Python之路--协程/IO多路复用
引子:
之前学习过了,线程,进程的概念,知道了在操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位.按道理来说我们已经算是把CPU的利用率提高很多了.但是我们知道无论是创建多进程还是创建多线程来解决问题,都要消耗一定的时间来创建进程,创建线程,以及管理他们之间的切换.
随着我们对于效率的最求不断提高,基于单线程来实现并发又成为一个新的课题.即只用一个主线程的情况下实现并发.这样就可以节省创建线程进程所消耗的时间.
并发的本质: 切换+保存状态
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是任务发生了阻塞,另外一种情况是该任务计算时间过长
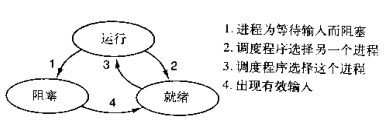
对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到io阻塞时就切换到另外一个任务去计算,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而更多的将cpu的执行权限分配给我们的线程。
协成的本质就是在单线程下,由用户自己控制一个任务遇到IO阻塞就切换另一个任务去执行,一次来提升效率.
#可以控制对个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行.
#作为1的补充;可以检测IO操作,在遇到IO操作的情况下才发生切换
协程介绍:
协程:是单线程下的并发,又称为为线程. 协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的.
协程特点:
必须在只有一个单线程里实现并发
修改共享数据不需加锁
用户程序里自己保存多个控制流的上下文栈
一个协程遇到IO操作自动切换到其他协程
Greenlet模块
安装:pip3 install greenlet
from greenlet import greenlet def eat(name):
print('%s eat 1'%name)
g2.switch('egon')
print('%s eat 2'%name)
g2.switch()
def play(name):
print('%s play 1' %name)
g1.switch
print('%s play 2' %name) g1 = greenlet(eat)
g2 = greenlet(play) g1.switch('egon')#可以在第一次switch时传入参数,以后都不需要
greenlet实现状态切换
Gevent模块
安装:pip3 install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet,它是以C扩展模块形式接入Python的轻量级线程.Greenlet全部运行在主程序操作系统进程的内部,但他们被协作式的调度.
import gevent
def eat(name):
print('%s eat 1' %name)
gevent.sleep(2)
print('%s eat 2' %name) def play(name):
print('%s play 1' %name)
gevent.sleep(1)
print('%s play 2' %name) g1=gevent.spawn(eat,'egon')
g2=gevent.spawn(play,name='egon')
g1.join()
g2.join()
#或者gevent.joinall([g1,g2])
print('主')
遇到IO主动切换
IO多路复用
IO多路复用作用:检查多个socket是否已经发生变化(是否连接成功/是否已经获取数据)(可读/可写)
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。
三种模式:
select:最多1024个socket;循环去检测。
poll:不限制监听socket个数;循环去检测(水平触发)。
epoll:不限制监听socket个数;回调方式(边缘触发)。
基于IO多路复用+socket实现并发请求:
IO多路复用
socket 非阻塞(不等待)
异步:执行完某个任务后自动调用我给它的函数
Python中开源 基于事件循环实现的异步非阻塞框架 Twisted
import socket
import requests # 方式一
ret = requests.get('https://www.baidu.com/s?wd=alex') # 方式二
client = socket.socket() # 百度创建连接: 阻塞
client.connect(('www.baidu.com',80)) # 问百度我要什么?
client.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.baidu.com\r\n\r\n') # 我等着接收百度给我的回复
chunk_list = []
while True:
chunk = client.recv(8096)
if not chunk:
break
chunk_list.append(chunk) body = b''.join(chunk_list)
print(body.decode('utf-8'))
socket发生请求
import socket
import requests # 方式一
key_list = ['alex','db','sb']
for item in key_list:
ret = requests.get('https://www.baidu.com/s?wd=%s' %item) # 方式二
def get_data(key):
# 方式二
client = socket.socket() # 百度创建连接: 阻塞
client.connect(('www.baidu.com',80)) # 问百度我要什么?
client.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.baidu.com\r\n\r\n') # 我等着接收百度给我的回复
chunk_list = []
while True:
chunk = client.recv(8096)
if not chunk:
break
chunk_list.append(chunk) body = b''.join(chunk_list)
print(body.decode('utf-8')) key_list = ['alex','db','sb']
for item in key_list:
get_data(item)
单线程解决并发
import threading key_list = ['alex','db','sb']
for item in key_list:
t = threading.Thread(target=get_data,args=(item,))
t.start()
解决并发,多线程
提高并发方案:
--多进程
--多线程
--异步非阻塞模块(Twisted) scrapy框架(单线程完成并发)
import socket
import select client1 = socket.socket()
client1.setblocking(False) # 百度创建连接: 非阻塞 try:
client1.connect(('www.baidu.com',80))
except BlockingIOError as e:
pass client2 = socket.socket()
client2.setblocking(False) # 百度创建连接: 非阻塞
try:
client2.connect(('www.sogou.com',80))
except BlockingIOError as e:
pass client3 = socket.socket()
client3.setblocking(False) # 百度创建连接: 非阻塞
try:
client3.connect(('www.oldboyedu.com',80))
except BlockingIOError as e:
pass socket_list = [client1,client2,client3]
conn_list = [client1,client2,client3] while True:
rlist,wlist,elist = select.select(socket_list,conn_list,[],0.005)
# wlist中表示已经连接成功的socket对象
for sk in wlist:
if sk == client1:
sk.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.baidu.com\r\n\r\n')
elif sk==client2:
sk.sendall(b'GET /web?query=fdf HTTP/1.0\r\nhost:www.sogou.com\r\n\r\n')
else:
sk.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.oldboyedu.com\r\n\r\n')
conn_list.remove(sk)
for sk in rlist:
chunk_list = []
while True:
try:
chunk = sk.recv(8096)
if not chunk:
break
chunk_list.append(chunk)
except BlockingIOError as e:
break
body = b''.join(chunk_list)
# print(body.decode('utf-8'))
print('------------>',body)
sk.close()
socket_list.remove(sk)
if not socket_list:
break
单线程完成并发
什么是异步非阻塞?
--非阻塞:不等待
比如创建socket对某个地址进行connect,获取接收数据recv时默认都会等待(连接成功或接收到数据),才执行后续操作.如果设置setblocking(False),以上两个过程就不在等待,到时会报BlockingIOError的错误,只要捕获即可.
--异步,通知,执行完成后自动执行回调函数或自动执行某些操作(通知)
比如做爬虫中向某个地址baidu.com发送请求,当请求执行完成之后自动执行回调函数.
什么是同步阻塞?
--阻塞:等
--同步:按照顺序逐步执行
key_list = ['alex','db','sb']
for item in key_list:
ret = requests.get('https://www.baidu.com/s?wd=%s' %item)
print(ret.text)
Python之路--协程/IO多路复用的更多相关文章
- 协程IO多路复用
协程:单线程下实现并发并发:伪并行,遇到IO就切换,单核下多个任务之间切换执行,给你的效果就是貌似你的几个程序在同时执行.提高效率任务切换 + 保存状态并行:多核cpu,真正的同时执行串行:一个任务执 ...
- day 35 协程 IO多路复用
0.基于socket发送Http请求 import socket import requests # 方式一 ret = requests.get('https://www.baidu.com/s?w ...
- python之路---协程
阅读目录 一 引子 二 协程介绍 三 Greenlet模块 四 Gevent模块 引子 之前我们学习了线程.进程的概念,了解了在操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位.按道理来 ...
- 12_进程,线程,协程,IO多路复用的区别
1.进程 1.进程可以使用计算机多核 2.进程是资源分配的单位 3.进程的创建要比线程消耗更多的资源效率很低 4.进程空间独立,数据安全性跟好操作有专门的进程间通信方式 5.一个进程可以包含多个线程, ...
- 协程 IO多路复用
-----------------------------------------------------------------试试并非受罪,问问并不吃亏.善于发问的人,知识丰富. # # ---- ...
- python线程、协程、I/O多路复用
目录: 并发多线程 协程 I/O多路复用(未完成,待续) 一.并发多线程 1.线程简述: 一条流水线的执行过程是一个线程,一条流水线必须属于一个车间,一个车间的运行过程就是一个进程(一个进程内至少一个 ...
- Python学习笔记整理总结【网络编程】【线程/进程/协程/IO多路模型/select/poll/epoll/selector】
一.socket(单链接) 1.socket:应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口.在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socke ...
- 第十一章:Python高级编程-协程和异步IO
第十一章:Python高级编程-协程和异步IO Python3高级核心技术97讲 笔记 目录 第十一章:Python高级编程-协程和异步IO 11.1 并发.并行.同步.异步.阻塞.非阻塞 11.2 ...
- Python之路,Day10 - 异步IO\数据库\队列\缓存
Python之路,Day9 - 异步IO\数据库\队列\缓存 本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitM ...
随机推荐
- BigNum模板
#include<iostream> #include<cstring> #include<iomanip> #include<algorithm> u ...
- Spring Cloud Alibaba 使用Sentinel实现接口限流
Sentinel是什么 Sentinel的官方标题是:分布式系统的流量防卫兵.从名字上来看,很容易就能猜到它是用来作服务稳定性保障的.对于服务稳定性保障组件,如果熟悉Spring Cloud的用户,第 ...
- NFS和mount常用参数详解 本文目录
NFS和mount常用参数详解 本文目录 NFS权限参数配置 mount挂载参数 原始驱动程序的挂载选项. 新驱动程序的挂载选项. 怎样改变已经挂载的NTFS卷的权限? 怎样自动挂载一个NTFS卷 ...
- python jieba模块详解
借鉴于 [jieba 模块文档] 用于自己学习和记录! jieba 模块是一个用于中文分词的模块 此模块支持三种分词模式 精确模式(试图将句子最精确的切开,适合文本分析) 全模式(把句子在所有可以成词 ...
- odoo many2one
在xml中使many2one字段 不可点击 不可跳转 options="{'no_open': True, 'no_create': True}"
- 初识类(class&struct)及C/C++封装的差异
初识类(class&struct) 面向对象三大特性:封装.继承和多态.其中不得不谈的就是类,通过类创建一个对象的过程叫实例化,实例化后使用对象可以调用类成员函数和成员变量,其中类成员函数称为 ...
- MyBatis-Spring(四)--MapperFactoryBean实现增删改查
上一篇文章中提到,使用SqlSessionTemplat时需要输入一长串字符串来获取mapper,这种方式IDE不会检查程序的准确性并且很容易出错,所以这篇文章介绍另一种可以避免这种问题,并且也可以使 ...
- 洛谷p1605--迷宫 经典dfs
https://www.luogu.org/problemnew/show/P1605 用这种题来复习一下dfs 给定一个N*M方格的迷宫,迷宫里有T处障碍,障碍处不可通过.给定起点坐标和终点坐标,问 ...
- CSS3属性transform详解【转载】
CSS3属性transform详解之(旋转:rotate,缩放:scale,倾斜:skew,移动:translate) 在CSS3中,可以利用transform功能来实现文字或图像的旋转.缩放.倾 ...
- 封装原生JavaScript的ajax
function obj2str(data) { data = data || {}; // 如果没有传参, 为了添加随机因子,必须自己创建一个对象 data.t = new Date().getTi ...