[DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化
觉得有用的话,欢迎一起讨论相互学习~Follow Me
1.10 梯度消失和梯度爆炸
当训练神经网络,尤其是深度神经网络时,经常会出现的问题是梯度消失或者梯度爆炸,也就是说当你训练深度网络时,导数或坡度有时会变得非常大,或非常小,甚至以指数方式变小.这加大了训练的难度.
假设你正在训练一个很深的神经网络,并且将其权重命名为"W[1],W[2],W[3],W[4]......W[L]"

为了简化说明,我们选择激活函数为g(z)=z(线性激活函数),b[l]=0(即忽略偏置对神经网络的影响)
这样的话,输出\(\hat{y}=w[l]*w[l-1]*w[l-2]...w[2]*w[1]*x\)
假设每层的W的值相等都为:\(\begin{bmatrix}1.5&0\\0&1.5\\\end{bmatrix}\)
从技术上讲第一层的权值可能不同,基于此我们有式子\(\hat{y}=w[1]*\begin{bmatrix}1.5&0\\0&1.5\\\end{bmatrix}^{L-1}*x\)
对于一个深层神经网络来说层数L相当大,也就是说预测值\(\hat{y}\)实际上是以指数级增长的,它增长的比率是\(1.5^L\),因此对于一个深层神经网络来说,y的值将爆炸式增长.相反的,如果权重是0.5,有\(\hat{y}=w[1]*\begin{bmatrix}0.5&0\\0&0.5\\\end{bmatrix}^{L-1}*x\) 因此每个矩阵都小于1,假设x[1]x[2]的输入值都是1,那么激活函数值到最后会变成\(0.5^{(L-1)}\)激活函数值将会以指数级别下降.
对于深层神经网络最终激活值的直观理解是,以上述网络结构来看,如果每一层W只比1大一点,最终W会爆炸级别增长,如果只比W略微小一点,在深度神经网络中,激活函数将以指数级递减.
虽然只是论述了对于最终激活函数输出值将以指数级别增长或下降,这个原理也适用与层数L相关的导数或梯度函数也是呈指数增长或呈指数递减
直观上理解,梯度消失会导致优化函数训练步长变小,使训练周期变的很长.而梯度爆炸会因为过大的优化幅度而跨过最优解
ps: 对于该视频中关于梯度消失和梯度爆炸的原理有一些争论
请参考
1.11 神经网络中的权重初始化
对于梯度消失和梯度爆炸的问题,我们想出了一个不完整的解决方案,虽然不能彻底解决问题但却很有用,有助于我们为神经网络更谨慎的选择随机初始化参数
单个神经元权重初始化
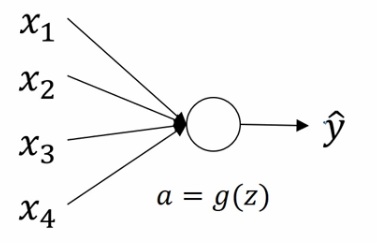
假设神经元有四个特征输入,暂时忽略b对神经元的作用则:\(z=w_{1}x_{1}+w_{2}x_{2}+w_{3}x{3}+...+w_{n}x_{n}\)
为了防止梯度爆炸或者梯度消失,我们希望\(w_{i}\)尽可能小,最合理的方法就是设置\(W方差为\frac{1}{n}\) n表示神经元的输入特征数量
更简洁的说,如果你用的是Sigmoid函数,设置某层权重矩阵\(W^{[l]}=np.random.randn(shape)*np.sqrt(\frac{1}{n^{[l-1]}})(该层每个神经元的特征数量分之一,即l层上拟合的单元数量)\)
如果你用的是ReLU激活函数,设置方差为\(\frac{2}{n}\)更好,更简洁的说,就是设置某层权重矩阵\(W^{[l]}=np.random.randn(shape)*np.sqrt(\frac{2}{n^{[l-1]}})(该层每个神经元的特征数量分之一,即l层上拟合的单元数量)\)
如果你用的是Tanh激活函数,则设置某层权重矩阵为\(W^{[l]}=np.random.randn(shape)*np.sqrt(\frac{1}{n^{[l-1]}})\)或者为\(W^{[l]}=np.random.randn(shape)*np.sqrt(\frac{2}{n^{[l-1]}+n^{l}})\)
这些方法都被成为Xavier 初始化(Xavier initialization),实际上,NG认为所有这些公式都只是给你一个起点,它们给出初始化权重矩阵的方差的默认值,如果你想添加方差,则方差参数则是另一个你需要调整的超级参数,例如对于ReLU激活函数而言,你可以尝试给公式\(W^{[l]}=np.random.randn(shape)*np.sqrt(\frac{2}{n^{[l-1]}})\)添加一个乘数参数,但是NG认为相对于其他参数的调优,通常把它的调优优先级放得比较低.
1.12 梯度的数值逼近
主要讲利用双边误差计算公式:
\[\frac{f(\theta+\epsilon)-f(\theta-\epsilon)}{2\epsilon}\approx{g(\theta)}\]
利用这个公式简单的估计函数的微分.
补充资料
[DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.9_归一化normalization
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.9 归一化Normaliation 训练神经网络,其中一个加速训练的方法就是归一化输入(normalize inputs). 假设我们有一个 ...
- deeplearning.ai 改善深层神经网络 week1 深度学习的实用层面 听课笔记
1. 应用机器学习是高度依赖迭代尝试的,不要指望一蹴而就,必须不断调参数看结果,根据结果再继续调参数. 2. 数据集分成训练集(training set).验证集(validation/develop ...
- deeplearning.ai 改善深层神经网络 week1 深度学习的实用层面
1. 应用机器学习是高度依赖迭代尝试的,不要指望一蹴而就,必须不断调参数看结果,根据结果再继续调参数. 2. 数据集分成训练集(training set).验证集(validation/develop ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.1_2.2_mini-batch梯度下降法
觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.1 mini-batch gradient descent mini-batch梯度下降法 我们将训练数据组合到一个大的矩阵中 \(X=\b ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.3_2.5_带修正偏差的指数加权平均
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.3 指数加权平均 举个例子,对于图中英国的温度数据计算移动平均值或者说是移动平均值( ...
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- [DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习使用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 训练/开发/测试集 对于一个数据集而言,可以将一个数据集分为三个部分,一部分作为训练集,一部分作为简单交叉验证集(dev)有时候也成为验 ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
随机推荐
- 从好用到更好用 —— 2017 年又拍云 CDN 功能更新回顾
又拍云一直致力于为客户带来更好的服务,在 2017 年又拍云 CDN 服务进行了数次重大更新,在功能上更加全面.完善,进一步提升了 CDN 的稳定性与安全性. 在过去一年里又拍云 CDN 服务共进行了 ...
- BZOJ 1207: [HNOI2004]打鼹鼠【妥妥的n^2爆搜,dp】
1207: [HNOI2004]打鼹鼠 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 3259 Solved: 1564[Submit][Statu ...
- three.js 入门案例
最近公司需要用tree.js实现一个3D图的显示,就看了官方文档,正好有时间,就记录下来. 由于我们公司的前端框架用的是angular,所以我就把我的treejs封装在一个directives里面.后 ...
- 微信小程序监听input输入并取值
小程序的事件分为两种,冒泡和非冒泡事件,像<form/>的submit事件,<input/>的input事件,<scroll-view/>的scroll事件等非冒泡 ...
- [国嵌攻略][066][ARP协议实现]
以太网通讯 在计算机网络中,数据发送的过程就是把数据按照各层协议层层封装的过程.在这个过程中,最终要使用的协议通常是以太网协议(数据链路层协议). 以太网包格式 目的MAC地址:接收者的物理地址(6字 ...
- Kafka集群的搭建
Kafka集群的搭建 node1 node2 node3 kafka须用版本(kafka-0.8.2.2),否则不兼容spark1.6 1.启动zookeeper集群node1 node2 ...
- 《You dont know JS》值相关总结
值 一:和数组相关的几个需要关注的点 数组可以容纳任何类型的值. 数组声明时不需要预先设置大小.可以动态改变. 使用delete运算符可以将数组中的某个元素删除,但是这个操作不会改变数组的length ...
- Asp.net mvc 中的路由
在 Asp.net mvc 中,来自客户端的请求总是针对某个 Controller 中的 Action 方法,因此,必须采用某种机制从请求的 URl 中解析出对应的 Controller 和 Acti ...
- asp.net -mvc框架复习(1)-ASP.NET网站开发概述
1.网站开发的基本步骤: 2.网站开发的需要的知识结构 (1)网站开发前台页面技术 页面设计:HTML .CSS+DIV 页面特效:JavaScript.jQery (2)OOP编程核心公共技能 C ...
- 给外行或者刚入门普及一下关于C#,.NET Framework(.NET框架),.Net,CLR,ASP,ASP.Net, VS,以及.NET Core的概念
一.概念 1. C# :C#是微软公司发布的一种面向对象的.运行于.NET Framework之上的高级程序设计语言. 2..NET Framework(.NET框架):.NET framework ...