RabbitMQ入门(三)订阅模式
在之前的文章RabbitMQ入门(二)工作队列中,我们创建了一个工作队列。工作队列背后的假设是每一项任务都被准确地传送至一个worker。在本文中,我们将会做一些不同的事情——我们将会把一个消息发送至许多消费者中。这种模式被称为订阅模式(publish/subscribe)。
为了解释这种模式,我们将会构建一个简单的日志系统。它包含两个程序——第一个将会产生消息,第二个将会接收并输出这些消息。
在我们的日志系统中,每一个正在运行的接收程序都会收到消息。在这种方式下,我们可以运行一个接收程序来接收并将日志保存至硬盘;同时,我们还能运行另一个接收程序,在屏幕上观察到日志的输出。
特别地,发送的这些消息都会被广播到所有的接收程序。
交换(Exchanges)
在之前的文章中,我们向队列发送消息,从队列中接受消息。现在是时候介绍RabbitMQ中的全部消息转发模式。
让我们快速地浏览下之前文章中讲了些什么:
- 一个生产者(Producer)是用于产生消息的用户应用程序;
- 一个队列(Queue)是缓存区,用于储存消息;
- 一个消费者(Consumer)是用于接收消息的用户应用程序。
RabbitMQ中消息传输模式的核心思想是生产者绝不会直接向队列发送任何消息。实际上,通常情况下生产者甚至都不会知道消息是否会被发送至队列。
生产者会将消息发送至交换(exchange)。交换并不复杂。一方面它从生产者中接受消息,另一方面将消息推送至队列。交换必须知道,当它接受一个消息时,它该怎么做。是否这个消息会附加至一个特殊的队列?是否它会附加至许多队列?或者它会被丢弃。这个规则用交换类型(exchange type)来定义。
有一些可用的交换类型:直接分发(direct),通配分发(topic),headers和复制分发(fanout)。我们将会集中讲最后一个——fanout。我们创建一个交换,类型为fanout,并取名为logs:
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
fanout交换非常简单。顾名思义,它会将所有它知道的接收队列的消息都广播出去。而这也正是我们的日志系统所需要的。
现在,我们可以发布已经命名好的队列了:
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
临时队列
你也许还记得在之前的文章中,我们需要给队列取名。但是呢,给队列命名太麻烦了——我们需要将workers指定到同一个队列。当你需要在生产者和消费者之间共享队列的时候,给队列命名又是很重要的。
这种情形并不适合我们的日志系统。我们想要监听所有的消息,而不是部分消息。同时,我们仅对当前的流动消息感兴趣,而不是之前的消息。为了解决这个问题,我们需要做两件事情。
首先,无论何时我们连接到RabbitMQ,我们需要一个新的空队列。为此,我们创建一个随机命名的队列,或者更好的是,让RabbitMQ Server来给我们创建一个随机命名的队列。因此,我们可以利用queue_declare命令,设置queuq参数为空:
result = channel.queue_declare(queue='')
此时,result.method.queue会包含一个随机命名的队列,比如说,它会和amq.gen-JzTY20BRgKO-HjmUJj0wLg类似。
其次,一旦消息者的连接关闭,我们需要删除队列。这可以用exclusive参数搞定:
result = channel.queue_declare(queue='', exclusive=True)
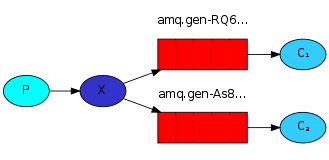
绑定(Bindings)

我们已经创建了一个fanout 交换和队列。现在我们需要告诉交换,将消息发送至队列。交换与队列之间的关系叫做绑定(Bindings)。
channel.queue_bind(exchange='logs',
queue=result.method.queue)
从现在开始,logs交换将会在我们的队列后追加消息。
代码
生产者代码(emit_log.py):
# -*- coding: utf-8 -*-
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs', routing_key='', body=message)
print(" [x] Sent %r" % message)
connection.close()
消费者代码(receive_log.py):
# -*- coding: utf-8 -*-
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout')
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs', queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
开启四个终端,其中一个用于保存日志:
python3 receive_log.py > logs_from_rabbit.log
另一个用于观察日志输出:
python3 receive_log.py
日志产生:
python3 emit_log.py
监听绑定:
sudo rabbitmqctl list_bindings
运行截图如下:

本次分享到此结束,感谢大家阅读~
RabbitMQ入门(三)订阅模式的更多相关文章
- RabbitMQ入门-消息订阅模式
消息派发 上篇<RabbitMQ入门-消息派发那些事儿>发布之后,收了不少反馈,其中问的最多的还是有关消息确认以及超时等场景的处理. 楼主,有遇到消费者后台进程不在,但consumer连接 ...
- RabbitMQ入门-发布订阅模式
兔子的Publish/Subscribe是这样的: 有个生产者P,X代表交换机,交换机绑定队列,消费者从队列中取得消息.每次有消息,先发到交换机中,然后由交换机负责发送到它已知的队列中. 生产者代码: ...
- Rabbitmq交换机三种模式介绍
1.topic 将路由键和某模式进行匹配.此时队列需要绑定要一个模式上.符号“#”匹配一个或多个词,符号“*”匹配不多不少一个词.因此“abc.#”能够匹配到“abc.def.ghi”,但是“abc. ...
- RabbitMQ的发布订阅模式(Publish/Subscribe)
一.发布/订阅(Publish/Subscribe)模式 发布订阅是我们经常会用到的一种模式,生产者生产消息后,所有订阅者都可以收到.RabbitMQ的发布/订阅模型图如下: 1.该模式下生产者并不是 ...
- RabbitMQ简单应用の订阅模式
订阅模式 公众号-->订阅之后才会收到相应的文章. 解读: 1.一个生产者,多个消费者 2.每个消费者都有自己的队列 3.生产者没有将消息直接发送到队列里,而是发送给了交换机(转发器)excha ...
- RabbitMQ入门-竞争消费者模式
上一篇讲了个 哈喽World,现在来看看如果存在多个消费者的情况. 生产者: package com.example.demo; import com.rabbitmq.client.Channel; ...
- Java设计模式从精通到入门三 策略模式
介绍 我尽量用最少的语言解释总结: Java23种设计模式之一,属于行为型模式.一个类的行为或者算法可以在运行时更改,策略对象改变context对象执行算法. 应用实例: 以周瑜赔了夫人又折兵的例 ...
- RabbitMQ入门到进阶(Spring整合RabbitMQ&SpringBoot整合RabbitMQ)
1.MQ简介 MQ 全称为 Message Queue,是在消息的传输过程中保存消息的容器.多用于分布式系统 之间进行通信. 2.为什么要用 MQ 1.流量消峰 没使用MQ 使用了MQ 2.应用解耦 ...
- RabbitMQ入门案例
RabbitMQ入门案例 Rabbit 模式 https://www.rabbitmq.com/getstarted.html 实现步骤 构建一个 maven工程 导入 rabbitmq的依赖 启动 ...
随机推荐
- CSS 手札记
Display:Block/Flex 宽度如果不定义会尽可能的扩充外层宽度 在内容区域使用高度百分比和固定像素高度的时候外层设overflow:auto;可以把内层的高度撑开,否则外层会比内层短一截 ...
- HDU6578 2019HDU多校训练赛第一场 1001 (dp)
HDU6578 2019HDU多校训练赛第一场 1001 (dp) 传送门:http://acm.hdu.edu.cn/showproblem.php?pid=6578 题意: 你有n个空需要去填,有 ...
- schema list validator --python cerberus
工作中需要对如下json结构进行验证: "ActiveStatus" : [ { "effectiveDates" : { "effectiveFro ...
- 数据多js平均时间取固定条数展示,echarts数据多处理数据
js代码: function getfailurerate(start,end,ip) { $.ajax( { url : "report/getvirtual.action", ...
- docker常用命令(不包括run和build)
docekr 常用命令 :ls 列出容器 $ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE jdk fec5236a803b seconds ...
- windows 服务的安装、启动、状态查询、停止操作c++实现
具体的自己看看代码 粘贴复制即可使用 卸载也很简单自己查看MSDN 加上就是 #ifndef __SERVICEMANAGE_H__ #define __SERVICEMANAGE_H__ #incl ...
- $[NOIp2008]$双栈排序 栈/二分图/贪心
\(Sol\) 先考虑单栈排序,怎么样的序列可以单栈排序呢?设\(a_i\)表示位置\(i\)是哪个数.\(\exist i<j<k\),都没有\(a_k<a_i<a_j\), ...
- 【C++】几个简单课本例题
// // main.cpp // 2_1 // // Created by T.P on 2018/2/28. // Copyright © 2018年 T.P. All rights reserv ...
- .net core试水
概述 大概记录下我如何第一次使用.net core搭建一个api,由于最近.net core比较火,我也尝试着使用.net core做了一个小功能 本文主要包括 1.环境配置 2.程序编写 3.程序部 ...
- 使用阿里云 ECS 快速部署 WordPress 博客系统
今天在 阿里云 ECS上 部署了一套 Lamp 系统,建了一个WordPress的网站,把操作过程记录下来,文中所列脚本可以直接应用. 废话不多说直接开动,ECS云服务购买可以点击 阿里云ECS 云主 ...