python - hadoop,mapreduce demo
Hadoop,mapreduce 介绍
59888745@qq.com
大数据工程师是在Linux系统下搭建Hadoop生态系统(cloudera是最大的输出者类似于Linux的红帽),
把用户的交易或行为信息通过HDFS(分布式文件系统)等存储用户数据文件,然后通过Hbase(类似于NoSQL)等存储数据,再通过Mapreduce(并行计算框架)等计算数据,然后通过hiv或pig(数据分析平台)等分析数据,最后按照用户需要重现出数据.
Hadoop是一个由Apache基金会所开发的开源分布式系统基础架构
Hadoop,最基础的也就是HDFS和Mapreduce了,
HDFS是一个分布式存储文件系统
Mapreduce是一个分布式计算的框架,两者结合起来,就可以很容易做一些分布式处理任务了
大纲:
一、MapReduce 基本原理
二、MapReduce 入门示例 - WordCount 单词统计
三、MapReduce 执行过程分析
实例1 - 自定义对象序列化
实例2 - 自定义分区
实例3 - 计算出每组订单中金额最大的记录
实例4 - 合并多个小文件
实例5 - 分组输出到多个文件
四、MapReduce 核心流程梳理
实例6 - join 操作
实例7 - 计算出用户间的共同好友
五、下载方式
一、MapReduce基本原理
MapReduce是一种编程模型,用于大规模数据集的分布式运算。
1、MapReduce通俗解释
图书馆要清点图书数量,有10个书架,管理员为了加快统计速度,找来了10个同学,每个同学负责统计一个书架的图书数量。
张同学统计 书架1
王同学统计 书架2
刘同学统计 书架3
……
过了一会儿,10个同学陆续到管理员这汇报自己的统计数字,管理员把各个数字加起来,就得到了图书总数。
这个过程就可以理解为MapReduce的工作过程。
2、MapReduce中有两个核心操作
(1)map
管理员分配哪个同学统计哪个书架,每个同学都进行相同的“统计”操作,这个过程就是map。
(2)reduce
每个同学的结果进行汇总,这个过程是reduce。
3、MapReduce工作过程拆解
下面通过一个景点案例(单词统计)看MapReduce是如何工作的。
有一个文本文件,被分成了4份,分别放到了4台服务器中存储
Text1:the weather is good
Text2:today is good
Text3:good weather is good
Text4:today has good weather
现在要统计出每个单词的出现次数。

处理过程
(1)拆分单词
map节点1
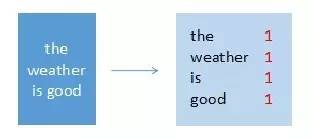
输入:“the weather is good”
输出:(the,1),(weather,1),(is,1),(good,1)
map节点2
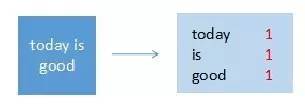
输入:“today is good”
输出:(today,1),(is,1),(good,1)
map节点3
输入:“good weather is good”
输出:(good,1),(weather,1),(is,1),(good,1)

map节点4
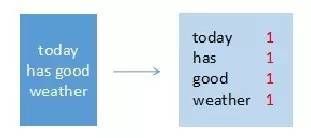
输入:“today has good weather”
输出:(today,1),(has,1),(good,1),(weather,1)
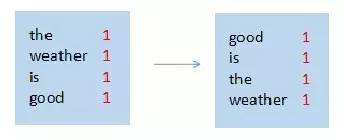
(2)排序
map节点1
map节点2

map节点3

map节点4

(3)合并
map节点1

map节点2

map节点3

map节点4

(4)汇总统计
每个map节点都完成以后,就要进入reduce阶段了。
例如使用了3个reduce节点,需要对上面4个map节点的结果进行重新组合,比如按照26个字母分成3段,分配给3个reduce节点。
Reduce节点进行统计,计算出最终结果。

这就是最基本的MapReduce处理流程。
4、MapReduce编程思路
了解了MapReduce的工作过程,我们思考一下用代码实现时需要做哪些工作?
在4个服务器中启动4个map任务
每个map任务读取目标文件,每读一行就拆分一下单词,并记下来次单词出现了一次
目标文件的每一行都处理完成后,需要把单词进行排序
在3个服务器上启动reduce任务
每个reduce获取一部分map的处理结果
reduce任务进行汇总统计,输出最终的结果数据
但不用担心,MapReduce是一个非常优秀的编程模型,已经把绝大多数的工作做完了,我们只需要关心2个部分:
map处理逻辑——对传进来的一行数据如何处理?输出什么信息?
reduce处理逻辑——对传进来的map处理结果如何处理?输出什么信息?
编写好这两个核心业务逻辑之后,只需要几行简单的代码把map和reduce装配成一个job,然后提交给Hadoop集群就可以了。
至于其它的复杂细节,例如如何启动map任务和reduce任务、如何读取文件、如对map结果排序、如何把map结果数据分配给reduce、reduce如何把最终结果保存到文件等等,MapReduce框架都帮我们做好了,而且还支持很多自定义扩展配置,例如如何读文件、如何组织map或者reduce的输出结果等等,后面的示例中会有介绍。
二、MapReduce入门示例:WordCount单词统计
WordCount是非常好的入门示例,相当于helloword,下面就开发一个WordCount的MapReduce程序,体验实际开发方式。
example:
#删除已有文件夹
hadoop fs -rmr /chenshaojun/input/example_1
hadoop fs -rmr /chenshaojun/output/example_1
#创建输入文件夹
hadoop fs -mkdir /chenshaojun/input/example_1
#放入输入文件
hadoop fs -put text* /chenshaojun/input/example_1
#查看文件是否放好
hadoop fs -ls /chenshaojun/input/example_1
#本地测试一下map和reduce
head -20 text1.txt | python count_mapper.py | sort | python count_reducer.py
#集群上跑任务
hadoop jar /usr/lib/hadoop-current/share/hadoop/tools/lib/hadoop-streaming-2.7.2.jar \
-file count_mapper.py \ #提交文件到集群
-mapper count_mapper.py \
-file count_reducer.py \
-reducer count_reducer.py \
-input /chenshaojun/input/example_1 \
-output /chenshaojun/output/example_1 # 必须不存在,若存在output会抱错,不会覆盖
count_mapper.py
import sys
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word.lower(), 1)
count_reducer.py
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
python - hadoop,mapreduce demo的更多相关文章
- Hadoop(三)通过C#/python实现Hadoop MapReduce
MapReduce Hadoop中将数据切分成块存在HDFS不同的DataNode中,如果想汇总,按照常规想法就是,移动数据到统计程序:先把数据读取到一个程序中,再进行汇总. 但是HDFS存的数据量非 ...
- Writing an Hadoop MapReduce Program in Python
In this tutorial I will describe how to write a simpleMapReduce program for Hadoop in thePython prog ...
- Hadoop:使用原生python编写MapReduce
功能实现 功能:统计文本文件中所有单词出现的频率功能. 下面是要统计的文本文件 [/root/hadooptest/input.txt] foo foo quux labs foo bar quux ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
- Python实现Hadoop MapReduce程序
1.概述 Hadoop Streaming提供了一个便于进行MapReduce编程的工具包,使用它可以基于一些可执行命令.脚本语言或其他编程语言来实现Mapper和 Reducer,从而充分利用Had ...
- 用Python语言写Hadoop MapReduce程序Writing an Hadoop MapReduce Program in Python
In this tutorial I will describe how to write a simple MapReduce program for Hadoop in the Python pr ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- 从分治算法到 Hadoop MapReduce
从分治算法说起 要说 Hadoop MapReduce 就不得不说分治算法,而分治算法其实说白了,就是四个字 分而治之 .其实就是将一个复杂的问题分解成多组相同或类似的子问题,对这些子问题再分,然后再 ...
- hadoop mapreduce 基础实例一记词
mapreduce实现一个简单的单词计数的功能. 一,准备工作:eclipse 安装hadoop 插件: 下载相关版本的hadoop-eclipse-plugin-2.2.0.jar到eclipse/ ...
随机推荐
- libevent的问题
问题: nginx error while loading shared libraries: libevent-2.0.so.5: cannot open shared object file: N ...
- c2java select algorithm
对于非常多应用来说,随机算法是最简单的或者最快的.既简单又快的有没有呢? 那须要深刻的洞察力或者革命性的突破. 什么是随机算法 随机算法与确定算法差别是:它还接收输入随机比特流来做随机决策. 对于同一 ...
- java中的switch case default break
package com.didispace; /** * Created by gmq on 2017/08/07. * * @version 1.0 * @since 2017/08/07 10:4 ...
- Debian静态IP地址和DNS
Debian静态IP地址和DNS 一.配置文件及路径 /etc/network/interfaces 二.IP地址1. DHCP的IP配置如下 # The primary network interf ...
- 使用C#WebClient类访问(上传/下载/删除/列出文件目录)
在使用WebClient类之前,必须先引用System.Net命名空间,文件下载.上传与删除的都是使用异步编程,也可以使用同步编程, 这里以异步编程为例: 1)文件下载: static void Ma ...
- How to compare dates in Java
How to compare dates in JavaBy mkyong | January 18, 2010 | Updated : November 15, 2016 | Viewed : 93 ...
- Java项目多数据源配置 (转)
由于种种原因,有的时候可能要连接别人的数据库,或者不同的数据库没法自动转换,重构起来数据量又太大了,我们不得不在一个项目中连接多个数据源.从网上找了各种资料,只有这位大神给出的解决方案一下子就成功了. ...
- Package CJK Error: Invalid character code. 问题解决方法--xelatex和pdflatex编译的转换
Package CJK Error: Invalid character code. 问题解决方法--xelatex和pdflatex编译的转换 解决方法:添加格式说明信息 将下面语句: \docum ...
- 配置并使用Android支持的库
原文链接:http://android.eoe.cn/topic/android_sdk Android Support Library(支持库)提供了包含一个API库的JAR文件,当你的应用运行在A ...
- [svc]Linux中Swap与Memory内存简单介绍
swap区域是干嘛的 cpu 内存(不常用到的进程swap区) 磁盘 当内存没有可用的,就必须要把内存中不经常运行的程序给踢出去.但是踢到哪里去,这时候swap就出现了. 背景介绍 对于Linux来说 ...