【sklearn】Toy datasets上的分类/回归问题 (XGBoost实践)
分类问题
1. 手写数字识别问题
from sklearn.datasets import load_digits
digits = load_digits() # 加载手写字符识别数据集
X = digits.data # 特征值
y = digits.target # 目标值
X.shape, y.shape
((1797, 64), (1797,))
划分70%训练集,30%测试集,
from sklearn.model_selection import train_test_split
# 划分数据集,70% 训练数据和 30% 测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((1257, 64), (540, 64), (1257,), (540,))
使用默认参数,
import xgboost as xgb
model_c = xgb.XGBClassifier()
model_c
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, learning_rate=0.1,
max_delta_step=0, max_depth=3, min_child_weight=1, missing=None,
n_estimators=100, n_jobs=1, nthread=None,
objective='binary:logistic', random_state=0, reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, seed=None, silent=None,
subsample=1, verbosity=1)
参数解释:
max_depth – 基学习器的最大树深度。
learning_rate – Boosting 学习率。
n_estimators – 决策树的数量。
gamma – 惩罚项系数,指定节点分裂所需的最小损失函数下降值。
booster – 指定提升算法:gbtree, gblinear or dart。
n_jobs – 指定多线程数量。
reg_alpha – L1 正则权重。
reg_lambda – L2 正则权重。
scale_pos_weight – 正负权重平衡。
random_state – 随机数种子。
model_c.fit(X_train, y_train) # 使用训练数据训练
model_c.score(X_test, y_test) # 使用测试数据计算准确度
0.9592592592592593
简单调参:
| max_depth | result |
|---|---|
| 1 | 0.912962962962963 |
| 2 | 0.9666666666666667 |
| 3 | 0.9592592592592593 |
| 4 | 0.9629629629629629 |
| 5 | 0.9537037037037037 |
| 6 | 0.9537037037037037 |
max_depth=2时效果最好。
| learning_rate | result |
|---|---|
| 0.05 | 0.9148148148148149 |
| 0.1 | 0.9666666666666667 |
| 0.15 | 0.9777777777777777 |
| 0.2 | 0.9814814814814815 |
| 0.25 | 0.9851851851851852 |
| 0.3 | 0.9796296296296296 |
| 0.35 | 0.9851851851851852 |
| 0.4 | 0.9851851851851852 |
learning_rate设置为0.25比较好。
| n_estimators | result |
|---|---|
| 50 | 0.9722222222222222 |
| 75 | 0.9777777777777777 |
| 100 | 0.9851851851851852 |
| 125 | 0.987037037037037 |
| 150 | 0.987037037037037 |
| 200 | 0.987037037037037 |
n_estimators设置为125比较好。
经过调参,准确率从95.9%提高到了98.7%。
from matplotlib import pyplot as plt
from matplotlib.pylab import rcParams
%matplotlib inline
# 设置图像大小
rcParams['figure.figsize'] = [50, 10]
xgb.plot_tree(model_c, num_trees=1)
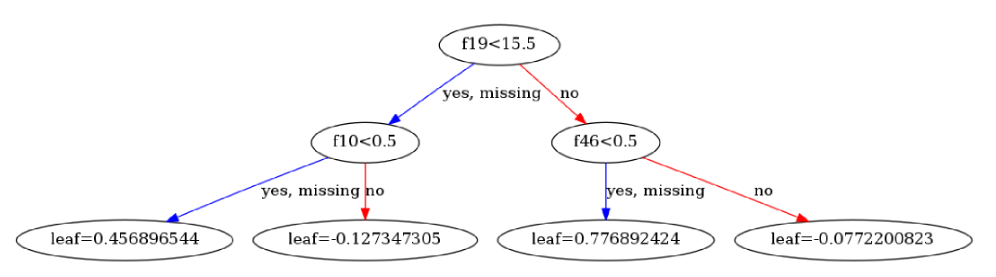
回归问题
1. 波士顿房价预测问题
from sklearn.datasets import load_boston
boston = load_boston()
X = boston.data # 特征值
y = boston.target # 目标值
# 划分数据集,80% 训练数据和 20% 测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((404, 13), (102, 13), (404,), (102,))
默认参数:
model_r = xgb.XGBRegressor()
model_r
XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0,
importance_type='gain', learning_rate=0.1, max_delta_step=0,
max_depth=3, min_child_weight=1, missing=None, n_estimators=100,
n_jobs=1, nthread=None, objective='reg:linear', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=None, subsample=1, verbosity=1)
model_r.fit(X_train, y_train) # 使用训练数据训练
model_r.score(X_test, y_test) # 使用测试数据计算 R^2 评估指标
0.811524182952107
参考资料
scikit-learn toy datasets doc.
【sklearn】Toy datasets上的分类/回归问题 (XGBoost实践)的更多相关文章
- CART(分类回归树)
1.简单介绍 线性回归方法可以有效的拟合所有样本点(局部加权线性回归除外).当数据拥有众多特征并且特征之间关系十分复杂时,构建全局模型的想法一个是困难一个是笨拙.此外,实际中很多问题为非线性的,例如常 ...
- Sklearn库例子2:分类——线性回归分类(Line Regression )例子
线性回归:通过拟合线性模型的回归系数W =(w_1,…,w_p)来减少数据中观察到的结果和实际结果之间的残差平方和,并通过线性逼近进行预测. 从数学上讲,它解决了下面这个形式的问题: Lin ...
- CART决策树(分类回归树)分析及应用建模
一.CART决策树模型概述(Classification And Regression Trees) 决策树是使用类似于一棵树的结构来表示类的划分,树的构建可以看成是变量(属性)选择的过程,内部节 ...
- 连续值的CART(分类回归树)原理和实现
上一篇我们学习和实现了CART(分类回归树),不过主要是针对离散值的分类实现,下面我们来看下连续值的cart分类树如何实现 思考连续值和离散值的不同之处: 二分子树的时候不同:离散值需要求出最优的两个 ...
- 利用CART算法建立分类回归树
常见的一种决策树算法是ID3,ID3的做法是每次选择当前最佳的特征来分割数据,并按照该特征所有可能取值来切分,也就是说,如果一个特征有四种取值,那么数据将被切分成4份,一旦按某特征切分后,该特征在之后 ...
- 决策树的剪枝,分类回归树CART
决策树的剪枝 决策树为什么要剪枝?原因就是避免决策树“过拟合”样本.前面的算法生成的决策树非常的详细而庞大,每个属性都被详细地加以考虑,决策树的树叶节点所覆盖的训练样本都是“纯”的.因此用这个决策树来 ...
- 分类回归树(CART)
概要 本部分介绍 CART,是一种非常重要的机器学习算法. 基本原理 CART 全称为 Classification And Regression Trees,即分类回归树.顾名思义,该算法既 ...
- from sklearn import datasets运行错误:ImportError: DLL load failed: 找不到指定的程序------解决办法
在运行集成学习的多数投票分类代码时,出现错误 from sklearn import datasets from sklearn.model_selection import cross_val_sc ...
- 秒懂机器学习---分类回归树CART
秒懂机器学习---分类回归树CART 一.总结 一句话总结: 用决策树来模拟分类和预测,那些人还真是聪明:其实也还好吧,都精通的话想一想,混一混就好了 用决策树模拟分类和预测的过程:就是对集合进行归类 ...
随机推荐
- springboot使用servlet
基于注解方式: 基于配置类:
- Codeforces_794
A.统计两个guard之间的钞票数. #include<bits/stdc++.h> #define MOD 1000000009 using namespace std; int a,b ...
- 微信小程序—Flex布局
参考教程:http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html https://xluos.github.io/demo/flexb ...
- 量子计算机编程(一)——QPU编程
今天要给大家介绍的是这本书<Programming Quantum Computers -- Essential Algorithms and Code Samples>,主要讲如何在量子 ...
- github三步走(init;add . ;commit -m "提交说明")
掌握以下几点就基本能满足你平时使用了.按这个顺序来1.git安装,已经好了,略 -到这里本地代码推送到远程已经结束了 2.git本地命令操作-shift+右键-git init:初始化git环境-新建 ...
- django项目中使用KindEditor富文本编辑器
先从官网下载插件,放在static文件下 前端引入 <script type="text/javascript" src="/static/back/kindedi ...
- Linux 配置 DNS
这里不讨论如何在linux上搭建一台DNS服务器: 这里讨论的是 配置 linux系统,让其能够解析域名,使用户可以流畅使用Internet 先了解几个文件,位于/etc目录下的有:hosts,hos ...
- [RHEL8]安装Docker Problem: package docker-ce-3:19.03.6-3.el7.x86_64 requires containerd.io
系统环境 # cat /etc/redhat-release Red Hat Enterprise Linux release 8.0 (Ootpa) 安装依赖 # yum install -y yu ...
- 怎么用IDEA快速查看类图关系
做Java开发的,现在普遍都用上idea了.可以说,idea是当之无愧的Java开发神器.如果,你现在还没用idea,那肯定是你还没有感受过它的强大. 好了,话不多说,今天的主题主要是教大家怎么通过i ...
- 五分钟了解抽象语法树(AST)babel是如何转换的?
抽象语法树 什么是抽象语法树? It is a hierarchical program representation that presents source code structure acco ...