c#抽取pdf文档标题(1)
首先看看我的项目结构:

从上面的结果图中,我们可以看出,主要用了两个库:itextsharp.dll 和 pdfbox-1.8.9.dll,dll文件夹存放引用的库,handles文件夹存放抽取的处理代码,lib文件夹中,相当于数据库中的DBHelp类的作用。model文件夹就不用介绍了,大家都知道。
我们从大的逻辑开始介绍,TitleHandle类中有一个方法:

从此方法可以看出,它接收两个参数:block和isTrainModel,返回 HandleResult类型。
我们先来看看Block的定义:

块由行构成,我们再看看Line的定义:

行由单词构成,再来看Word定义:
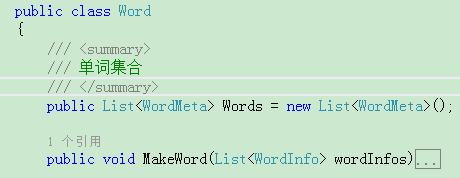
它其实是一个词的集合,WordMeta是一个单词的信息,它下面还有一层结构 WordInfo类,这个类是最基础的类,它代表了pdf文档中一个字符信息,底层基础决定上层建筑:
public class WordInfo
{
/// <summary>
/// x坐标
/// </summary>
public float X { set; get; }
/// <summary>
/// y坐标
/// </summary>
public float Y { set; get; } public int XSize { set; get; } public int YSize { get; set; } public float XDirAdj { set; get; } public float YDirAdj { set; get; } /// <summary>
/// 字号
/// </summary>
public float FontSize { set; get; } public float Xscale { set; get; } public float Yscale { set; get; }
/// <summary>
/// 高度
/// </summary>
public float Height { set; get; } /// <summary>
/// 空格大小
/// </summary>
public float Space { set; get; }
/// <summary>
/// 宽度
/// </summary>
public float Width { set; get; }
/// <summary>
/// 子字体
/// </summary>
public string Subfont { set; get; }
/// <summary>
/// 基本字体
/// </summary>
public string Basefont { set; get; }
/// <summary>
/// 是否加粗
/// </summary>
public bool IsBold { set; get; }
/// <summary>
/// 是否倾斜
/// </summary>
public bool IsItalic { set; get; }
/// <summary>
/// 单词
/// </summary>
public string Word { set; get; } public override string ToString()
{
return "String[" + this.XDirAdj + ","
+ this.YDirAdj
+ " fs=" + this.FontSize
+ " xscale=" + this.Xscale
+ " isBold=" + this.IsBold
+ " space=" + this.Space
+ " isItalic=" + this.IsItalic
+ "xSize" + this.XSize
+ "ySize" + this.YSize
+ " width=" + this.Width + "]"
+ this.Word;
}
/// <summary>
/// 计算当前字符和lastChunk的距离
/// </summary>
/// <param name="lastChunk"></param>
/// <returns></returns>
public float DistanceFromEndOf(WordInfo lastChunk)
{
return this.X - lastChunk.X - lastChunk.Width;
} }
这个类包括了字符的位置,大小,粗细等等信息。这些信息是基础当中的基础,因此非常重要,给我们判断一个块是否是标题,提供了依据,相当于国之宪法。
从我解剖出来的结构看,解析出pdf标题,关键有两点:
第一,如何正确地划分块,把具有相同格式的多行文字划分到一个块中,这样就形成了一个块的字典集合,也就是Block类中的字典类型:Dictionary<int, List<WordMeta>>。
分块也有难点,有很多上标和下标的句子,也有很多非常相似的块,可能分错。比如标题的块和作者的块,文字格式如果非常接近的话,就很容易把作者和标题划分到同一个块中,这给后面的工作带来了麻烦,以至于提取了错误的标题。
第二,如何从众多的块中筛选出标题。
此处也采取了很多筛选策略。
1、根据块长度,淘汰字符长度太短的。
2、根据块位置,淘汰位置太偏的。
3、评分机制,根据块的特征信息,计算出一个0-1之间的数值来,然后选取第一名和第二名的块。
4、在第一名和第二名之间选择。根据它们的位置,字符长度,分值,块的高度,块所包含的单词数等来判断。
c#抽取pdf文档标题(1)的更多相关文章
- c#抽取pdf文档标题——前言
由于工作的需要,研究c#抽取pdf文档标题有3个月了.这项工作是一项"伟大而艰巨"的任务.应该是我目前研究工作中最长的一次.我觉得在长时间忙碌后,应该找些时间,把自己的心路历程归纳 ...
- c#抽取pdf文档标题(3)
上一篇介绍了整体流程以及利用库读取pdf内容形成字符集合.这篇着重介绍下,过滤规则,毕竟我们是使用规则过滤,最后得到标题的. 首先看归一化处理,什么是归一化呢?就是使结果始终处于0-1之间(包括0,1 ...
- c#抽取pdf文档标题(2)
public class IETitle { public static List<WordInfo> WordsInfo = new List<WordInfo>(); pr ...
- c#抽取pdf文档标题(4)——机器学习以及决策树
我的一位同事告诉我,pdf抽取标题,用机器学习可以完美解决问题,抽取的准确率比较高.于是,我看了一些资料,就动起手来,实践了下. 我主要是根据以往历史块的特征生成一个决策树,然后利用这棵决策树,去判断 ...
- Python处理Excel和PDF文档
一.使用Python操作Excel Python来操作Excel文档以及如何利用Python语言的函数和表达式操纵Excel文档中的数据. 虽然微软公司本身提供了一些函数,我们可以使用这些函数操作Ex ...
- C#给PDF文档添加文本和图片页眉
页眉常用于显示文档的附加信息,我们可以在页眉中插入文本或者图形,例如,页码.日期.公司徽标.文档标题.文件名或作者名等等.那么我们如何以编程的方式添加页眉呢?今天,这篇文章向大家分享如何使用了免费组件 ...
- 将w3cplus网站中的文章页面提取并导出为pdf文档
最近在看一些关于CSS3方面的知识,主要是平时看到网页中有很多用CSS3实现的很炫的效果,所以就打算系统的学习一下.在网上找到很多的文章,但都没有一个好的整理性,比较凌乱.昨天看到w3cplus网站中 ...
- PDF2SWF转换只有一页的PDF文档,在FlexPaper不显示解决方法
问题:PDF2SWF转换只有一页的PDF文档,在FlexPaper不显示! FlexPaper 与 PDF2SWF 结合是解决在线阅读PDF格式文件的问题的,多页的PDF文件转换可以正常显示,只有一页 ...
- 【PDF】java使用Itext生成pdf文档--详解
[API接口] 一.Itext简介 API地址:javadoc/index.html:如 D:/MyJAR/原JAR包/PDF/itext-5.5.3/itextpdf-5.5.3-javadoc/ ...
随机推荐
- 原生Java代码拷贝目录
拷贝.移动文件(夹),有三方包commons-io可以用,但是有时候有自己的需求,只能使用原生java代码,这时可以用以下几种方式进行拷贝: 1.使用系统命令(Linux)调用 此种方式对操作系统有要 ...
- 应用负载均衡之LVS(三):使用ipvsadm以及详细分析VS/DR模式
*/ .hljs { display: block; overflow-x: auto; padding: 0.5em; color: #333; background: #f8f8f8; } .hl ...
- alter 和 update的区别?
alter用来增加或者减少列,alter stuednt add name vachar2(30): update用来更改表中的数据:update student set sutudent.name ...
- SSRF漏洞总结
SSRF漏洞:(服务端请求伪造)是一种由攻击者构造形成由服务端发起请求的一个安全漏洞.一般情况下,SSRF攻击的目标是从外网无法访问的内部系统.(正是因为它是由服务端发起的,所以它能够请求到与它相连而 ...
- (转载)SVM-基础(五)
作为支持向量机系列的基本篇的最后一篇文章,我在这里打算简单地介绍一下用于优化 dual 问题的 Sequential Minimal Optimization (SMO) 方法.确确实实只是简单介绍一 ...
- Jmeter MD5插件
实际业务中,会要求 HTTP 协议中附加 MD5 校验字段, 防止请求参数被恶意篡改, 对于开发同学来说, 这是个很简单的需求. 但是给自动化测试增加了难度, Jmeter 原生不支持这个功能,应测试 ...
- linux 集群及lvs
集群及LVS 集群: 一组通过高速网络互联的计算机组,并以单一系统的模式加以管理 价格很多服务器集中起来,提供同一种服务,在客户端看起来就像只有一个服务器 可以在付出较低成本的情况下获得在性能,可靠性 ...
- 3.1 PCI设备BAR空间的初始化
在PCI Agent设备进行数据传送之前,系统软件需要初始化PCI Agent设备的BAR0~5寄存器和PCI桥的Base.Limit寄存器.系统软件使用DFS算法对PCI总线进行遍历时,完成这些寄存 ...
- Caused by: java.lang.ClassNotFoundException: Could not load requested class : org.h2.Driver
1.错误描述 WARN:2015-05-01 13:26:10[localhost-startStop-1] - HHH000402: Using Hibernate built-in connect ...
- gstreamer在Ubuntu下构建开发环境
1,Ubuntu已经安装了gstreamer库,因此只需要再安装几个开发库即可,是 libstreamer0.-libstreamer0.-devlibstreamer0.--dbg 在新立得里选中应 ...