Hash冲突以及解决
哈希函数:它把一个大范围的数字哈希(转化)成一个小范围的数字,这个小范围的数对应着数组的下标。使用哈希函数向数组插入数据后,这个数组就是哈希表。
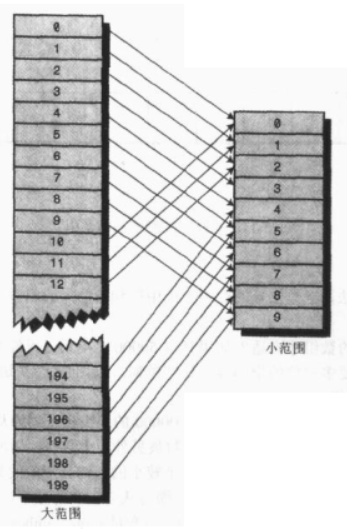
冲突
当冲突产生时,一个方法是通过系统的方法找到数组的一个空位,并把这个单词填入,而不再用哈希函数得到数组的下标,这种方法称为开放地址法。
组的每个数据项都创建一个子链表或子数组,那么数组内不直接存放单词,当产生冲突时,新的数据项直接存放到这个数组下标表示的链表中,这种方法称为链地址法。
开放地址法
线性探测: 它沿着数组下标一步一步顺序的查找空白单元。
二次探测: 思想是探测相距较远的单元,而不是和原始位置相邻的单元。
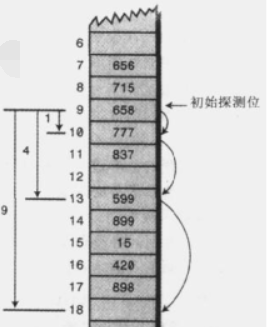
再哈希法:再来一次Hash找位置
链地址法
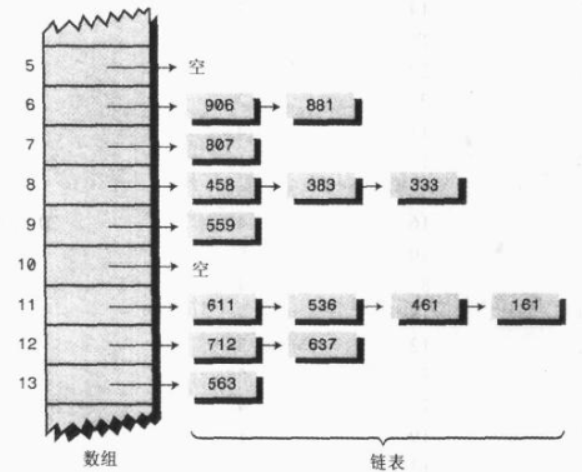
自己写“Hash”
线性探测
public class MyHashTable {
private DataItem[] hashArray; //DataItem类,表示每个数据项信息
private int arraySize;//数组的初始大小
private int itemNum;//数组实际存储了多少项数据
private DataItem nonItem;//用于删除数据项
public MyHashTable(int arraySize){
this.arraySize = arraySize;
hashArray =new DataItem[arraySize];
nonItem =new DataItem(-1);//删除的数据项下标为-1
}
//判断数组是否存储满了
public boolean isFull(){
return (itemNum == arraySize);
}
//判断数组是否为空
public boolean isEmpty(){
return (itemNum ==0);
}
//打印数组内容
public void display(){
System.out.println("Table:");
for(int j =0 ; j < arraySize ; j++){
if(hashArray[j] !=null){
System.out.print(hashArray[j].getKey() +" ");
}else{
System.out.print("** ");
}
}
}
//通过哈希函数转换得到数组下标
public int hashFunction(int key){
return key%arraySize;
}
//插入数据项
public void insert(DataItem item){
if(isFull()){
//扩展哈希表
System.out.println("哈希表已满,重新哈希化...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null && hashArray[hashVal].getKey() != -1){
++hashVal;
hashVal %= arraySize;
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* 数组有固定的大小,而且不能扩展,所以扩展哈希表只能另外创建一个更大的数组,然后把旧数组中的数据插到新的数组中。
* 但是哈希表是根据数组大小计算给定数据的位置的,所以这些数据项不能再放在新数组中和老数组相同的位置上。
* 因此不能直接拷贝,需要按顺序遍历老数组,并使用insert方法向新数组中插入每个数据项。
* 这个过程叫做重新哈希化。这是一个耗时的过程,但如果数组要进行扩展,这个过程是必须的。
*/
public void extendHashTable(){
int num = arraySize;
itemNum =0;//重新计数,因为下面要把原来的数据转移到新的扩张的数组中
arraySize *=2;//数组大小翻倍
DataItem[] oldHashArray = hashArray;
hashArray =new DataItem[arraySize];
for(int i =0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//删除数据项
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem表示空Item,其key为-1
itemNum--;
return temp;
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
//查找数据项
public DataItem find(int key){
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}
再Hash
public class HashDouble {
private DataItem[] hashArray; //DataItem类,表示每个数据项信息
private int arraySize;//数组的初始大小
private int itemNum;//数组实际存储了多少项数据
private DataItem nonItem;//用于删除数据项
public HashDouble(){
this.arraySize =13;
hashArray =new DataItem[arraySize];
nonItem =new DataItem(-1);//删除的数据项下标为-1
}
//判断数组是否存储满了
public boolean isFull(){
return (itemNum == arraySize);
}
//判断数组是否为空
public boolean isEmpty(){
return (itemNum ==0);
}
//打印数组内容
public void display(){
System.out.println("Table:");
for(int j =0 ; j < arraySize ; j++){
if(hashArray[j] !=null){
System.out.print(hashArray[j].getKey() +" ");
}else{
System.out.print("** ");
}
}
}
//通过哈希函数转换得到数组下标
public int hashFunction1(int key){
return key%arraySize;
}
public int hashFunction2(int key){
return 5 - key%5;
}
//插入数据项
public void insert(DataItem item){
if(isFull()){
//扩展哈希表
System.out.println("哈希表已满,重新哈希化...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);//用第二个哈希函数计算探测步数
while(hashArray[hashVal] !=null && hashArray[hashVal].getKey() != -1){
hashVal += stepSize;
hashVal %= arraySize;//以指定的步数向后探测
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* 数组有固定的大小,而且不能扩展,所以扩展哈希表只能另外创建一个更大的数组,然后把旧数组中的数据插到新的数组中。
* 但是哈希表是根据数组大小计算给定数据的位置的,所以这些数据项不能再放在新数组中和老数组相同的位置上。
* 因此不能直接拷贝,需要按顺序遍历老数组,并使用insert方法向新数组中插入每个数据项。
* 这个过程叫做重新哈希化。这是一个耗时的过程,但如果数组要进行扩展,这个过程是必须的。
*/
public void extendHashTable(){
int num = arraySize;
itemNum =0;//重新计数,因为下面要把原来的数据转移到新的扩张的数组中
arraySize *=2;//数组大小翻倍
DataItem[] oldHashArray = hashArray;
hashArray =new DataItem[arraySize];
for(int i =0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//删除数据项
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem表示空Item,其key为-1
itemNum--;
return temp;
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
//查找数据项
public DataItem find(int key){
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}
参考链接
https://www.cnblogs.com/ysocean/p/8032656.html
Hash冲突以及解决的更多相关文章
- hash 冲突及解决办法。
hash 冲突及解决办法. 关键字值不同的元素可能会映象到哈希表的同一地址上就会发生哈希冲突.解决办法: 1)开放定址法:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列.沿 ...
- Hash冲突的解决--暴雪的Hash算法
Hash冲突的解决--暴雪的Hash算法https://usench.iteye.com/blog/2199399https://www.bbsmax.com/A/kPzOO7a8zx/
- Cuckoo Hash——Hash冲突的解决办法
参考文献: 1.Cuckoo Filter hash算法 2.cuckoo hash 用途: Cuckoo Hash(布谷鸟散列).问了解决哈希冲突的问题而提出,利用较少的计算换取较大的空间.占用空间 ...
- Hash冲突的解决方法
虽然我们不希望发生冲突,但实际上发生冲突的可能性仍是存在的.当关键字值域远大于哈希表的长度,而且事先并不知道关键字的具体取值时.冲突就难免会发 生.另外,当关键字的实际取值大于哈希表的长度时,而且表中 ...
- 关于hash冲突的解决
分离链接法:public class SeparateChainingHashTable<AnyType>{ private static final int DEFAULT_TABLE_ ...
- hash冲突解决和javahash冲突解决
其实就是四种方法的演变 1.开放定址法 具体就是把数据的标志等的对长度取模 有三种不同的取模 线性探测再散列 给数据的标志加增量,取模 平方探测再散列 给数据的标志平方,取模 随机探测再散列 把数据的 ...
- Map之HashMap的get与put流程,及hash冲突解决方式
在java中HashMap作为一种Map的实现,在程序中我们经常会用到,在此记录下其中get与put的执行过程,以及其hash冲突的解决方式: HashMap在存储数据的时候是key-value的键值 ...
- hash冲突随笔
一:hash表 也叫散列表,以key-value的形式存储数据,就是将需要存储的关键码值通过hash函数映射到表中的位置,可加快访问速度. 二:hash冲突 如果两个相同的关键码值通过hash函数映射 ...
- 链表法解决hash冲突
/* @链表法解决hash冲突 * 大单元数组,小单元链表 */ #pragma once #include <string> using namespace std; template& ...
随机推荐
- MM32F0020 UART1空闲中断接收
目录: 1.MM32F0020简介 2.初始化MM32F0020 UART1空闲中断和NVIC中断 3.编写MM32F0020 UART1中断接收和空闲中断函数 4.编写MM32F0020 UART1 ...
- 互联网前沿技术——01 找不到模块“lodash”
检查安装 node --version 修改 安装:npm install 启动:grunt server 如果报错: 找不到模块"lodash" https://www.soin ...
- 详解 Java 内部类
内部类在 Java 里面算是非常常见的一个功能了,在日常开发中我们肯定多多少少都用过,这里总结一下关于 Java 中内部类的相关知识点和一些使用内部类时需要注意的点. 从种类上说,内部类可以分为四类: ...
- 基于EMR离线数据分析-反馈有礼
"云上漫步"第三期-反馈有礼 参与体验产品,提交反馈,就有机会获得定制背包,T恤,超萌虎年鼠标垫,以及5到100元阿里云通用代金券~ 反馈地址: https://developer ...
- file_put_contents利用技巧(php://filter协议)
Round 1 <?php $content = '<?php exit; ?>'; $content .= $_POST['txt']; file_put_contents($_P ...
- 用Markdown写Html和.md也就图一乐,真骚操作还得用来做PPT
前言 和这篇文章一样,我就是用Markdown写的.相信各位平时也就用Markdown写写文档,做做笔记,转成XHtml.Html等,今天教大伙一招骚操作:用Markdown写PPT. 绝大多数朋友做 ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 项目可以怎么规范Git commit ?
通常情况下,commit message应该清晰明了,说明本次提交的目的,具体做了什么操作.但是在日常开发中,大家的commit message都比较随意,中英文混合使用的情况有时候很常见,这就导致后 ...
- 羽夏看Win系统内核—— VT 入门番外篇
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新. 如有好的建议,欢迎反馈.码字不易, ...
- HTTP发展史,HTTP1.1与HTTP2.0的区别
前言 我们知道HTTP是浏览器中最重要且使用最多的协议,它不仅是浏览器与服务端的通信语言,更是互联网的基石.随着浏览器的不断更新迭代,HTTP为了适应技术的更新也在不断进化,学习HTTP的最佳途径就是 ...