Hash冲突以及解决
哈希函数:它把一个大范围的数字哈希(转化)成一个小范围的数字,这个小范围的数对应着数组的下标。使用哈希函数向数组插入数据后,这个数组就是哈希表。
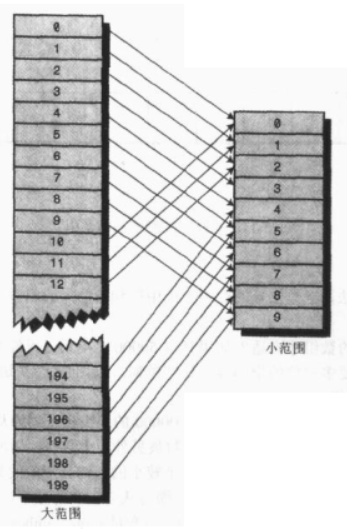
冲突
当冲突产生时,一个方法是通过系统的方法找到数组的一个空位,并把这个单词填入,而不再用哈希函数得到数组的下标,这种方法称为开放地址法。
组的每个数据项都创建一个子链表或子数组,那么数组内不直接存放单词,当产生冲突时,新的数据项直接存放到这个数组下标表示的链表中,这种方法称为链地址法。
开放地址法
线性探测: 它沿着数组下标一步一步顺序的查找空白单元。
二次探测: 思想是探测相距较远的单元,而不是和原始位置相邻的单元。
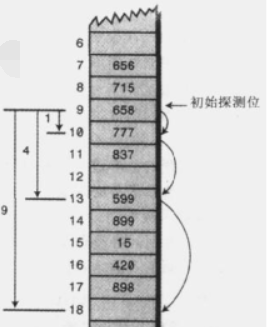
再哈希法:再来一次Hash找位置
链地址法
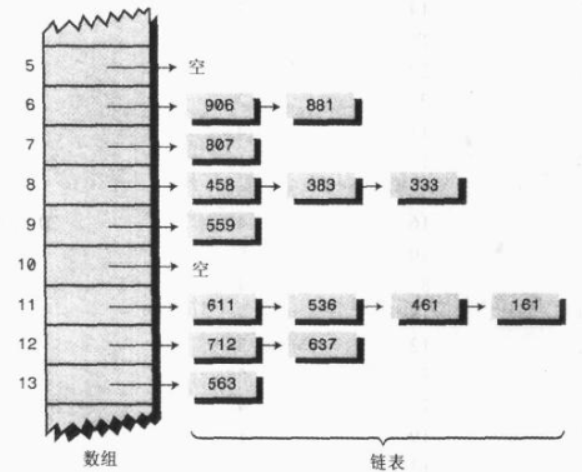
自己写“Hash”
线性探测
public class MyHashTable {
private DataItem[] hashArray; //DataItem类,表示每个数据项信息
private int arraySize;//数组的初始大小
private int itemNum;//数组实际存储了多少项数据
private DataItem nonItem;//用于删除数据项
public MyHashTable(int arraySize){
this.arraySize = arraySize;
hashArray =new DataItem[arraySize];
nonItem =new DataItem(-1);//删除的数据项下标为-1
}
//判断数组是否存储满了
public boolean isFull(){
return (itemNum == arraySize);
}
//判断数组是否为空
public boolean isEmpty(){
return (itemNum ==0);
}
//打印数组内容
public void display(){
System.out.println("Table:");
for(int j =0 ; j < arraySize ; j++){
if(hashArray[j] !=null){
System.out.print(hashArray[j].getKey() +" ");
}else{
System.out.print("** ");
}
}
}
//通过哈希函数转换得到数组下标
public int hashFunction(int key){
return key%arraySize;
}
//插入数据项
public void insert(DataItem item){
if(isFull()){
//扩展哈希表
System.out.println("哈希表已满,重新哈希化...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null && hashArray[hashVal].getKey() != -1){
++hashVal;
hashVal %= arraySize;
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* 数组有固定的大小,而且不能扩展,所以扩展哈希表只能另外创建一个更大的数组,然后把旧数组中的数据插到新的数组中。
* 但是哈希表是根据数组大小计算给定数据的位置的,所以这些数据项不能再放在新数组中和老数组相同的位置上。
* 因此不能直接拷贝,需要按顺序遍历老数组,并使用insert方法向新数组中插入每个数据项。
* 这个过程叫做重新哈希化。这是一个耗时的过程,但如果数组要进行扩展,这个过程是必须的。
*/
public void extendHashTable(){
int num = arraySize;
itemNum =0;//重新计数,因为下面要把原来的数据转移到新的扩张的数组中
arraySize *=2;//数组大小翻倍
DataItem[] oldHashArray = hashArray;
hashArray =new DataItem[arraySize];
for(int i =0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//删除数据项
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem表示空Item,其key为-1
itemNum--;
return temp;
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
//查找数据项
public DataItem find(int key){
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}
再Hash
public class HashDouble {
private DataItem[] hashArray; //DataItem类,表示每个数据项信息
private int arraySize;//数组的初始大小
private int itemNum;//数组实际存储了多少项数据
private DataItem nonItem;//用于删除数据项
public HashDouble(){
this.arraySize =13;
hashArray =new DataItem[arraySize];
nonItem =new DataItem(-1);//删除的数据项下标为-1
}
//判断数组是否存储满了
public boolean isFull(){
return (itemNum == arraySize);
}
//判断数组是否为空
public boolean isEmpty(){
return (itemNum ==0);
}
//打印数组内容
public void display(){
System.out.println("Table:");
for(int j =0 ; j < arraySize ; j++){
if(hashArray[j] !=null){
System.out.print(hashArray[j].getKey() +" ");
}else{
System.out.print("** ");
}
}
}
//通过哈希函数转换得到数组下标
public int hashFunction1(int key){
return key%arraySize;
}
public int hashFunction2(int key){
return 5 - key%5;
}
//插入数据项
public void insert(DataItem item){
if(isFull()){
//扩展哈希表
System.out.println("哈希表已满,重新哈希化...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);//用第二个哈希函数计算探测步数
while(hashArray[hashVal] !=null && hashArray[hashVal].getKey() != -1){
hashVal += stepSize;
hashVal %= arraySize;//以指定的步数向后探测
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* 数组有固定的大小,而且不能扩展,所以扩展哈希表只能另外创建一个更大的数组,然后把旧数组中的数据插到新的数组中。
* 但是哈希表是根据数组大小计算给定数据的位置的,所以这些数据项不能再放在新数组中和老数组相同的位置上。
* 因此不能直接拷贝,需要按顺序遍历老数组,并使用insert方法向新数组中插入每个数据项。
* 这个过程叫做重新哈希化。这是一个耗时的过程,但如果数组要进行扩展,这个过程是必须的。
*/
public void extendHashTable(){
int num = arraySize;
itemNum =0;//重新计数,因为下面要把原来的数据转移到新的扩张的数组中
arraySize *=2;//数组大小翻倍
DataItem[] oldHashArray = hashArray;
hashArray =new DataItem[arraySize];
for(int i =0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//删除数据项
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem表示空Item,其key为-1
itemNum--;
return temp;
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
//查找数据项
public DataItem find(int key){
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}
参考链接
https://www.cnblogs.com/ysocean/p/8032656.html
Hash冲突以及解决的更多相关文章
- hash 冲突及解决办法。
hash 冲突及解决办法. 关键字值不同的元素可能会映象到哈希表的同一地址上就会发生哈希冲突.解决办法: 1)开放定址法:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列.沿 ...
- Hash冲突的解决--暴雪的Hash算法
Hash冲突的解决--暴雪的Hash算法https://usench.iteye.com/blog/2199399https://www.bbsmax.com/A/kPzOO7a8zx/
- Cuckoo Hash——Hash冲突的解决办法
参考文献: 1.Cuckoo Filter hash算法 2.cuckoo hash 用途: Cuckoo Hash(布谷鸟散列).问了解决哈希冲突的问题而提出,利用较少的计算换取较大的空间.占用空间 ...
- Hash冲突的解决方法
虽然我们不希望发生冲突,但实际上发生冲突的可能性仍是存在的.当关键字值域远大于哈希表的长度,而且事先并不知道关键字的具体取值时.冲突就难免会发 生.另外,当关键字的实际取值大于哈希表的长度时,而且表中 ...
- 关于hash冲突的解决
分离链接法:public class SeparateChainingHashTable<AnyType>{ private static final int DEFAULT_TABLE_ ...
- hash冲突解决和javahash冲突解决
其实就是四种方法的演变 1.开放定址法 具体就是把数据的标志等的对长度取模 有三种不同的取模 线性探测再散列 给数据的标志加增量,取模 平方探测再散列 给数据的标志平方,取模 随机探测再散列 把数据的 ...
- Map之HashMap的get与put流程,及hash冲突解决方式
在java中HashMap作为一种Map的实现,在程序中我们经常会用到,在此记录下其中get与put的执行过程,以及其hash冲突的解决方式: HashMap在存储数据的时候是key-value的键值 ...
- hash冲突随笔
一:hash表 也叫散列表,以key-value的形式存储数据,就是将需要存储的关键码值通过hash函数映射到表中的位置,可加快访问速度. 二:hash冲突 如果两个相同的关键码值通过hash函数映射 ...
- 链表法解决hash冲突
/* @链表法解决hash冲突 * 大单元数组,小单元链表 */ #pragma once #include <string> using namespace std; template& ...
随机推荐
- 手写 Vue2 系列 之 patch —— diff
前言 上一篇文章 手写 Vue2 系列 之 初始渲染 中完成了原始标签.自定义组件.插槽的的初始渲染,当然其中也涉及到 v-bind.v-model.v-on 指令的原理.完成首次渲染之后,接下来就该 ...
- ArcMap操作随记(3)
1.地图四要素: 图名.图例.比例尺.指北针 2.[栅格计算器].[加权叠加]和[加权总和]的不同 [栅格计算器]的结果是浮点型小数 [加权叠加]工具,输入栅格必须为整型.若成本栅格涉及重分类,最好用 ...
- 通过Geth搭建私有以太坊网络
前言 为了进一步了解以太坊区块链网络的工作方式和运行原理,笔者通过官方软件Geth搭建了私有以太坊网络fantasynetwork,最终实现了单机和多机节点间的相互连通:首先通过VMware Work ...
- C#编程基础之字符串操作
本文来源于复习基础知识的学习笔记.自用的同时希望也能帮到其他童鞋. 什么是编程语言? 计算机可以执行的指令.这些指令成为源代码或者代码 有什么用? 以人们可读可理解的方式编写指令.人们希望计算机执行指 ...
- Failed to execute "C:\learn\C\程序练习\1.exe": Error 0: 操作成功完成。 请按任意键继续. . .问题解决
在DEV中编译运行时出现以上提示,原因是该文件被杀毒软件隔离了,认为它是病毒文件 解决办法,找到该文件进行恢复
- Prometheus由于时间不同步导致数据不显示
原文链接:Prometheus由于时间不同步导致数据不显示 问题 部署 prometheus 后,访问前端界面发现: 这是由于你windows机器与部署prometheus服务器的时间不同步导致的. ...
- [bzoj3585] Rmq Problem / mex
[bzoj3585] Rmq Problem / mex bzoj luogu 看上一篇博客吧,看完了这个也顺理成章会了( (没错这篇博客就是这么水) #include<cstdio> # ...
- 浅谈spin lock 与信号量
理解阻塞和非阻塞概念: eg: open->read->close eg: open->while(read)->close read -> data received/ ...
- url斜杠问题——重定向
path('hello',hello), path('hello/',hello), 有什么区别? 没有斜杠:只能访问hello 有斜杠:可以访问hello和hello/ 分析有斜杠的: hello- ...
- Java基础 (下)
泛型 Java 泛型了解么?什么是类型擦除?介绍一下常用的通配符? Java 泛型(generics) 是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时 ...