMS 会先从表中获取一个空槽作为新的Tuple 版本。然后, 将当前版本的内容复制到新版本。最后,在新分配的版本槽中应用对 Tuple 的修改。
根据不同业务场景, Append-only Storage 一般有两种维护 Tuple 版本的方式:
- Oldest-to-Newest (O2N):如图 Fig 3(a), Tuple 链的 HEAD是最旧的 Tuple 版本。这么做的好处在于不必在每次 Tuple 更新时,同步更新索引指向 Tuple 链表的指针。但缺点在于每次查询操作都需要遍历整个链表读取链尾最新 Tuple 版本的数据。
- Newest-to-Oldest (N2O):如图 Fig 3(b), Tuple 链的 HEAD是最新的 Tuple 版本。在大部分读取最新 Tuple 版本的事务,DBMS 不必遍历整个 Tuple 链表。但缺点是每次 Tuple 更新操作,都需要同步更新索引(包括主键索引和非主键索引)指针指向新的 Tuple 版本。
Time-Travel Storage
如图 Fig 3( c)。 在 Time-Travel Storage 模型下, DBMS 只将 Tuple 的 master 版本保存在 main table 中,其他同 Tuple 的更多的版本则保存在独立的 time-travel table。(main table 中保存的 master 版本可以是 Newest 版本,也可以是 Oldest 版本)。
Delta Storage
如图 Fig3(d) 。在 Delta Storage 模型下, DBMS 只将 Tuple 的 master 版本保存在 main table 中,并在独立的 delta 存储中保存一些列的 delta 版本。
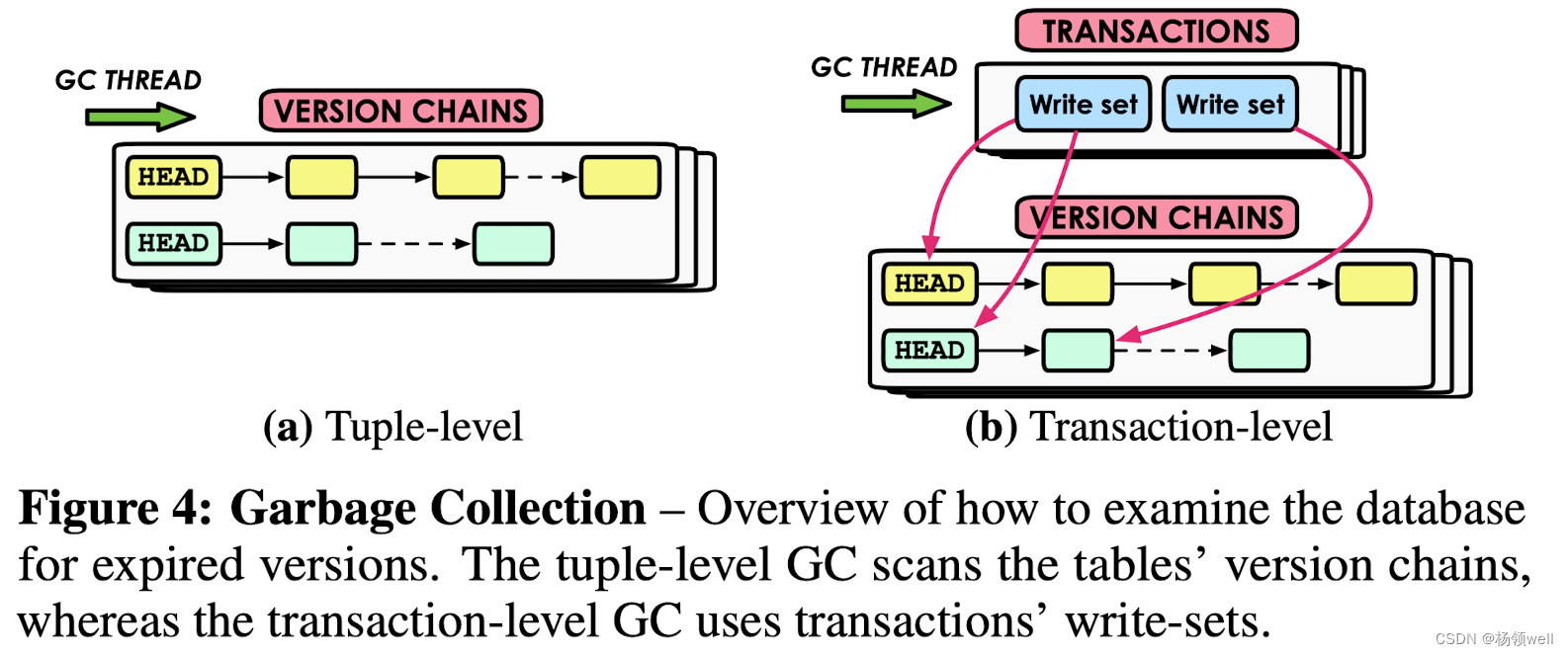
垃圾回收机制
GC 流程分为三步:
- 检测过期版本。DBMS 任务认为所有 active 事务不可见的版本和所有无效的版本(即由中止的事务创建的版本)是过期的版本。
- 从索引和相关的 Tuple 版本链上 unlink 过期版本。
- 回收存储空间。
如 Fig4,MVCC 有两种常见的 GC 方式: Tuple-level 的垃圾回收和 Transaction-level 的垃圾回收。
索引机制
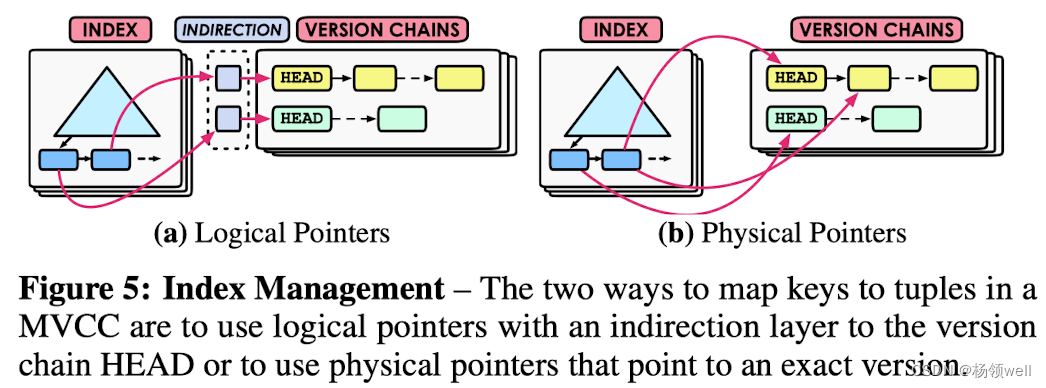
- Logical Pointer: DBMS 增加一个中间层(indirection),将一个 Tuple 的标识符映射到其版本链的 HEAD。这就避免当一个 Tuple 被修改时,必须更新所有索引指向一个新的物理位置的问题(即使索引的属性没有被改变)。
- Physical Pointer:DBMS 在索引条目中存储了 Tuple 版本的物理地址。这种方法只适用于 append-only 存储(因为在这种方式下,DBMS 把版本存储在同一个表中,因此所有的索引都可以指向它们。)
图说论文《An Empirical Evaluation of In-Memory Multi-Version Concurrency Control》的更多相关文章
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 【RS】Deep Learning based Recommender System: A Survey and New Perspectives - 基于深度学习的推荐系统:调查与新视角
[论文标题]Deep Learning based Recommender System: A Survey and New Perspectives ( ACM Computing Surveys ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- 论文笔记: Matrix Factorization Techniques For Recommender Systems
Recommender system strategies 通过例子简单介绍了一下 collaborative filtering 以及latent model,这两个方法在之前的博客里面介绍过,不累 ...
- 【万字长文】使用 LSM Tree 思想实现一个 KV 数据库
目录 设计思路 何为 LSM-Treee 参考资料 整体结构 内存表 WAL SSTable 的结构 SSTable 元素和索引的结构 SSTable Tree 内存中的 SSTable 数据查找过程 ...
- 浅析Hadoop文件格式
Hadoop 作为MR 的开源实现,一直以动态运行解析文件格式并获得比MPP数据库快上几倍的装载速度为优势.不过,MPP数据库社区也一直批评Hadoop由于文件格式并非为特定目的而建,因此序列化和反序 ...
- hadoop 原理: 浅析Hadoop文件格式
Hadoop 作为MR 的开源实现,一直以动态运行解析文件格式并获得比MPP数据库快上几倍的装载速度为优势.不过,MPP数据库社区也一直批评Hadoop由于文件格式并非 为特定目的而建,因此序列化和反 ...
- 《Object Storage on CRAQ: High-throughput chain replication for read-mostly workloads》论文总结
CRAQ 论文总结 说明:本文为论文 <Object Storage on CRAQ: High-throughput chain replication for read-mostly wor ...
- PayPal高级工程总监:读完这100篇论文 就能成大数据高手(附论文下载)
100 open source Big Data architecture papers for data professionals. 读完这100篇论文 就能成大数据高手 作者 白宁超 2016年 ...
- 近年Recsys论文
2015年~2017年SIGIR,SIGKDD,ICML三大会议的Recsys论文: [转载请注明出处:https://www.cnblogs.com/shenxiaolin/p/8321722.ht ...
随机推荐
- apt-mirror 制作麒麟桌面版内网源
apt-mirror 制作麒麟桌面版内网源 一.修改apt软件安装源 1.修改source.list安装源 vi /etc/apt/sources.list 添加: deb http://archiv ...
- 关于windows7打不开hlp文件的解决方法
前言 其实也不是打不开,而是打开后是这样的. 也就是相当于打不开. 解决方案 安装对应架构版本补丁,重启电脑即可. 下载地址 包含64位和32位. 有能力的还望下载这个 下载地址 给我留点积分,感谢!
- 10分钟看懂Docker和K8S,docker k8s 区别
10分钟看懂Docker和K8S,docker k8s 区别 2010年,几个搞IT的年轻人,在美国旧金山成立了一家名叫"dotCloud"的公司. 这家公司主要提供基于PaaS的 ...
- 有状态软件如何在 k8s 上快速扩容甚至自动扩容
概述 在传统的虚机/物理机环境里, 如果我们想要对一个有状态应用扩容, 我们需要做哪些步骤? 申请虚机/物理机 安装依赖 下载安装包 按规范配置主机名, hosts 配置网络: 包括域名, DNS, ...
- 个人电脑公网IPv6配置
一.前言 自己当时以低价买的阿里ECS云服务器马上要过期了,对于搭建个人博客.NAS这样服务器的需求购买ECS服务器成本太高了,刚好家里有台小型的桌面式笔记本,考虑用作服务器,但是公网IPv4的地址实 ...
- JavaScript:严格模式"use strict"
因为历史遗留问题,JS其实存在很多feature,以及兼容性问题: 所以JS在ES5之后,新增了一个严格模式,以区别于普通模式,用来激活新的特性,使得某些代码的执行准确无误: 如何开启严格模式? 在J ...
- ARL灯塔系统搭建
前言 ARL(Asset Reconnaissance Lighthouse)资产侦查灯塔,是一个良好的资产收集系统,旨在为渗透测试人员以及安全团队基于企业的网络安全能快速查找到指定企业资产中的脆弱点 ...
- 一、对称加密(DES加密)
一.DES简介DES是一种对称加密(Data Encryption Standard)算法.于1977年得到美国政府的正式许可,是一种用56位密钥来加密64位数据的方法.一般密码长度为8个字节,其中5 ...
- MySql树形结构(多级菜单)查询设计方案
背景 又很久没更新了,很幸运地新冠引发了严重的上呼吸道感染,大家羊过后注意休息和防护 工作中(尤其是传统项目中)经常遇到这种需要,就是树形结构的查询(多级查询),常见的场景有:组织架构(用户部门)查询 ...
- Java学习笔记:2022年1月9日(其二)
Java学习笔记:2022年1月9日(其二) 摘要:这篇笔记主要记录了1月9日学习的第四章的类的基础知识,以及访问器以及访问器于多线程的意义. 目录 Java学习笔记:2022年1月9日(其二) 1. ...