sqoop数据导入到Hdfs 或者hive
用java代码调用shell脚本执行sqoop将hive表中数据导出到mysql
http://www.cnblogs.com/xuyou551/p/7999773.html
用sqoop将mysql的数据导入到hive表中
https://www.cnblogs.com/xuyou551/p/7998846.html
1:先将mysql一张表的数据用sqoop导入到hdfs中
准备一张表

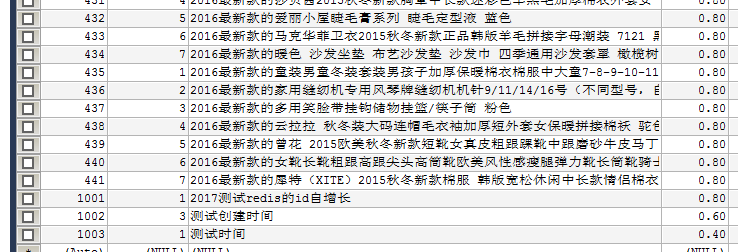
需求 将 bbs_product 表中的前100条数据导 导出来 只要id brand_id和 name 这3个字段
数据存在 hdfs 目录 /user/xuyou/sqoop/imp_bbs_product_sannpy_ 下

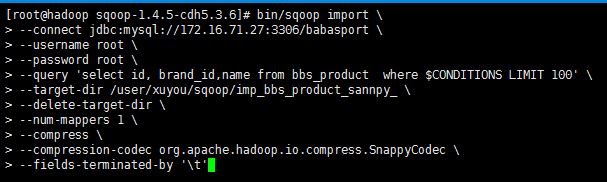
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
--target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'
ps: 如果导出的数据库是mysql 则可以添加一个 属性 --direct
1 bin/sqoop import \
2 --connect jdbc:mysql://172.16.71.27:3306/babasport \
3 --username root \
4 --password root \
5 --query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
6 --target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
7 --delete-target-dir \
8 --num-mappers 1 \
9 --compress \
10 --compression-codec org.apache.hadoop.io.compress.SnappyCodec \
11 --direct \
12 --fields-terminated-by '\t'
加了 direct 属性在导出mysql数据库表中的数据会快一点 执行的是mysq自带的导出功能
第一次执行所需要的时间

第二次执行所需要的时间 (加了direct属性)

执行成功

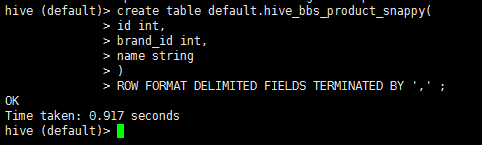
2:启动hive 在hive中创建一张表
1 drop table if exists default.hive_bbs_product_snappy ;
2 create table default.hive_bbs_product_snappy(
3 id int,
4 brand_id int,
5 name string
6 )
7 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
3:将hdfs中的数据导入到hive中
1 load data inpath '/user/xuyou/sqoop/imp_bbs_product_sannpy_' into table default.hive_bbs_product_snappy ;

4:查询 hive_bbs_product_snappy 表
1 select * from hive_bbs_product_snappy;

此时hdfs 中原数据没有了

然后进入hive的hdfs存储位置发现

注意 :sqoop 提供了 直接将mysql数据 导入 hive的 功能 底层 步骤就是以上步骤
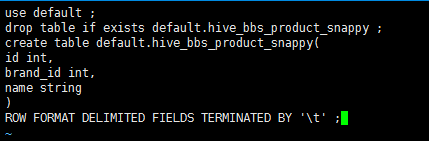
创建一个文件 touch test.sql 编辑文件 vi test.sql
1 use default;
2 drop table if exists default.hive_bbs_product_snappy ;
3 create table default.hive_bbs_product_snappy(
4 id int,
5 brand_id int,
6 name string
7 )
8 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
在 启动hive的时候 执行 sql脚本
bin/hive -f /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/test.sql


执行sqoop直接导入hive的功能
1 bin/sqoop import \
2 --connect jdbc:mysql://172.16.71.27:3306/babasport \
3 --username root \
4 --password root \
5 --table bbs_product \
6 --fields-terminated-by '\t' \
7 --delete-target-dir \
8 --num-mappers 1 \
9 --hive-import \
10 --hive-database default \
11 --hive-table hive_bbs_product_snappy
看日志输出可以看出 在执行map任务之后 又执行了load data

查询 hive 数据

sqoop数据导入到Hdfs 或者hive的更多相关文章
- Sqoop(三)将关系型数据库中的数据导入到HDFS(包括hive,hbase中)
一.说明: 将关系型数据库中的数据导入到 HDFS(包括 Hive, HBase) 中,如果导入的是 Hive,那么当 Hive 中没有对应表时,则自动创建. 二.操作 1.创建一张跟mysql中的i ...
- 使用 sqoop 将mysql数据导入到hdfs(import)
Sqoop 将mysql 数据导入到hdfs(import) 1.创建mysql表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` va ...
- sqoop数据导入命令 (sql---hdfs)
mysql------->hdfs sqoop导入数据工作流程: sqoop提交任务到hadoop------>hadoop启动mapreduce------->mapreduce通 ...
- Sqoop1.99.7将MySQL数据导入到HDFS中
准备 本示例将实现从MySQL数据库中将数据导入到HDFS中 参考文档: http://sqoop.apache.org/docs/1.99.7/user/Sqoop5MinutesDemo.html ...
- 使用Sqoop从mysql向hdfs或者hive导入数据时出现的一些错误
1.原表没有设置主键,出现错误提示: ERROR tool.ImportTool: Error during import: No primary key could be found for tab ...
- Sqoop 数据导入导出实践
Sqoop是一个用来将hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:mysql,oracle,等)中的数据导入到hadoop的HDFS中,也可以将HDFS的数据导入到 ...
- sqoop 数据导入hive
一. sqoop: mysql->hive sqoop import -m 1 --hive-import --connect "jdbc:mysql://127.0.0.1:3306 ...
- Sqoop mysql 数据导入到hdfs
1.--direct 模式使用mysqldump 工具,所以节点上需要安装该工具,非direct 模式直接使用jdbc ,所以不需要 具体script参考如下: sqoop import --conn ...
- Hadoop Hive概念学习系列之HDFS、Hive、MySQL、Sqoop之间的数据导入导出(强烈建议去看)
Hive总结(七)Hive四种数据导入方式 (强烈建议去看) Hive几种数据导出方式 https://www.iteblog.com/archives/955 (强烈建议去看) 把MySQL里的数据 ...
随机推荐
- zookeeper 事务日志与快照日志
zookeeper日志各类日志简介 zookeeper服务器会产生三类日志:事务日志.快照日志和log4j日志. 在zookeeper默认配置文件zoo.cfg(可以修改文件名)中有一个配置项data ...
- Less-mixin函数基础一
//mixin函数 立即执行mixin函数,example: .test{ color:#ff00000; background:red; } //立即执行mixin grammar 1 扩展exte ...
- python之MySQL学习——防止SQL注入(参数化处理)
import pymysql as ps # 打开数据库连接 db = ps.connect(host=', database='test', charset='utf8') # 创建一个游标对象 c ...
- window安装redis数据库
1.下载安装包 1.百度网盘链接:https://pan.baidu.com/s/1MrAK5Suc1xpzkbp1WQbP0A 提取码:u9uq 2.GitHub:https://github.co ...
- Django页面重定向
重定向分为永久性重定向和暂时性重定向,在页面上体现的操作就是浏览器会从一个页面自动跳转到另外一个页面.比如用户访问了一个需要权限的页面,但是该用户当前并没有登录,因此我们应该给他重定向到登录页面. 永 ...
- 【我的Android进阶之旅】解决MediaPlayer播放音乐的时候报错: Should have subtitle controller already set
一错误描述 二错误解决 解决方法一 解决方法二 一.错误描述 刚用MediaPlayer播放Music的时候,看到Log打印台总是会打印一条错误日志,MediaPlayer: Should have ...
- Python3+Selenium3自动化测试-(二)
python3 元素定位和操作方法总结 # coding=utf-8 ''' #8种元素定位方法 find_element_by_id() find_element_by_name() find_el ...
- EXP直接导出压缩问津,IMP直接导入压缩文件的方法
在10G之前,甚至在10G的Oracle环境中,有很多数据量不大,重要性不太高的系统依然采用EXP/IMP逻辑导出备份方式,或者,作为辅助备份方式. 通常情况下,我们都是这样操作的:1.exp导出2. ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- Linux Shell编程第2章——Linux文件系统
目录 用户和用户组管理 用户管理常用命令 用户组管理常用命令 文件和目录操作 文件操作常用命令 目录操作常用命令 文件和目录权限管理 文件查找--find 用户和用户组管理 用户管理常用命令 用户的角 ...