网络爬虫-url索引
网络爬虫-url索引
http://www.cnblogs.com/yuandong/archive/2008/08/28/Web_Spider_Url_Index.html
url索引的作用是判断一个url是否被抓取过,采用的算法主要是MD5数字签名。
假设一共要抓取的url不超过1亿条,用一个二进制的位表示一个url是否被抓取过,则至少需要1亿个位,我们管每一个位叫一个“槽”。考虑到MD5的算法是可能出现冲突(即不同的url算出来的MD5可能相同,这种概率很小),槽越少,冲突越明显,所以槽越多越好。但另一方面,还要考虑到占用内存的大小,因为在抓取的过程中,为了保证效率,所有的槽都需要载入内存。目前我使用的是2的28次方,即32M,相当于268435456(2.6亿)个槽。
当要判断一个url是否已经抓取过的时候,只要判断该url经过MD5签名后的值所对应的槽是否标记为1即可。例如给出的url是:http://www.ouc.edu.cn/,经过128位的MD5签名后,得出的1073542761,则需要判断的就是第1073542761个槽是0还是1。同样的道理,当完成一个url的抓取后,要将对应的槽标记为1。
存储槽的32M空间在内存是不连续的,因为操作系统很难划分出32M的连续内存空间,所以将其分为4096个段Segment,每段2048个32位整数,32*2048*4096=268435456。相当于一个整型的二维数组。
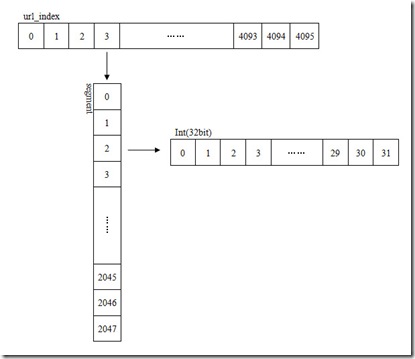
我们使用32位的MD5作为签名,表示为一个整数。这个整数分为三部分,分别是段地址、段偏移和值地址。第5-16位表示段地址,17-27位表示段偏移,28-32位(最后5位,取值范围为2的5次方,即0-31)表示在整形值中的位置、即值地址。

当给定一个url的MD5值时,通过以下函数计算出其段地址:
1: unsigned short get_segment_index(unsigned int md5) {
2:
3: //5-16位表示段地址
4:
5: unsigned short result;
6: bzero(&result, sizeof(unsigned short));
7: memcpy(&result, ((char*)&md5) + 2, sizeof(unsigned short));
8:
9: return result & 0x0FFF;
10: }
通过以下函数计算出其段偏移:
1: unsigned short get_segment_offset(unsigned int md5) {
2:
3: //17-27位表示段偏移
4:
5: unsigned short result;
6: bzero(&result, sizeof(unsigned short));
7: memcpy(&result, ((char*)&md5), sizeof(unsigned short));
8:
9: return result >> 5;
10: }
通过以下函数计算其值偏移:
1: unsigned int get_value(unsigned int md5) {
2:
3: //28-32(最后5位)为表示值
4:
5: unsigned int result = 1;
6: return result << (md5 & 0x0000001F);
7: }
再得到段地址、段偏移和值偏移后,就通过一下函数判定该Url是否已被抓取:
1: bool is_url_crawled(char* url) {
2:
3: //将给出的url进行md5运算,取得对应的Value,于储存的Value按位与
4:
5: unsigned int url_md5 = md5(url);
6: unsigned short segment_index = get_segment_index(url_md5);
7: unsigned short segment_offset = get_segment_offset(url_md5);
8: unsigned int value = get_value(url_md5);
9:
10: unsigned int result = (unsigned int)
(url_index[segment_index][segment_offset] & value);
11:
12: return result > 0 ? TRUE : FALSE;
13: }
如果未被抓取,在完成抓取后,通过以下函数标记为已抓取:
1: int mark_url_as_crawled(char* url) {
2:
3: //取得段地址、段偏移和url对应的值
4: unsigned int url_md5 = md5(url);
5: unsigned short segment_index = get_segment_index(url_md5);
6: unsigned short segment_offset = get_segment_offset(url_md5);
7: unsigned int value = get_value(url_md5);
8:
9: //通过按位或标记url对应的位为已抓取
10: url_index[segment_index][segment_offset] |= value;
11:
12: //同步写入索引文件
13: value = url_index[segment_index][segment_offset];
14: long offset = (((long)segment_index) * SEGMENT_LENGTH + segment_offset)
* sizeof(unsigned int);
15: if(fseek(index_file, offset, SEEK_SET) != 0)
16: return -1;
17:
18: if(fwrite(&value, sizeof(unsigned int), 1, index_file) != 1)
19: return -1;
20:
21: fflush(index_file);
22: return 0;
23: }
网络爬虫-url索引的更多相关文章
- 网络爬虫url跳转代码
from bs4 import BeautifulSoup from urllib.request import urlopen import re import random base_url = ...
- python网络爬虫(一):网络爬虫科普与URL含义
1. 科普 通用搜索引擎处理的对象是互联网的网页,目前网页的数量数以亿计,所以搜索引擎面临的第一个问题是如何设计出高效的下载系统,已将海量的网页下载到本地,在本地形成互联网网页的镜像.网络爬虫 ...
- Python 网络爬虫 008 (编程) 通过ID索引号遍历目标网页里链接的所有网页
通过 ID索引号 遍历目标网页里链接的所有网页 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyChar ...
- 【Python网络爬虫一】爬虫原理和URL基本构成
1.爬虫定义 网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常 ...
- [Python]网络爬虫(一):抓取网页的含义和URL基本构成
一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的. 从网站某一个 ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- [原创]手把手教你写网络爬虫(7):URL去重
手把手教你写网络爬虫(7) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 本期我们来聊聊URL去重那些事儿.以前我们曾使用Python的字典来保存抓取过的URL,目的是将重复抓取的UR ...
- Python 网络爬虫 009 (编程) 通过正则表达式来获取一个网页中的所有的URL链接,并下载这些URL链接的源代码
通过 正则表达式 来获取一个网页中的所有的 URL链接,并下载这些 URL链接 的源代码 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 ...
- 开源的49款Java 网络爬虫软件
参考地址 搜索引擎 Nutch Nutch 是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. Nutch的创始人是Doug Cutting, ...
随机推荐
- JavaScript之Loading进度条
一个loading进度条,定义一个fakeProgress方法,定位一个URL,然后setTimeout设置跳转时间我们就能看到我们要打开的URL网址了. 这个链接我就直接链接到我的新浪博客去了,算是 ...
- oracle 所有下级
--所有下级 SELECT SAP_ORGAN_CODE FROM SAP_ORGAN_LEVEL CONNECT BY PRIOR SAP_FATHER_ORGAN_CODE= SAP_ORGAN_ ...
- PHP学习笔记 - 进阶篇(3)
PHP学习笔记 - 进阶篇(3) 类与面向对象 1.类和对象 类是面向对象程序设计的基本概念,通俗的理解类就是对现实中某一个种类的东西的抽象, 比如汽车可以抽象为一个类,汽车拥有名字.轮胎.速度.重量 ...
- C# 微信扫码支付API (微信扫码支付模式二)
一.SDK下载地址:https://pay.weixin.qq.com/wiki/doc/api/native.php?chapter=11_1,下载.NET C#版本: 二.微信相关设置:(微信扫码 ...
- 学习之spring自带缓存
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:context="http://w ...
- Contest1065 - 第四届“图灵杯”NEUQ-ACM程序设计竞赛(个人赛)A蔡老板的会议
题目描述 图灵杯个人赛就要开始了,蔡老板召集俱乐部各部门的部长开会.综合楼有N (1<=N<=1000)间办公室,编号1~N每个办公室有一个部长在工(mo)作(yu),其中X号是蔡老板的办 ...
- C++运用SDK截屏
引言 最近有一个需要截取当前屏幕,并保存成BMP文件的需求.整个需求,拆分成三步:1.截取屏幕,获得位图数据.2.配合bmp文件结构信息,将数据整合.3.对整合后的数据做操作,如保存在本地.通过网络传 ...
- Catalyst揭秘 Day7 SQL转为RDD的具体实现
Catalyst揭秘 Day7 SQL转为RDD的具体实现 从技术角度,越底层和硬件偶尔越高,可动弹的空间越小,而越高层,可动用的智慧是更多.Catalyst就是个高层的智慧. Catalyst已经逐 ...
- 【信息学奥赛一本通】第三部分_队列 ex2_3produce 产生数
给出一个整数n(n<=2000)(代码可适用n<=10^31)和k个变换规则(k<=15). 规则:1.1个数字可以变换成另1个数字: 2.规则中右边的数字不能为零. BFS #in ...
- asp.net 运行时, 报控件不存在
Asp.net 运行时,报控件不存在,但系统中确实加入了控件z, 但是生成网站的时候,报控件不存在,输入代码的时候,this.edtxx.Text 确实可以输入 原因: 系统修改的时候,作了一个备份, ...