com.panie 项目开发随笔_爬虫初识(2017.2.7)
(一)
本章打算研究一下爬虫。我想用爬虫简单的爬取几篇文章,以及收集一下常用网站的信息。
(二)
以开源项目 JAVA爬虫 WebCollector 为源码研究。在此基础上改为适合自己项目的代码。
(三)
WebCollector致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有很强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了Jsoup,可进行精准的网页解析。
内核构架图:
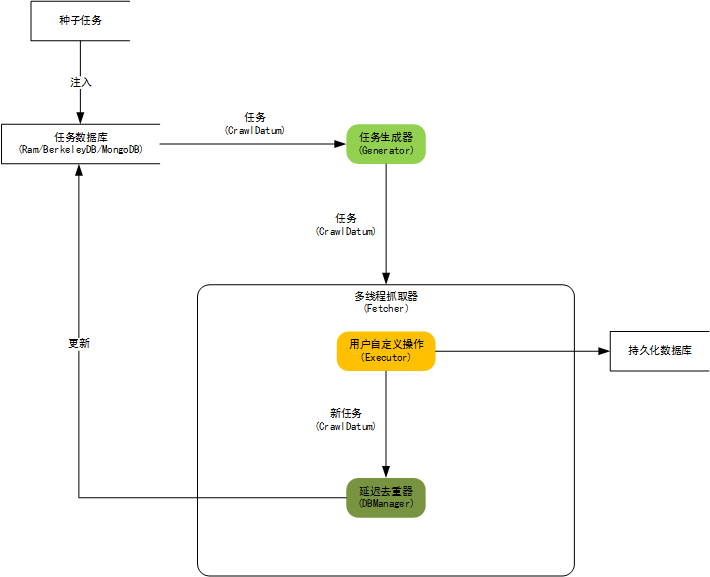
WebCollector的正文抽取API都被封装为ContentExtractor类的静态方法。 可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在Element)。
标题抽取和日期抽取使用简单启发式算法,并没有像正文抽取算法一样在标准数据集上测试,算法仍在更新中。
WebCollector 2.x版本特性:
- 1)自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
- 2)可以为每个URL设置附加信息(MetaData),利用附加信息可以完成很多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST参数传递、增量更新等。
- 3)使用插件机制,WebCollector内置两套插件。
- 4)内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
- 5)内置一套基于Berkeley DB(BreadthCrawler)的插件:适合处理长期和大量级的任务,并具有断点爬取功能,不会因为宕机、关闭导致数据丢失。
- 6)集成selenium,可以对javascript生成信息进行抽取
- 7)可轻松自定义http请求,并内置多代理随机切换功能。 可通过定义http请求实现模拟登录。
- 8)使用slf4j作为日志门面,可对接多种日志
(四)
该源码的使用方法仅需按照其示例 TutorialCrawler 写即可。比如,类似如下自定义方法:
package com.panie.modules.crawl.webcollector.example; import org.jsoup.nodes.Document; import com.panie.modules.crawl.webcollector.model.CrawlDatums;
import com.panie.modules.crawl.webcollector.model.Page;
import com.panie.modules.crawl.webcollector.plugin.berkeley.BreadthCrawler; public class NewsCrawler extends BreadthCrawler
{
public NewsCrawler(String crawlPath, boolean autoParse)
{
super(crawlPath, autoParse);
/*start page*/
this.addSeed("http://news.hfut.edu.cn/list-1-1.html"); /*fetch url like http://news.hfut.edu.cn/show-xxxxxxhtml*/
this.addRegex("http://news.hfut.edu.cn/show-.*html");
/*do not fetch jpg|png|gif*/
this.addRegex("-.*\\.(jpg|png|gif).*");
/*do not fetch url contains #*/
this.addRegex("-.*#.*");
} @Override
public void visit(Page page, CrawlDatums next)
{
String url = page.getUrl();
/*if page is news page*/
if (page.matchUrl("http://news.hfut.edu.cn/show-.*html")) {
/*we use jsoup to parse page*/
Document doc = page.getDoc(); /*extract title and content of news by css selector*/
String title = page.select("div[id=Article]>h2").first().text();
String content = page.select("div#artibody", 0).text(); System.out.println("URL:\n" + url);
System.out.println("title:\n" + title);
System.out.println("content:\n" + content); /*If you want to add urls to crawl,add them to nextLink*/
/*WebCollector automatically filters links that have been fetched before*/
/*If autoParse is true and the link you add to nextLinks does not match the regex rules,the link will also been filtered.*/
//next.add("http://xxxxxx.com");
}
} public static void main(String[] args) throws Exception
{
NewsCrawler crawler = new NewsCrawler("crawl", true);
//crawler.addSeed("http://news.hfut.edu.cn/.*");
crawler.setThreads(50);
crawler.setTopN(100);
//crawler.setResumable(true);
/*start crawl with depth of 4*/
crawler.start(4);
}
}
根据实际需要将 visit 方法 自定义相关内容
com.panie 项目开发随笔_爬虫初识(2017.2.7)的更多相关文章
- com.panie 项目开发随笔_数据字典(2017.2.24)
(一) 做一个网站,第一步需要考虑的是从哪个地方开始下手.首先,每一个功能肯定有最基本的增删改查功能,而此功能一般都分为两个页面. 1) 列表显示页面.用列表来展示数据库中的数据,多用于分页显示.该页 ...
- com.panie 项目开发随笔_功能任务设计(2016.12.28)
(一) 第一个菜单 做什么好呢? 1)上次 在研究的功能 是 爬虫,需要将定时爬虫的任务加进来 2)博客的页面,也需要重新布局出来 3)需要做一个,添加博客的页面 (二) 那就先做博客管理吧! 先添加 ...
- com.panie 项目开发随笔_前后端框架考虑(2016.12.8)
(一) 近日和一同学联系,说了我想要做一个网站的打算.她很感兴趣.于是我们协商了下,便觉得一起合作.她写前端,我写后台.因为我对于前端样式设计并不怎么熟悉. (二) 我们决定先做一个 个人博客. 网上 ...
- com.panie 项目开发随笔(NoF)_环境搭建(2016.12.29)
(一) 最近做的框架一直在 spring + springmvc + mybatis 的基础上,使用框架的好处自然是 简化了自己的开发工作,定义好大的结构体系后就在里面套用方法了! 可是框架的毛病同样 ...
- react_app 项目开发 (5)_前后端分离_后台管理系统_开始
项目描述 技术选型 react API 接口 接口文档,url,请求方式,参数类型, 根据文档描述的方法,进行 postman 测试,看是否能够得到理想的结果 collections - 创建文件取项 ...
- kotlin项目开发基础之gradle初识
在Android Studio推出之后默认的打包编译工具就变为gradle了,我想对于一名Android程序员而言没人不对它知晓,但是对于它里面的一些概念可能并不是每个人都了解,只知道这样配置就ok了 ...
- react_app 项目开发 (3)_单页面设计_react-router4
(web) 利用 react-router4 实现 单页面 开发 SPA 应用 ---- (Single Page Web Application) 整个应用只有 一个完整的页面 单击链接不会刷新页面 ...
- react_app 项目开发 (4)_ React UI 组件库 ant-design 的基本使用
最流行的开源 React UI 组件库 material-ui 国外流行(安卓手机的界面效果)文档 ant-design 国内流行 (蚂蚁金服 设计,一套 PC.一套移动端的____下拉菜单.分页.. ...
- react_app 项目开发 (6)_后台服务器端-node
后台服务器端 负责处理前台应用提交的请求,并向前台返回 json 数据 前台应用 负责 展现数据与用户交互 发 ajax 请求与后台应用交互 yarn add axios /src/api/ajax. ...
随机推荐
- Leetcode:Edit Distance 解题报告
Edit Distance Given two words word1 and word2, find the minimum number of steps required to convert ...
- Nginx缓存功能、防盗链、URL重写
nginx做为反向代理时,能够将来自upstream的响应缓存至本地,并在后续的客户端请求同样内容时直接从本地构造响应报文. nginx的缓存数据结构: 共享内存:存储键和缓存对象元数据 磁盘空间:存 ...
- poj1733(区间上的种类并查集)
题目大意是:一个由0,1组成的数字串~~,现在你问一个人,第i位到第j位的1的个数为奇数还是偶数.一共会告诉你几组这样的数 要你判断前k组这个人回答的都是正确的,到第k+1组,这个人说的是错的,要你输 ...
- C#学习笔记(2)——操作sqlite数据库增删改查
说明(2017-5-25 10:49:50): 1. app.config文件 Alt+Shift+C创建类,选择“应用程序配置文件”,添加<connectionStrings>,要先打个 ...
- python - hadoop,mapreduce demo
Hadoop,mapreduce 介绍 59888745@qq.com 大数据工程师是在Linux系统下搭建Hadoop生态系统(cloudera是最大的输出者类似于Linux的红帽), 把用户的交易 ...
- [转]mybatis如何直接 执行传入的任意sql语句 并按照顺序取出查询的结果集
原文地址:https://www.cnblogs.com/wuyun-blog/p/5769096.html 需求: 1.直接执行前端传来的任何sql语句,parameterType="St ...
- Ubuntu 14.04 编译 Android 4.2.2 for Tiny4412
. . . . . 在学校里是用 Redhat 6.4 编译的 Android 4.2.2 很顺利,把源码包拷贝到笔记本上的 Ubuntu 14.04 上再编译遭遇了各种坑,所以便有了这篇博客记录解决 ...
- laravel服务l队列资料整理
Laravel 队列系列 —— 基于 Redis 实现任务队列的基本配置和使用 1.概述 在Web开发中,我们经常会遇到需要批量处理任务的场景,比如群发邮件.秒杀资格获取等,我们将这些耗时或者高并发的 ...
- CSS一个元素同时使用多个类选择器(class selector)
CSS类选择器参考手册 一个元素同时使用多个类选择器 CSS中类选择器用点号表示.实际项目中一个div元素为了能被多个样式表匹配到(样式复用),通常div的class中由好几段组成,如<div ...
- WPF重写Button样式
首先指定OverridesDefaultStyle属性为True: 然后添加样式: 重写ControlTemplate: <Window.Resources> <Style x:Ke ...