Stage划分和Task最佳位置算法源码彻底解密
本课主题
- Job Stage 划分算法解密
- Task 最佳位置算法实现解密
引言
作业调度的划分算法以及 Task 的最佳计算位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心,这也是关系到整个作业有集群中该怎么运行;其次就是数据本地性,Spark 一般的代码都是链式表达的,这就让一个任务什么时候划分成 Stage,在大数据世界要追求最大化的数据本地性,所有最大化的数据本地性就是在数据计算的时候,数据就在内存中。希望这篇文章能为读者带出以下的启发:
- 了解 Stage 的具体是如何划分的
- 了解 数据本地性的最大化
Job Stage 划分算法解密
- Spark Application 中可以因为不同的Action 触发众多的Job,也就是一个Application 中可以有很多的Job ,每个Job 是由一个或者多个Stage 构成的,后面的Stage 依赖前面的Stage; 也就是说只有前面的依赖的Stage 计算完毕后,后面的Stage 才会运行;
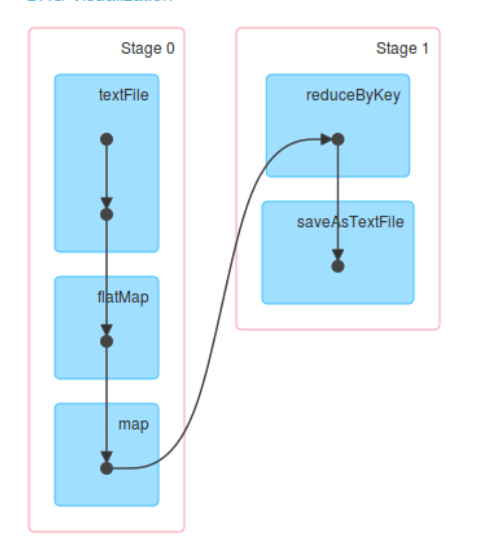
- Stage 划分的依据就是宽依赖,什么时侯产生宽依赖呢?例如 reduceByKey、groupByKey 等等;
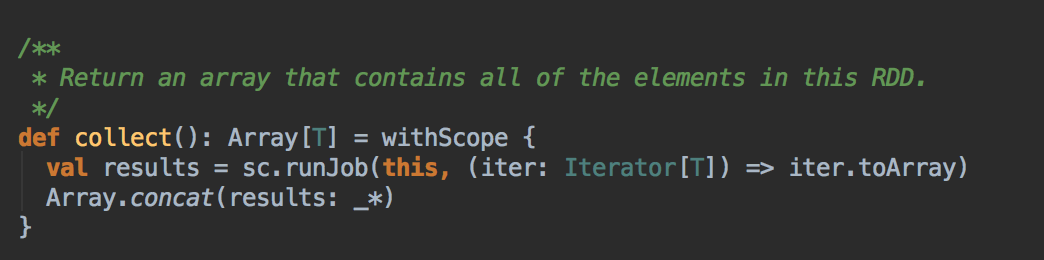
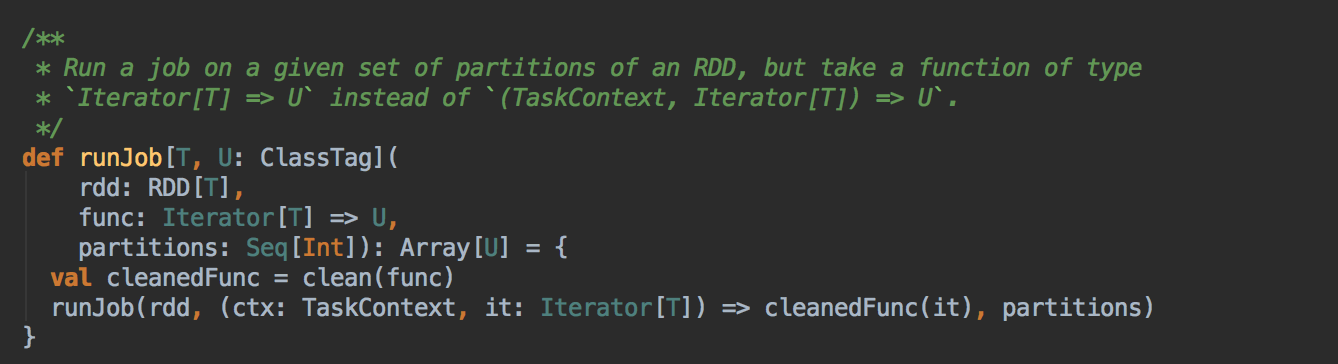
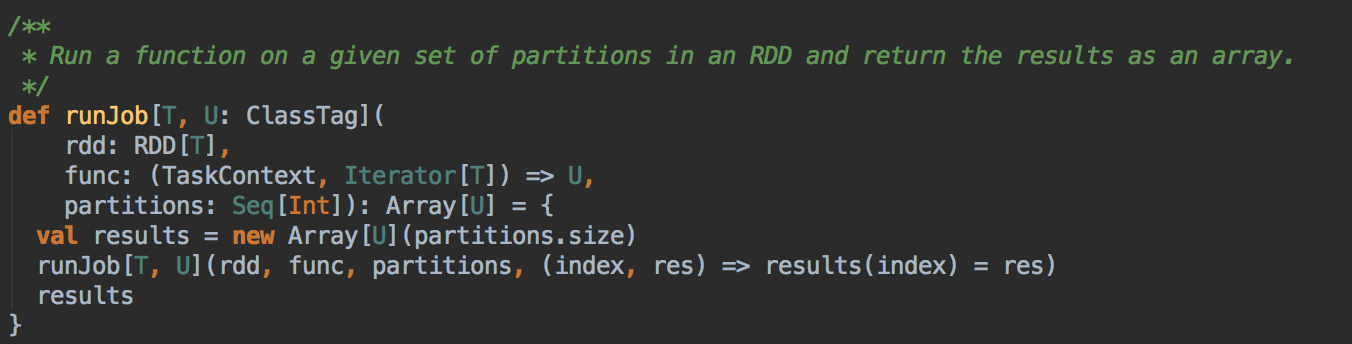
- 由 Action (例如collect) 导致了SparkContext.runJob 最终导致了 DAGScheduler 中的 submitJob 执行。

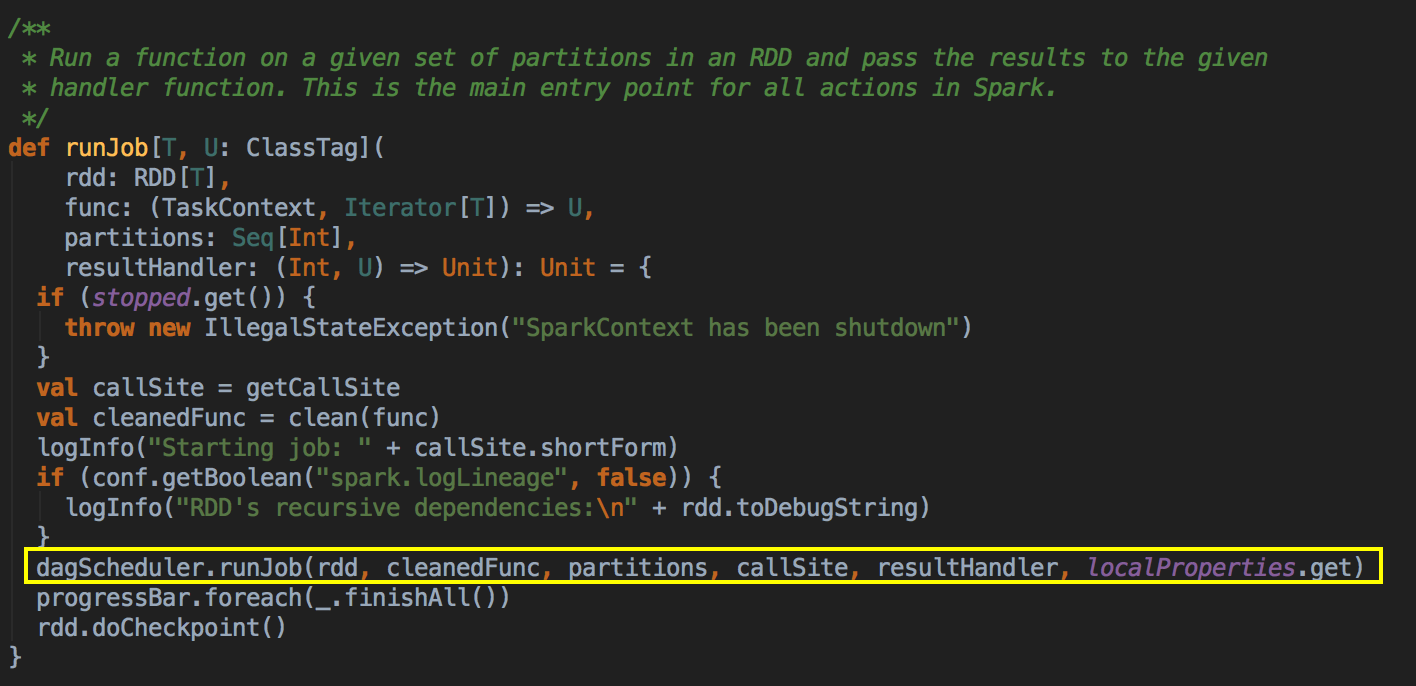
它会等待作业提交的结果,然后判断一下成功或者是失败来进行下一步操作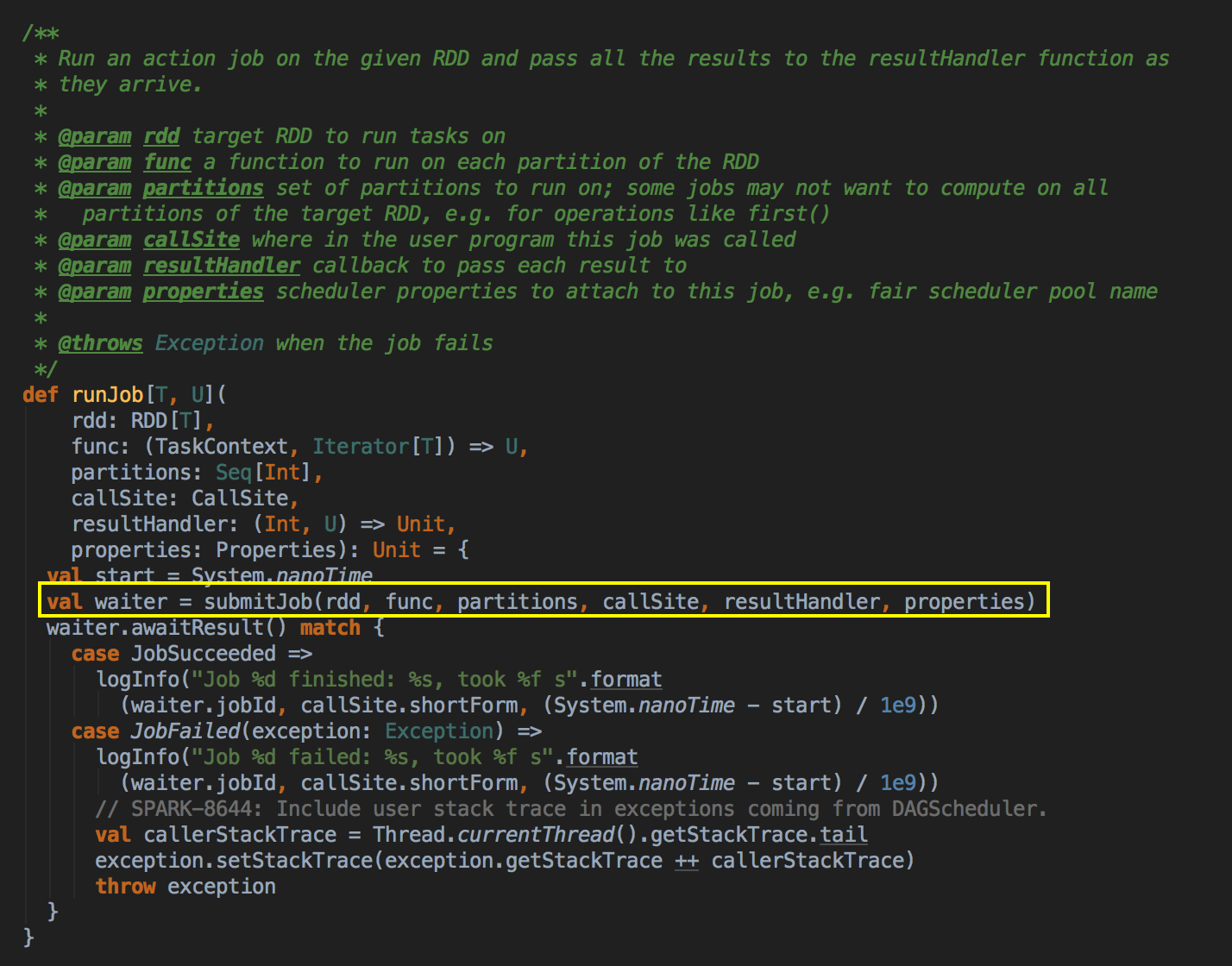
- 其核心是通过发送一个case class JobSubmitted 对象给 eventProcessLoop
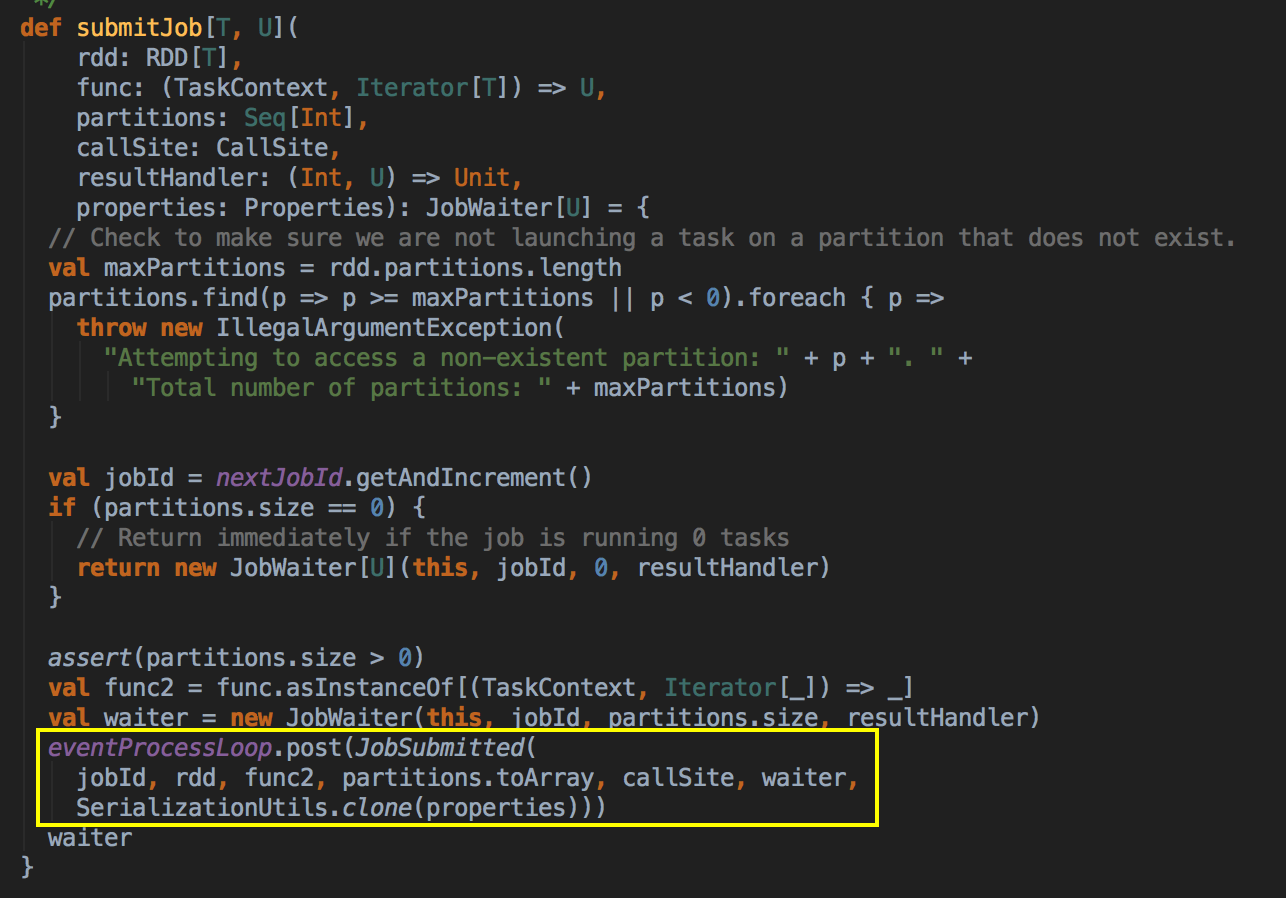
其中JobSubmitted 源码如下:因为需要创建不同的实例,所以要弄一个case class 而不是case object,case object 一般是以全区唯一的变量去使用。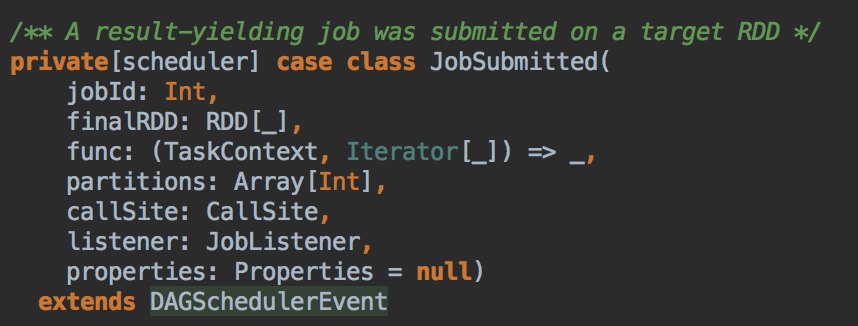
- 这里开了一条线程,用 post 的方式把消息交在队例中,由于你把它放在队例中它就会不断的循环去拿消息,它转过来就调用回调方法 onReceive( ),eventProcessLoop 是 一个消息循环器,它是 DAGSchedulerEvent 的具体实例,eventLoop 是一个 Link的blockingQueue。
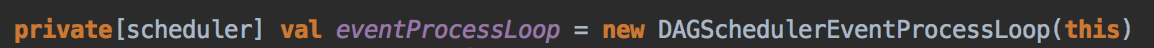

而DAGSchedulerEventProcessLoop 是 EventLoop 的子类,具体实现 eventLoop 的 onReceive 方法,onReceive方法转过来回调 doOnReceive( )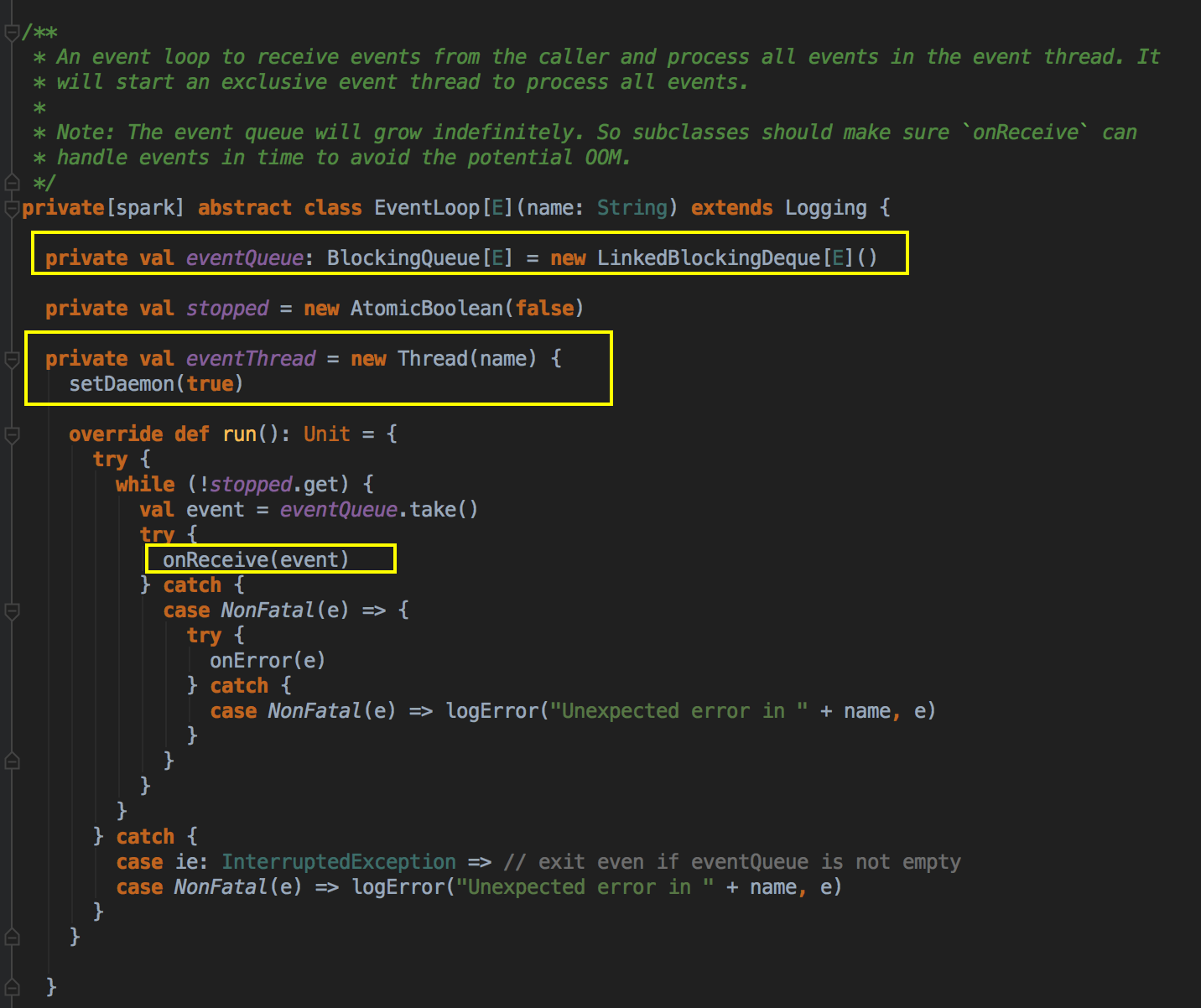
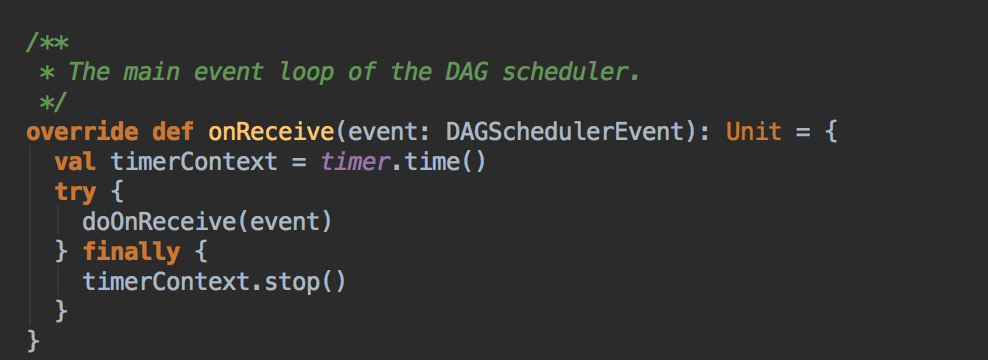
- 在 doOnReceive 这个类中有接收 JobSubmitted 的判断,转过来调用 handleJobSubmitted 的方法

思考题:为什么要再开一条线程搞一个消息循环器呢?因为有对例你就可以接受多个作业的提交,就是异步处理多 Job,这里背后有一个很重要的理念,就是如果无论是你自己发消息,还是别人发消息,你都采用一个线程去处理的话,这个时候处理的方式就是统一的,你的思路是一致的,这样你的扩展性就会非常的好,代码也会很乾净。
处理 Job 时的过程和逻辑
handleJobSubmitted( ) -->
- 调用 JobSubmitted 的方法,在这里用了一个消息循环器就可以统一对消息进行处理,在 handleJobSubmitted 中首先创建 finalStage,创建 finalStage 时会建立父 Stage 的依赖链条,这里是在这个算法里用的数据结构:

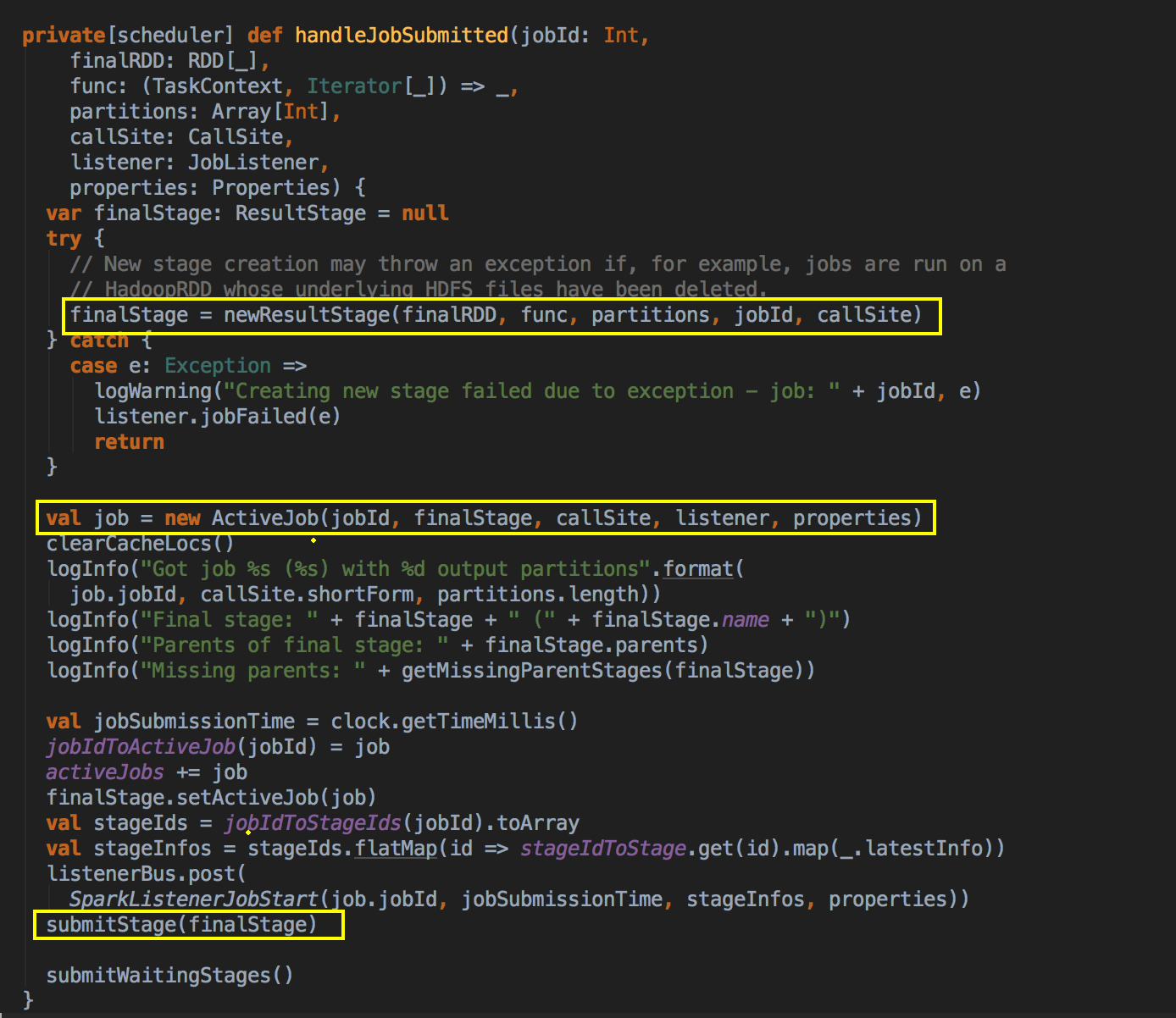

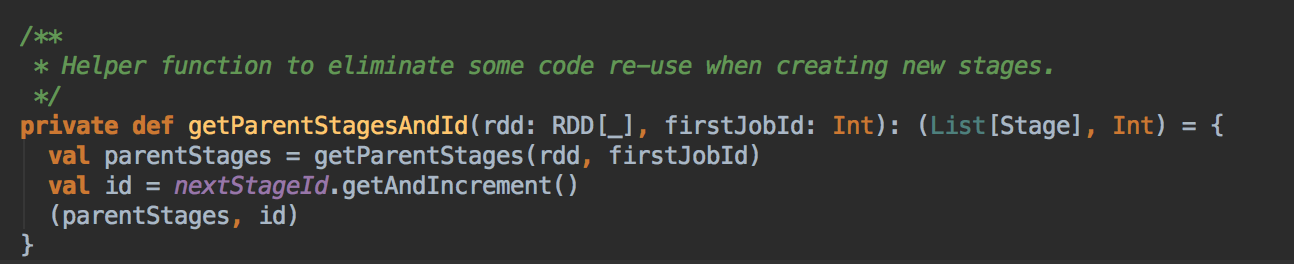
如果没有之前没有 visited 就把放在 visited 的数据结构中,然后判断一下它的依赖关系,如果是宽依赖的话就新增一个 Stage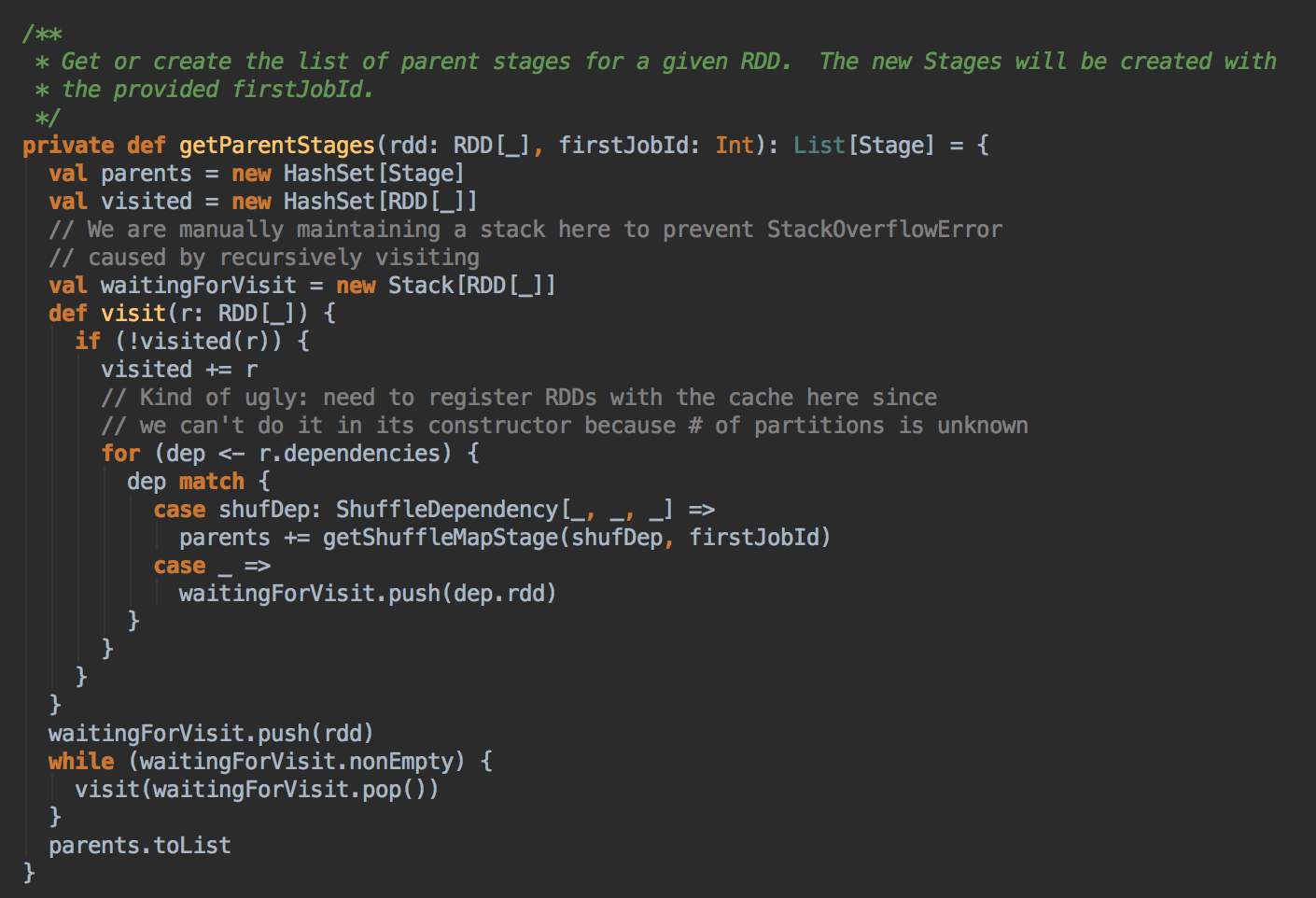
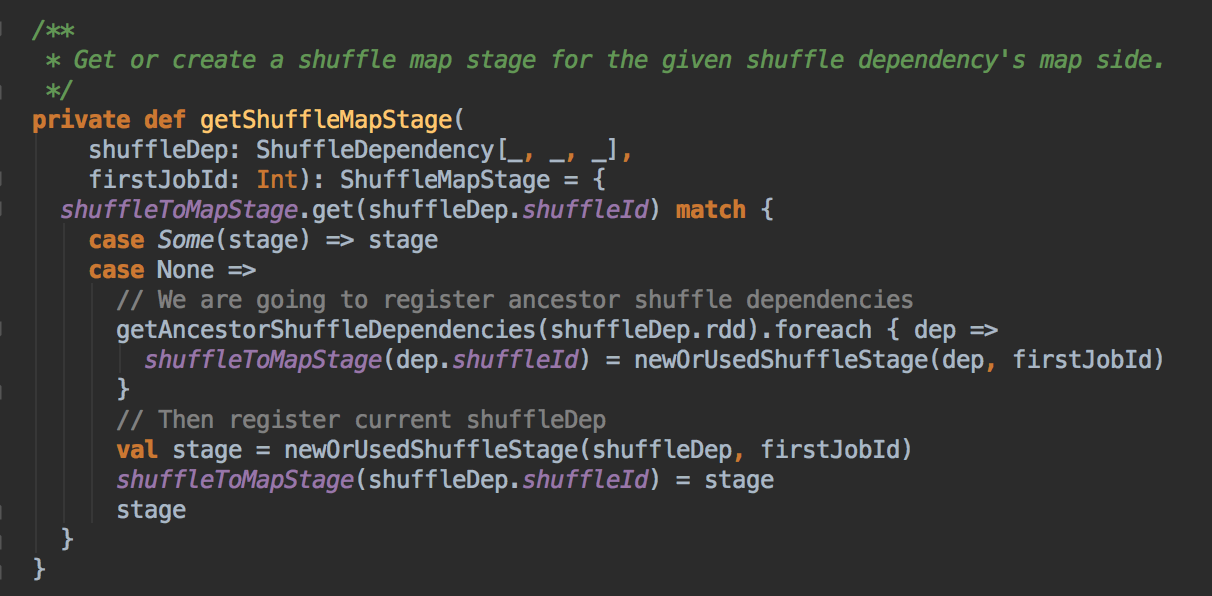
处理 missingParent
- 处理 missingParent
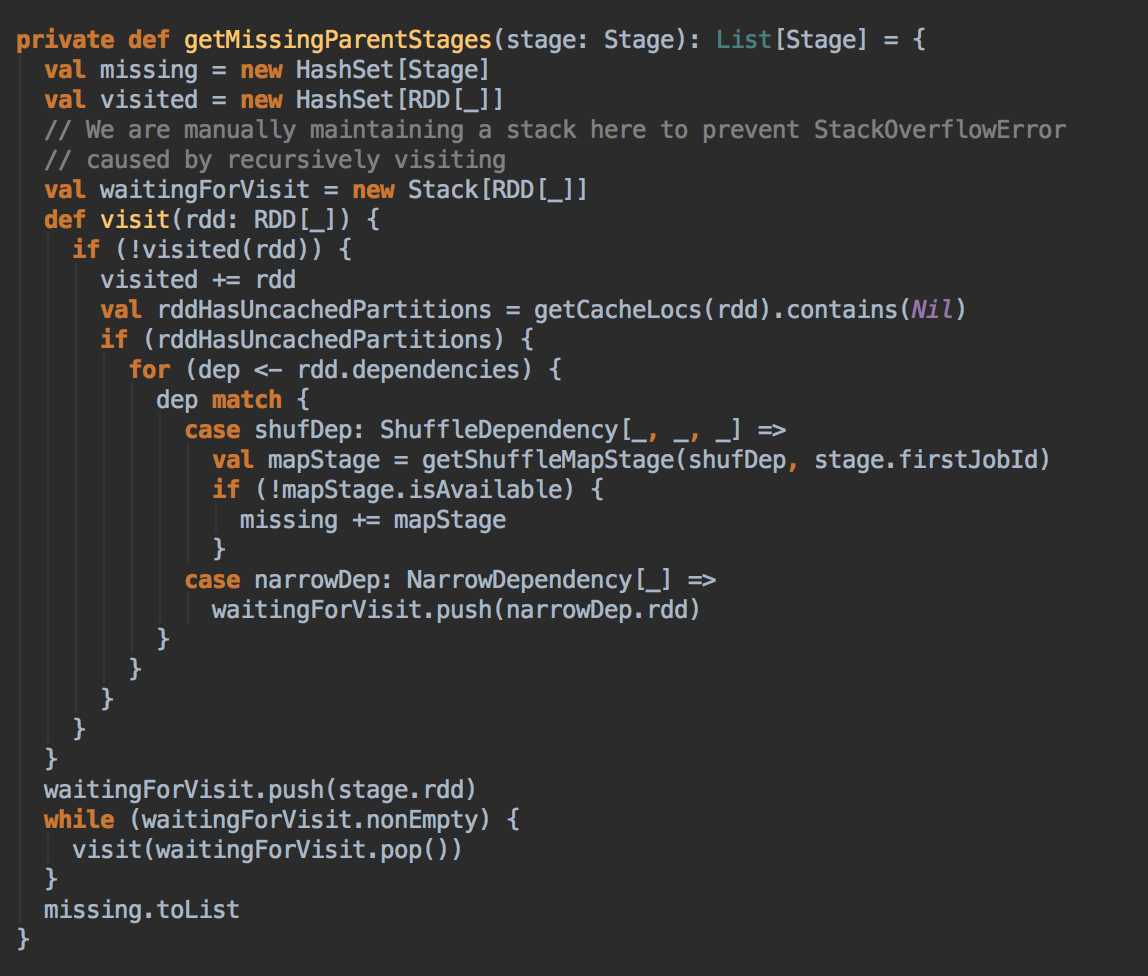
SubmitJob
- submitJob
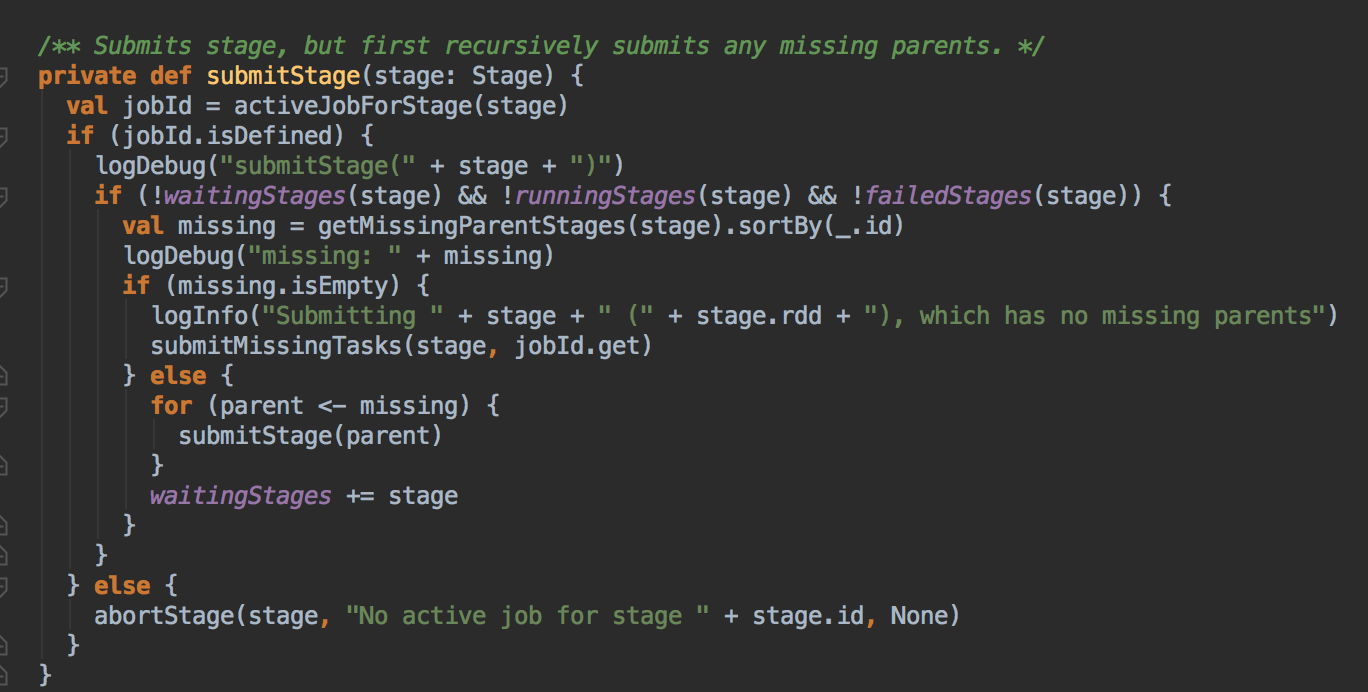
Task 最佳位置算法实现解密
- 从 submitMissingTask 开始找出它的数据本地算法
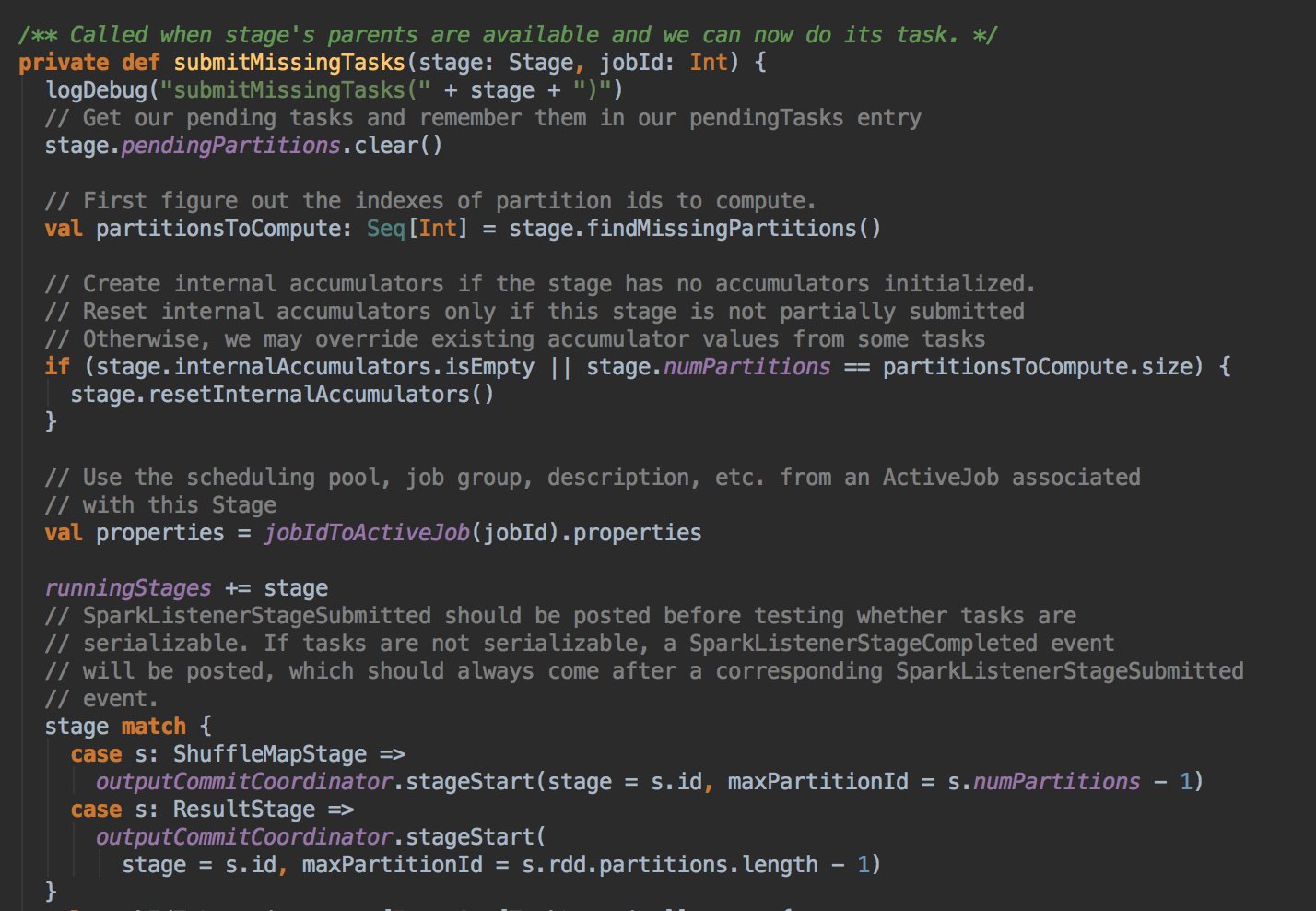
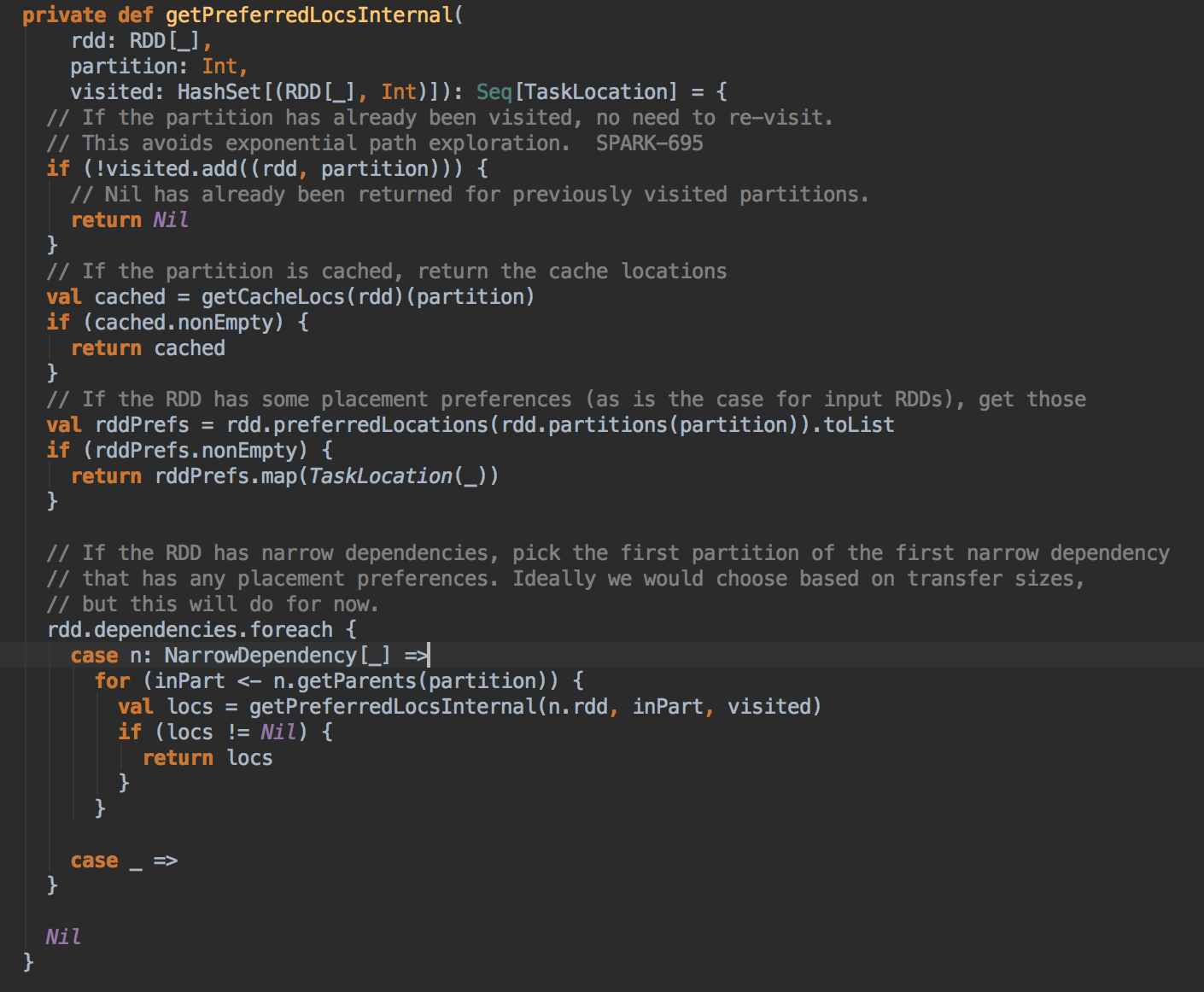
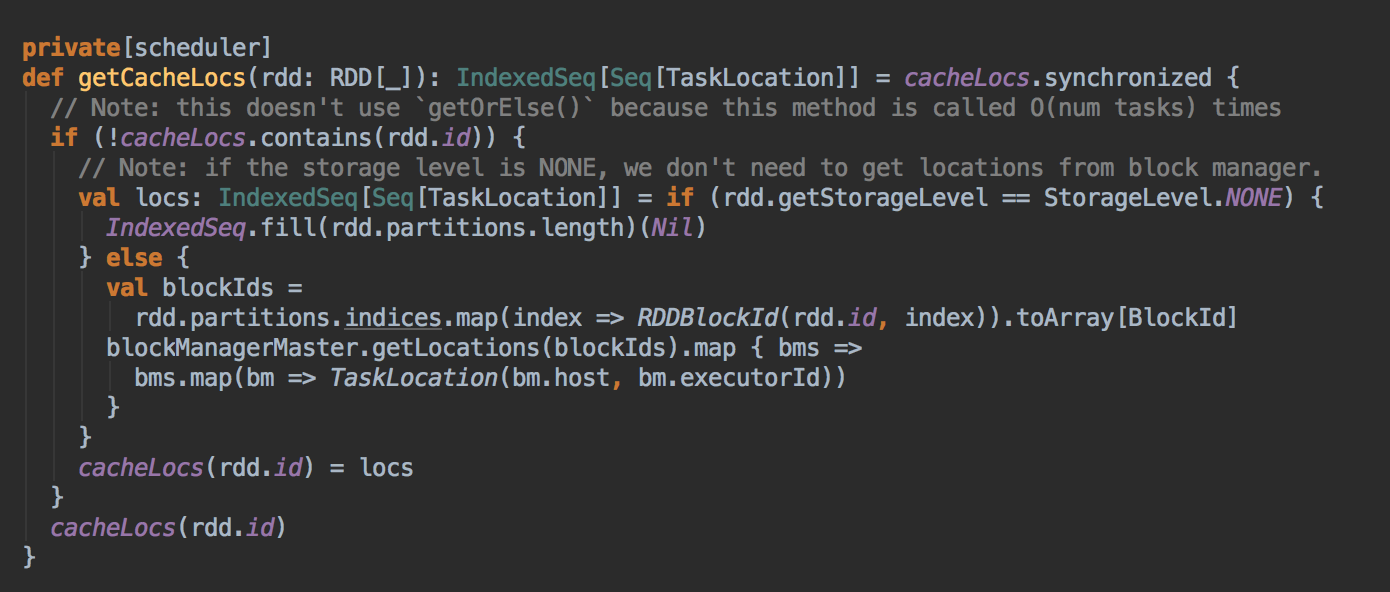
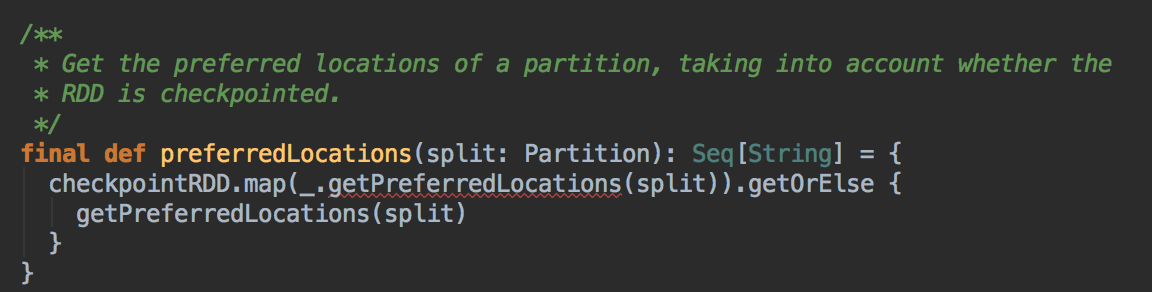
- 在具体算法实现的时候,会首先查询 DAGScheduler 的內存数据结构中是否存在当前 Partition 的数据本地性的信息,如果有得话就直接返回;如果沒有首先会调用 rdd.getPreferredLocations.例如想让 Spark 运行在 HBase 上或者一种現在还沒有直接的数据库上面,此时开发者需要自定义 RDD,为了保证 Task 数据本地性,最为关键的方法就是必需实现 RDD 的 getPreferredLocations
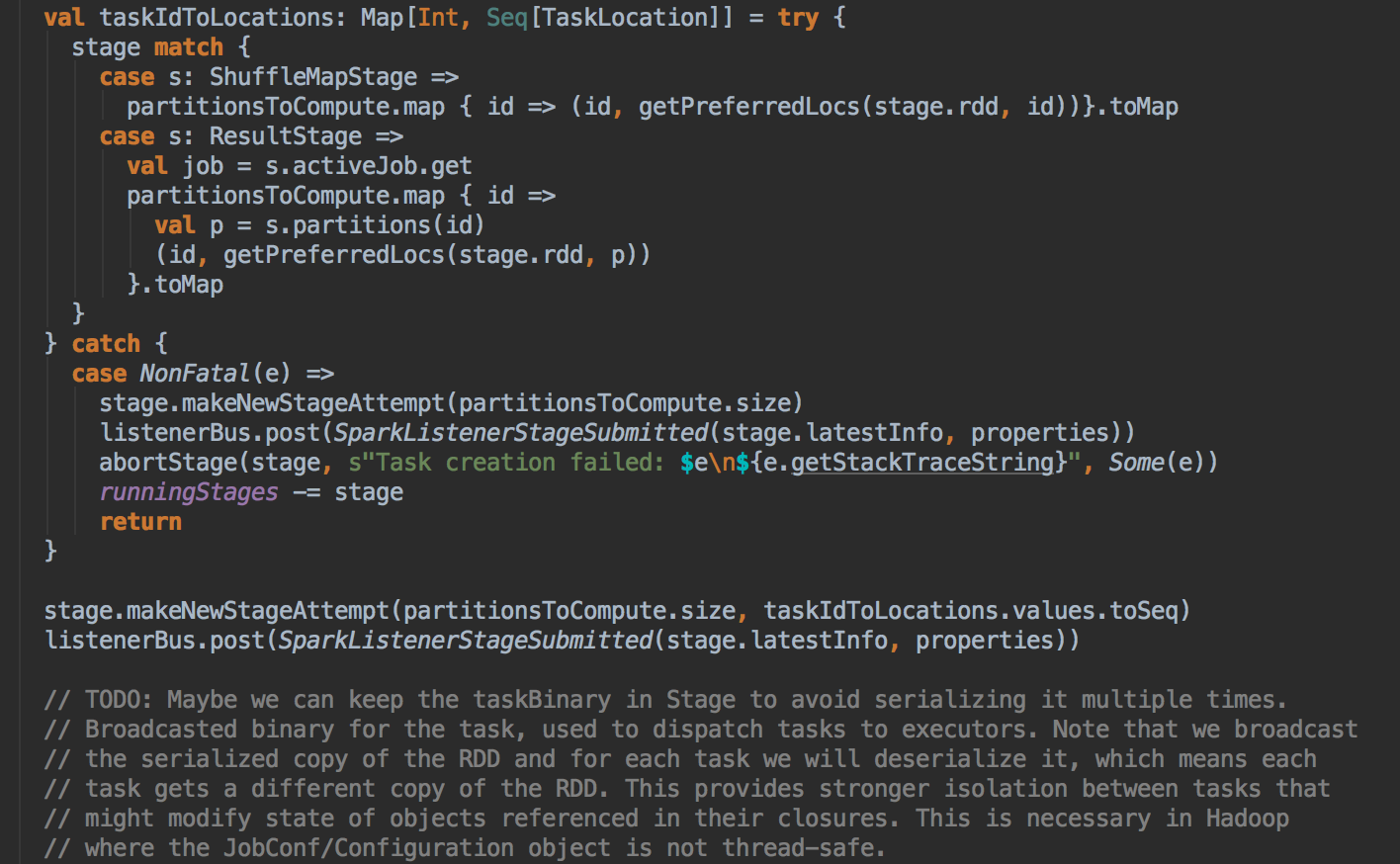
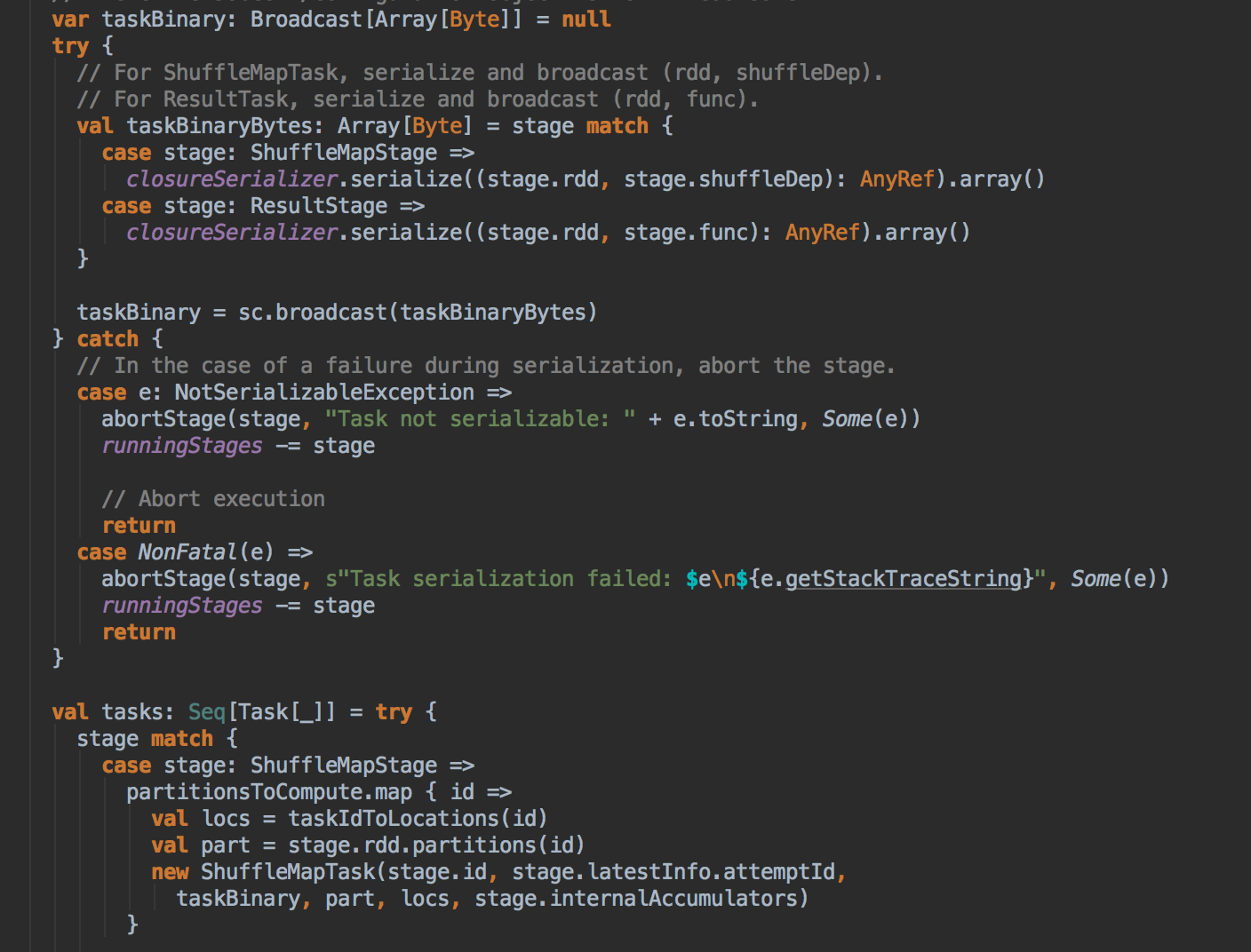
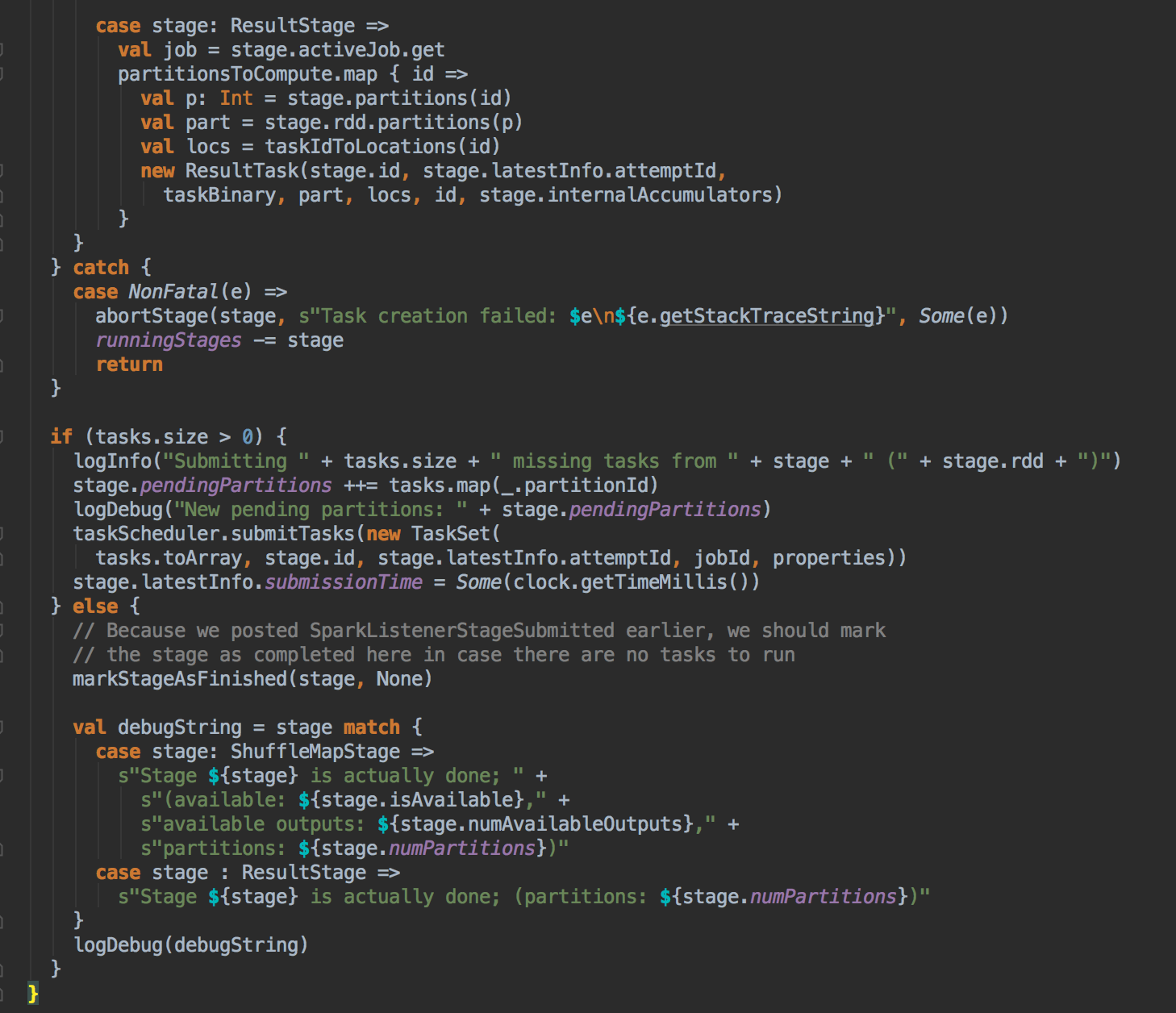

DAGScheduler 计算数据本地性的时候,巧妙的借助了RDD 自身的getPreferredLocations 中的数据,最大化的优化了效率,因为getPreferredLocations 中表明了每个Partition 的数据本地性,虽然当前Partition 可能被persists 或者是checkpoint,但是persists 或者是checkpoint默认情况下肯定是和getPreferredLocations 中的数据本地性是一致的,所以这就更大的优化了Task 的数据本地性算法的显现和效率的优化
总结
Stage划分和Task最佳位置算法源码彻底解密的更多相关文章
- [Spark内核] 第34课:Stage划分和Task最佳位置算法源码彻底解密
本課主題 Job Stage 划分算法解密 Task 最佳位置算法實現解密 引言 作业调度的划分算法以及 Task 的最佳位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心,这 ...
- Spark 源码解析:TaskScheduler的任务提交和task最佳位置算法
上篇文章< Spark 源码解析 : DAGScheduler中的DAG划分与提交 >介绍了DAGScheduler的Stage划分算法. 本文继续分析Stage被封装成TaskSet, ...
- diff.js 列表对比算法 源码分析
diff.js列表对比算法 源码分析 npm上的代码可以查看 (https://www.npmjs.com/package/list-diff2) 源码如下: /** * * @param {Arra ...
- Atitit 图像清晰度 模糊度 检测 识别 评价算法 源码实现attilax总结
Atitit 图像清晰度 模糊度 检测 识别 评价算法 源码实现attilax总结 1.1. 原理,主要使用像素模糊后的差别会变小1 1.2. 具体流程1 1.3. 提升性能 可以使用采样法即可..1 ...
- mahout算法源码分析之Collaborative Filtering with ALS-WR (四)评价和推荐
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit. 首先来总结一下 mahout算法源码分析之Collaborative Filtering with AL ...
- mahout算法源码分析之Collaborative Filtering with ALS-WR拓展篇
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit. 额,好吧,心头的一块石头总算是放下了.关于Collaborative Filtering with AL ...
- mahout算法源码分析之Collaborative Filtering with ALS-WR 并行思路
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit. mahout算法源码分析之Collaborative Filtering with ALS-WR 这个算 ...
- zookeeper集群搭建及Leader选举算法源码解析
第一章.zookeeper概述 一.zookeeper 简介 zookeeper 是一个开源的分布式应用程序协调服务器,是 Hadoop 的重要组件. zooKeeper 是一个分布式的,开放源码的分 ...
- 基于单层决策树的AdaBoost算法源码
基于单层决策树的AdaBoost算法源码 Mian.py # -*- coding: utf-8 -*- # coding: UTF-8 import numpy as np from AdaBoos ...
随机推荐
- PHP的parse_ini_file()函数,解释结构类型php.ini格式的文件
1.直接读取,返回一维数组 如: "test.ini" 的内容: [names] me = Robert you = Peter [urls] first = "http ...
- 安装并开启ssh服务
sudo yum install openssh* 安装 2. 设置 sudo vi /etc/ssh/sshd_config 首先先把port改掉port 52222 限制用户AllowUse ...
- MySql 模糊连接
我们有时候会遇到比较扯的数据库设计,也可能处于某种原因,或当时特殊考虑,情况类似如下: 表A,主键Id: 表B,关联字段 = 表A的Id的逗号连接,如:1009,2393,1235 B表的一行,对应A ...
- C#基础:传入URL,获得Http Post
#region 传入url,获得Http Post public string HttpGet(string url) { string result = string.Empty; try { va ...
- mysql-connector/python使用示例
1.下载安装connector/python 地址:https://dev.mysql.com/downloads/connector/python/ 下载的版本(mysql-connector-py ...
- redis的安全问题
1.修改redis.conf配置文件 2.重启redis服务,使其生效 3.成功登陆以后,使用auth+密码 或者在登录的时候使用-a 密码的授权方式
- MyBatis入门篇
一.什么是MyBatis MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改 ...
- How to limit Dialog's max height?
1. We can make it to play trick in code. At Dialog's show function, after app has set contentView, w ...
- php+mysql+jquery日历签到
在网站开发过程中我们会经常用到签到功能来奖励用户积分,或者做一些其他活动.这次项目开发过程中做了日历签到,因为没有经验所有走了很多弯路,再次记录过程和步骤. 1.日历签到样式: 2.本次签到只记录本月 ...
- FLASK实现上传下载功能
#!-*-coding=utf-8-*- # from flask import Flask # # app = Flask(__name__) # # # @app.route('/') # def ...