利用 pyspider 框架抓取猫途鹰酒店信息
利用框架 pyspider 能实现快速抓取网页信息,而且代码简洁,抓取速度也不错。
环境:macOS;Python 版本:Python3。
1.首先,安装 pyspider 框架,使用pip3一键安装:
pip3 pyspider
2.终端输入 pyspider all 启动 pyspider:
打开 Chrome,地址栏输入 localhost:5000 进入 pyspider 框架的webui界面。
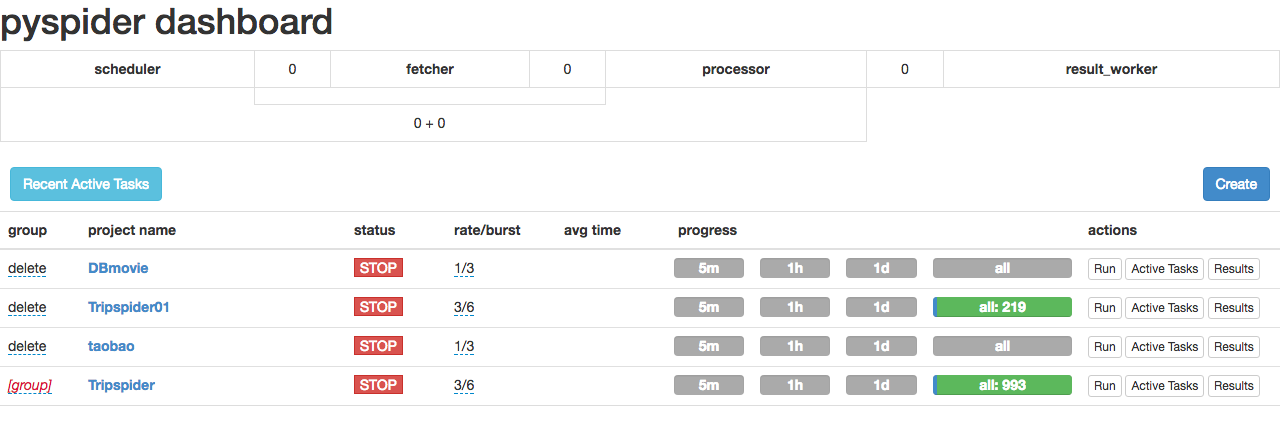
点击 create ,创建 一个新的project。
3.创建完 project 后,我们便进入了代码调试界面。
这次我们要抓取的信息是猫途鹰网关于布拉格的酒店信息,把网址填入 on_star 一栏并替换掉 on_star , 点击 save 保存,点击左上角 run 选项,然后点击出现的网址右侧的箭头的选项:
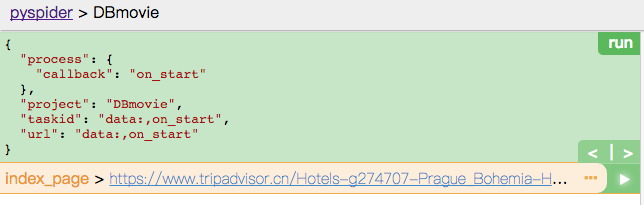
便出现 index_page 的页面,我们点击 web 选项卡,出现网页内容后点击 enable css selector helper ,选中酒店标题的超链接,这时上方便出现该标题的 CSS 选择器,把选择器内容复制粘贴替换掉右侧代码中的 a[href^="http"] ,save 后再次点击 run,但是 pyspider 的选择器并不一定准确,需要自己随时更改。这时我们便得到了我们想要的酒店标题超链接。
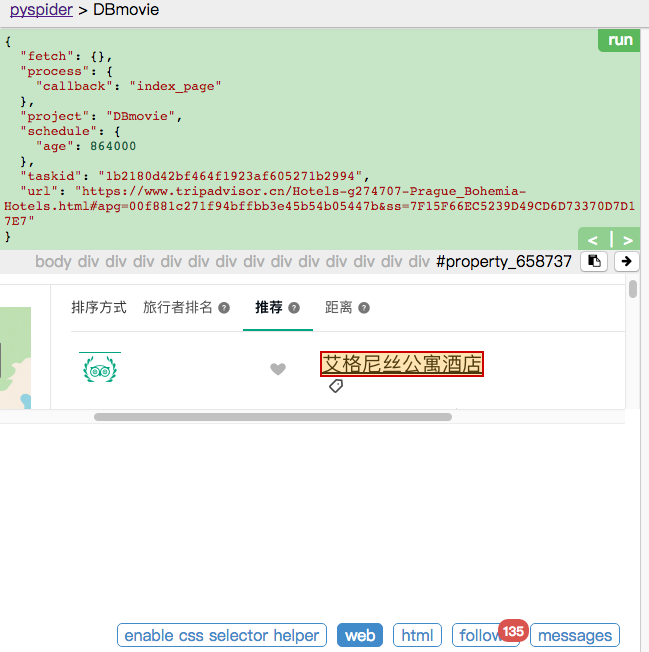
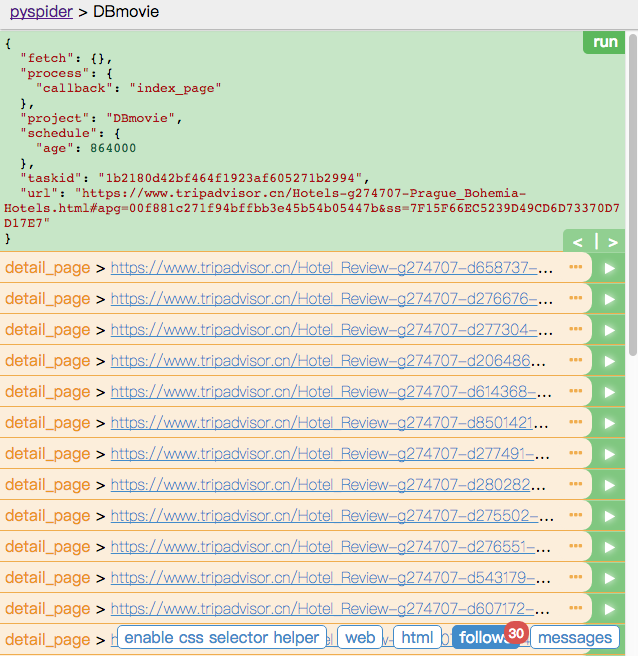
4.点击其中一个网页的右边的小箭头,进入详情页界面,我们要获取的信息便是详情页中的内容。类似的用 CSS 选择器获取酒店的信息,写入代码如下:
def detail_page(self, response):
url = response.url
name = response.doc('.heading_title').text()
rating = response.doc('.header_rating .taLnk').text()
ranking = response.doc('.prw_common_header_pop_index > span').text()
location = response.doc('.colCnt3').text()
phone = response.doc('.blEntry.phone > span:nth-child(2)').text()
grade = response.doc('.overallRating').text()
return {
"url": url,
"name": name,
"rating": rating,
"ranking": ranking,
"location": location,
"phone": phone,
"grade": grade }
便返回酒店链接,名称,点评,排名,地址,电话,评分这七个信息,保存后点击 run,我们便能看到打印的信息。
5.存储信息到 MongoDB:
import pymongo
client = pymongo.MongoClient('localhost')
db = client['trip']
def on_result(self, result):
if result:
self.save_to_mongo(result)
def save_to_mongo(self, result):
if self.db['布拉格'].insert(result):
print('存储到 MongoDB 成功', result)
6.模拟翻页抓取多页面:
在 index_page(self, response) 函数中插入:
next = response.doc('.pagination .nav.next').attr.href
self.crawl(next, callback=self.index_page)
7.到这时,我们代码便写完了,退出 project ,在控制面板中 status 栏更改方式为 DEBUG ,点击 run,运行代码,Active Tasks 可以查看当前任务。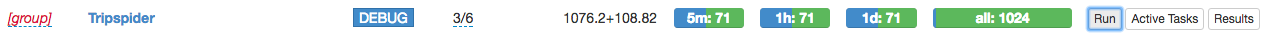
8.存储到MongoDB 的信息。
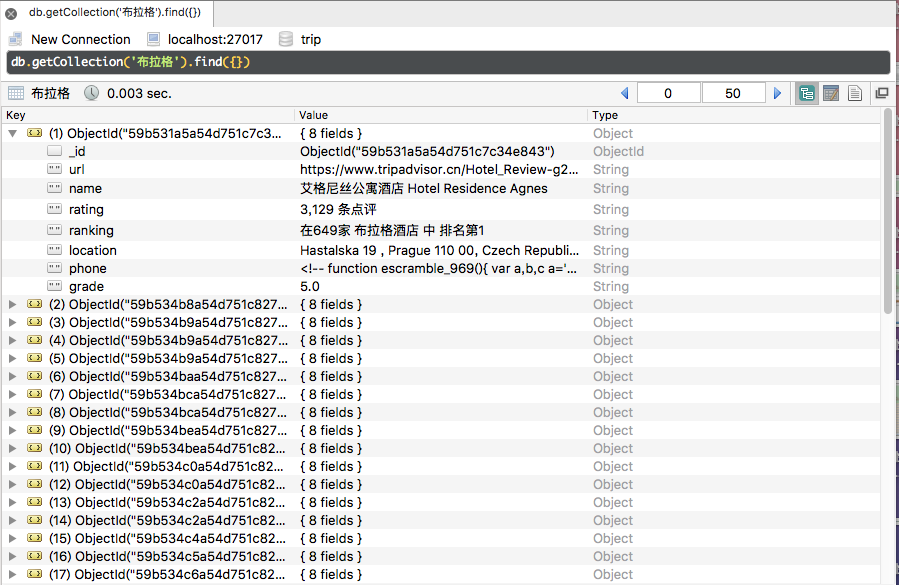
到现在,我们便完成了对猫途鹰网上布拉格酒店信息的爬取。
代码 github 地址:https://github.com/weixuqin/PythonProjects/blob/master/pyspider/spider.py
利用 pyspider 框架抓取猫途鹰酒店信息的更多相关文章
- 如何利用BeautifulSoup选择器抓取京东网商品信息
昨天小编利用Python正则表达式爬取了京东网商品信息,看过代码的小伙伴们基本上都坐不住了,辣么多的规则和辣么长的代码,悲伤辣么大,实在是受不鸟了.不过小伙伴们不用担心,今天小编利用美丽的汤来为大家演 ...
- 如何有效抓取SQL Server的BLOCKING信息
原文:如何有效抓取SQL Server的BLOCKING信息 转自:微软亚太区数据库技术支持组 官方博客 http://blogs.msdn.com/b/apgcdsd/archive/2011/12 ...
- 搜索会抓取网站域名的whoise信息吗
http://www.wocaoseo.com/thread-309-1-1.html 网站是否在信产部备案,这是不是会成为影响网站收录和排名的一个因素?百度是否会抓取域名注册人的相关whois信息吗 ...
- 利用python scrapy 框架抓取豆瓣小组数据
因为最近在找房子在豆瓣小组-上海租房上找,发现搜索困难,于是想利用爬虫将数据抓取. 顺便熟悉一下Python. 这边有scrapy 入门教程出处:http://www.cnblogs.com/txw1 ...
- 利用HttpClient抓取话费详单等信息
由于项目需要,需要获取授权用户的在运营商(中国移动.中国联通.中国电信)那里的个人信息.话费详单.月汇总账单信息(需要指出的是电信用户的个人信息无法从网上营业厅获取).抓取用户信息肯定是要模仿用户登录 ...
- 利用cookies+requests包登陆微博,使用xpath抓取目标用户的用户信息、微博以及对应评论
本文目的:介绍如何抓取微博内容,利用requests包+cookies实现登陆微博,lxml包的xpath语法解析网页,抓取目标内容. 所需python包:requests.lxml 皆使用pip安装 ...
- Python:利用 selenium 库抓取动态网页示例
前言 在抓取常规的静态网页时,我们直接请求对应的 url 就可以获取到完整的 HTML 页面,但是对于动态页面,网页显示的内容往往是通过 ajax 动态去生成的,所以如果是用 urllib.reque ...
- NET 5 爬虫框架/抓取数据
爬虫大家或多或少的都应该接触过的,爬虫有风险,抓数需谨慎. 爬虫有的是抓请求,有的是抓网页再解析 本着研究学习的目的,记录一下在 .NET Core 下抓取数据的实际案例.爬虫代码一般具有时效性,当 ...
- Python3利用BeautifulSoup4批量抓取站点图片的代码
边学边写代码,记录下来.这段代码用于批量抓取主站下所有子网页中符合特定尺寸要求的的图片文件,支持中断. 原理很简单:使用BeautifulSoup4分析网页,获取网页<a/>和<im ...
随机推荐
- 使用 win10 的正确姿势 (第二版)
文章为本人原创,转载请注明出处,谢谢. 17年9月初,写了第一篇<使用 win10 的正确姿势>,而现在半年多过去,文章更新了一些,主要是桌面的变化. 一. 重新定义桌面 我的桌面: 将桌 ...
- RDD概念、特性、缓存策略与容错
一.RDD概念与特性 1. RDD的概念 RDD(Resilient Distributed Dataset),是指弹性分布式数据集.数据集:Spark中的编程是基于RDD的,将原始数据加载到内存变成 ...
- Spring Boot 2.0(六):使用 Docker 部署 Spring Boot 开源软件云收藏
云收藏项目已经开源2年多了,作为当初刚开始学习 Spring Boot 的练手项目,使用了很多当时很新的技术,现在看来其实很多新技术是没有必要使用的,但做为学习案例来讲确实是一个绝佳的 Spring ...
- Python变量赋值的秘密
在Python中,我们令一个变量等于另外一个变量时,并不是把值传递给它,而是直接把指向的地址更改了.我们想要查看一个变量在内存中的地址,可以通过id(变量) 来查看.我们通过一个小例子来看看这个有趣的 ...
- 1013团队Beta冲刺day1
项目进展 李明皇 今天解决的进度 点击首页list相应条目将信息传到详情页 明天安排 优化信息详情页布局 林翔 今天解决的进度 前后端连接成功 明天安排 开始微信前端+数据库写入 孙敏铭 今天解决的进 ...
- PTA博客制作的模版
C高级第 次PTA作业( ) 题目 - 此处填写题目名称 1.设计思路 (1)算法 (2)流程图 2.实验代码 此处填写代码 3.本题调试过程碰到问题及解决办法 错误信息: 错误原因: 改正方法: 提 ...
- CentOS 7 Redis安装配置
1.获取Redis压缩包: wget http:.tar.gz 2.解压测试: mv 到 /usr/local/ tar .tar cd redis 3.使用make测试编译: make 这里可能会出 ...
- restful架构风格设计准则(五)用户认证和session管理
读书笔记,原文链接:http://www.cnblogs.com/loveis715/p/4669091.html,感谢作者! Authentication REST提倡无状态约束,这就要求:用户状态 ...
- 英语词汇(5)followed by / sung by / written by
Sung by 演唱者; [例句]In the recording I have today, it is sung by a male alto.我今天带的唱片是由一位男高音歌手唱的. follow ...
- Python之面向对象一
引子 小游戏:人狗大战 角色:人和狗 角色属性:姓名,血量,战斗力和性别(种类) 技能:打/咬 用函数实现人打狗和狗咬人的情形 def Dog(name,blood,aggr,kind): dog = ...