Python爬虫-什么是爬虫?
百度百科是这样定义爬虫的:
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
通俗的解释:
打开一个网页,里面有网页内容吧,想象一下,有个工具,可以把网页上的内容获取下来,存到你想要的地方,这个工具就是我们今天的主角:爬虫。
打开浏览器(强烈建议谷歌浏览器),找到浏览器地址栏,然后在里敲网址https://music.163.com/,你会看到网页内容。
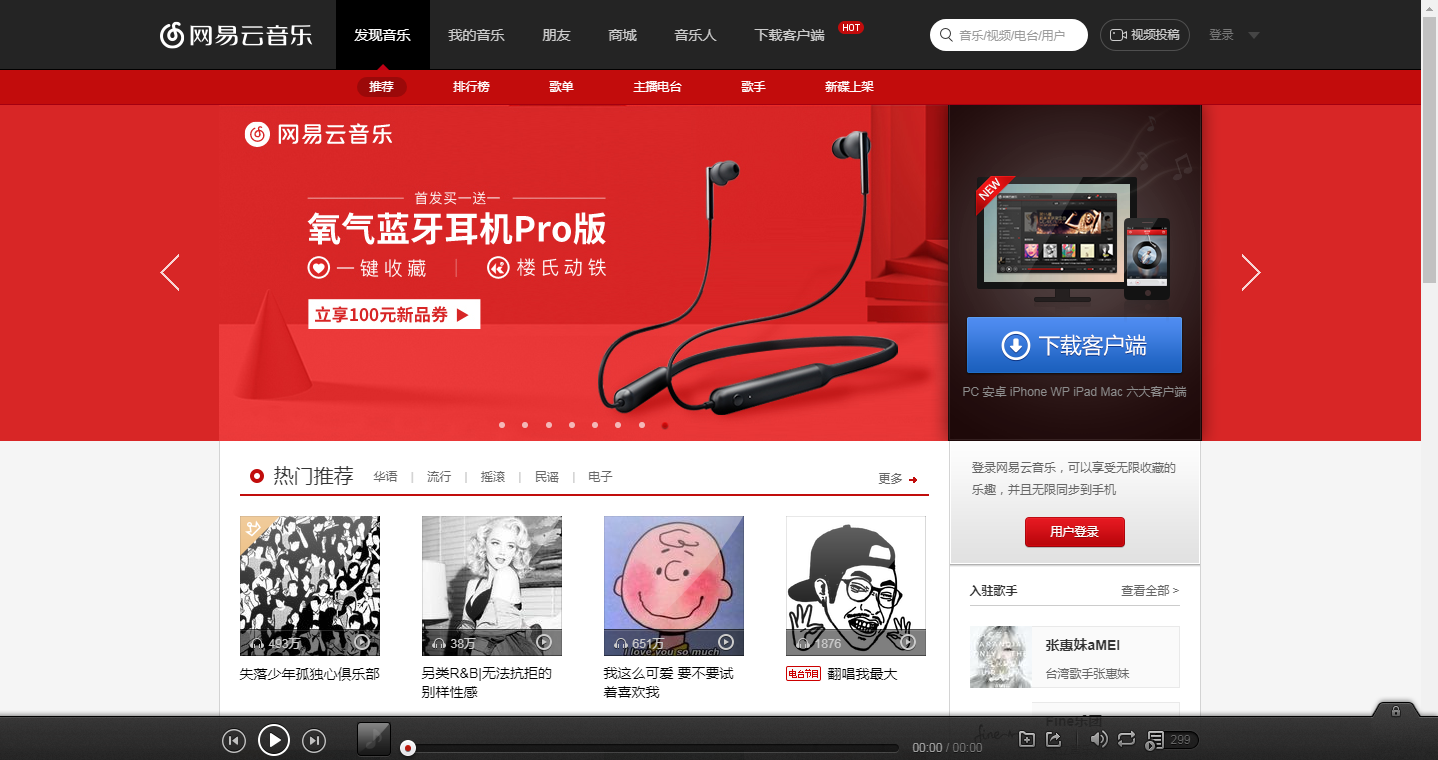
鼠标在页面上点击右键,然后点击查看网页源代码(view page source)。看到这些文字了吗?这才是网页本来的样子。

其实,所有的网页都是HTML+CSS+JavaScript代码,只不过浏览器将这些代码解析成了上面的网页,我们的小爬虫抓取的其实就是这些代码中的文本啦。
这不合理啊,难不成那些图片也是文本?
恭喜你,答对了。回到浏览器中有图的哪个tab页,鼠标右键,点击Inspect。会弹出一个面板,点击板左上角的箭头,点击虐狗图片,你会看到下面有红圈圈的地方,是图片的网络地址。图片可以通过该地址保存到本地哦。
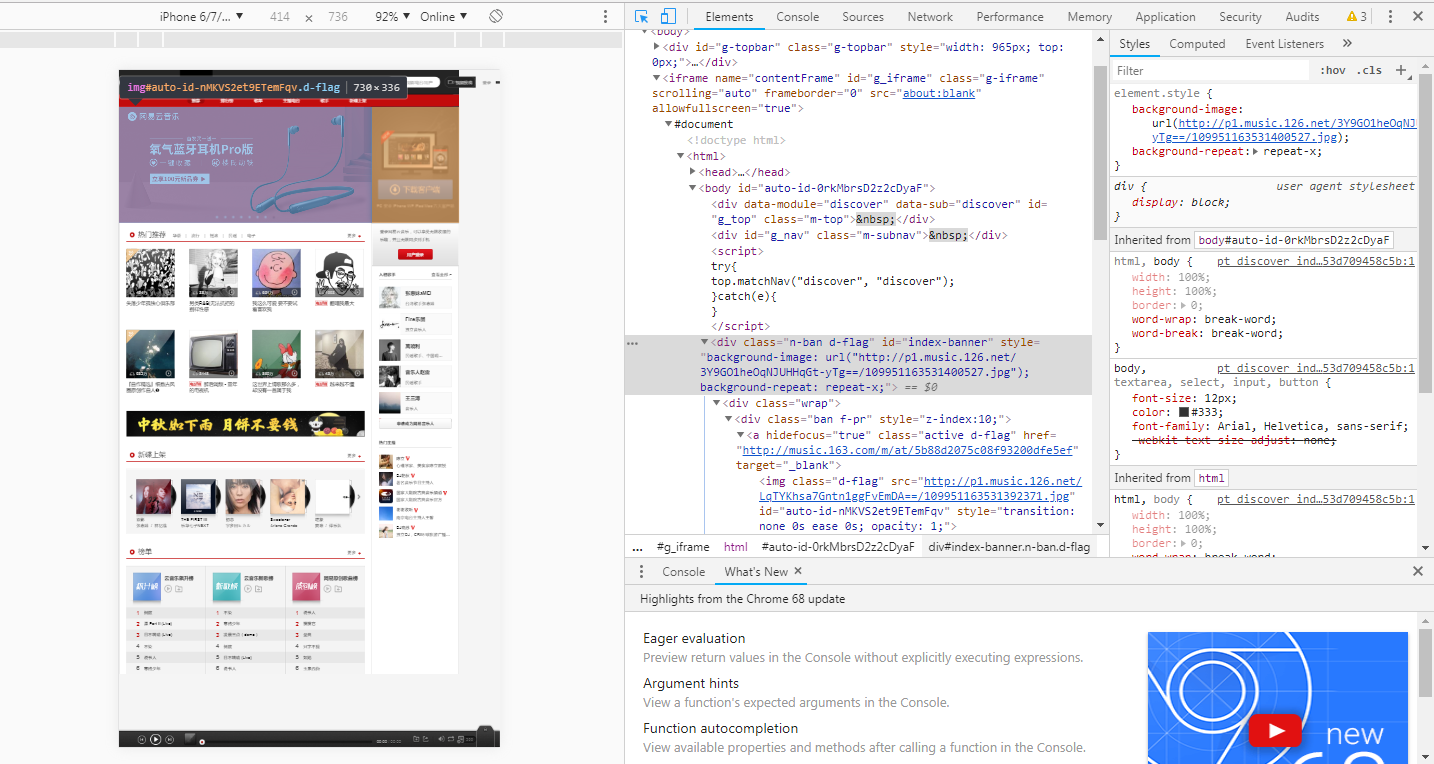
没错,我们的小爬虫抓取的正是网页中的数据,但是前提是你要知道你想要抓取什么数据,你的目标网站是什么,才可以把想法变成现实的哦。
说了这么多,学习Python爬虫还是需要一定的基础知识呢?
HTML
这个能够帮助你了解网页的结构,内容等。可以参考W3School的教程或者菜鸟教程。Python
如果有编程基础的小伙伴儿,推荐看一个廖雪峰的Python教程就够了
没有编程基础的小伙伴,推荐看看视频教程(网易云课堂搜Python),然后再结合廖雪峰的教程,双管齐下。
其实知乎上总结的已经非常好了,我就不多唠叨了。知乎-如何系统的自学PythonTCP/IP协议,HTTP协议
这些知识能够让你了解在网络请求和网络传输上的基本原理,了解就行,能够帮助今后写爬虫的时候理解爬虫的逻辑。
廖雪峰Python教程里也有简单介绍,可以参考:TCP/IP简介,HTTP协议
注(参考):https://www.cnblogs.com/Albert-Lee/p/6226699.html
Python爬虫-什么是爬虫?的更多相关文章
- Python初学者之网络爬虫(二)
声明:本文内容和涉及到的代码仅限于个人学习,任何人不得作为商业用途.转载请附上此文章地址 本篇文章Python初学者之网络爬虫的继续,最新代码已提交到https://github.com/octans ...
- 【Python】:简单爬虫作业
使用Python编写的图片爬虫作业: #coding=utf-8 import urllib import re def getPage(url): #urllib.urlopen(url[, dat ...
- 使用python/casperjs编写终极爬虫-客户端App的抓取-ZOL技术频道
使用python/casperjs编写终极爬虫-客户端App的抓取-ZOL技术频道 使用python/casperjs编写终极爬虫-客户端App的抓取
- python编写知乎爬虫实践
爬虫的基本流程 网络爬虫的基本工作流程如下: 首先选取一部分精心挑选的种子URL 将种子URL加入任务队列 从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页 ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- 洗礼灵魂,修炼python(72)--爬虫篇—爬虫框架:Scrapy
题外话: 前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的) 上面截图的是我的草稿 然后当我开始写博文 ...
- 洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块 1.简介 feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom .使用它我们可从任何 RSS 或 Atom 订阅源得到标题.链接和文章的 ...
- Python爬虫-01:爬虫的概念及分类
目录 # 1. 为什么要爬虫? 2. 什么是爬虫? 3. 爬虫如何抓取网页数据? # 4. Python爬虫的优势? 5. 学习路线 6. 爬虫的分类 6.1 通用爬虫: 6.2 聚焦爬虫: # 1. ...
- 洗礼灵魂,修炼python(52)--爬虫篇—【转载】爬虫工具列表
与爬虫相关的常用模块列表. 原文出处:传送门链接 网络 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pycurl). pycurl – 网络 ...
随机推荐
- 【C#公共帮助类】JsonHelper 操作帮助类
四个主要操作类:JsonConverter .JsonHelper .JsonSplit .AjaxResult 一.JsonConverter: 自定义查询对象转换动态类.object动态类转换js ...
- C语言 · x的x次幂结果为10
如果x的x次幂结果为10(参见[图1.png]),你能计算出x的近似值吗? 显然,这个值是介于2和3之间的一个数字. 请把x的值计算到小数后6位(四舍五入),并填写这个小数值. 注意:只填写一个小数, ...
- Go Revel - Websockets
revel提供了对`Websockets`的支持. 处理`Websockets`链接: 1.添加一个`WS`类型方法的路由 2.添加一个action接受 `*websocket.Conn`参数 例如, ...
- Android——关于PagerAdapter的使用方法的总结(转)
PagerAdapter简介 PagerAdapter是android.support.v4包中的类,它的子类有FragmentPagerAdapter, FragmentStatePagerAdap ...
- RavenDb学习(六)查询补充特性
.延迟加载 原来的查询方式如下: IEnumerable<User> users = session .Query<User>() .Where(x => x.Name ...
- sql索引创建
什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的速度,汉语字(词)典一般都有按拼音. ...
- js android页面被挂起问题解决
问题: 页面上设了定时器,但浏览器后台运行被挂起时,页面定时器暂停 解决: 向服务器发送同步请求,服务器延时1秒返回.页面收到返回时再次发送请求 服务器相当于起博器,维持页面将停的心跳
- vim for python
set encoding=utf8 set paste 编辑模式下的 复制粘贴 set expandtab 貌似是一个 tab 替换成4个空格, 而且当你使用 backspace(删除键), 会自 ...
- CNDS账号密码
您购买的CSDN 100下载积分 发货如下:CSDN账号:masunwei0961CSDN密码:sangsang3邮箱:lao42981894zh@163.com邮箱密码:songsong3
- 【Centos】【Python】【Flask】阿里云上部署一个 flask 项目
1. 安装 python3 和 pip3 参考:http://www.cnblogs.com/mqxs/p/8692870.html 2.安装 lnmpa 集成开发环境 参考:http://www.c ...