利用 pyspider 框架抓取猫途鹰酒店信息
利用框架 pyspider 能实现快速抓取网页信息,而且代码简洁,抓取速度也不错。
环境:macOS;Python 版本:Python3。
1.首先,安装 pyspider 框架,使用pip3一键安装:
pip3 pyspider
2.终端输入 pyspider all 启动 pyspider:
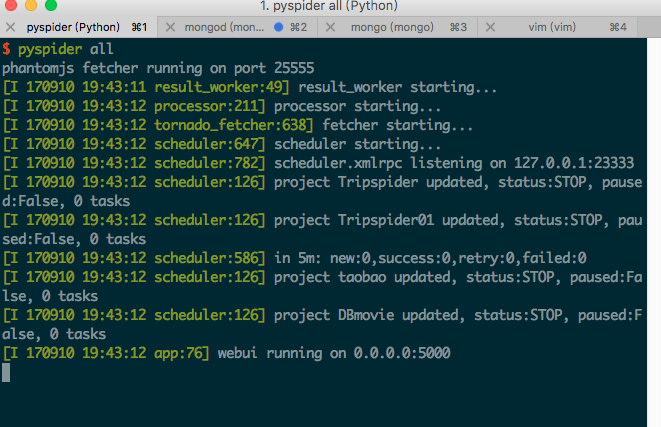
打开 Chrome,地址栏输入 localhost:5000 进入 pyspider 框架的webui界面。
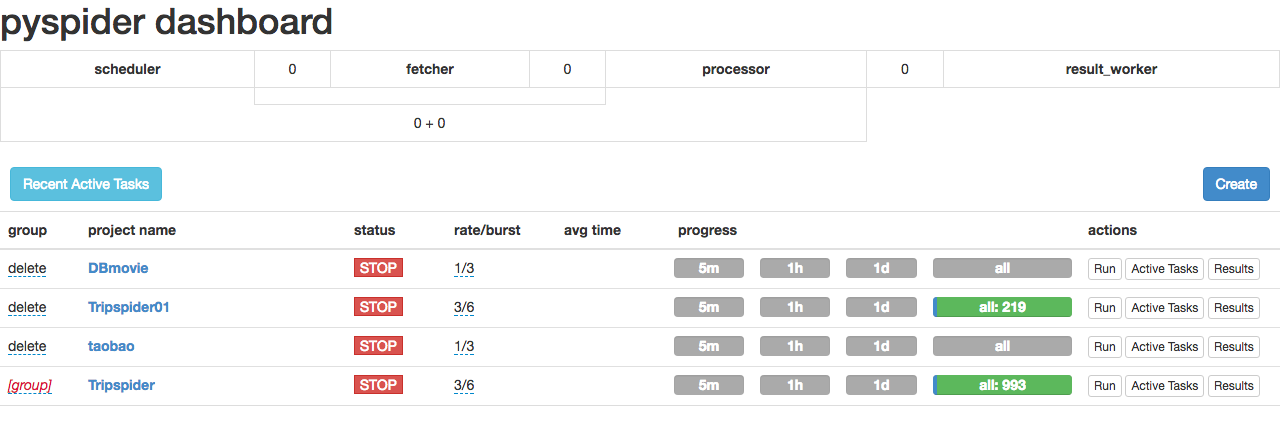
点击 create ,创建 一个新的project。
3.创建完 project 后,我们便进入了代码调试界面。
这次我们要抓取的信息是猫途鹰网关于布拉格的酒店信息,把网址填入 on_star 一栏并替换掉 on_star , 点击 save 保存,点击左上角 run 选项,然后点击出现的网址右侧的箭头的选项:
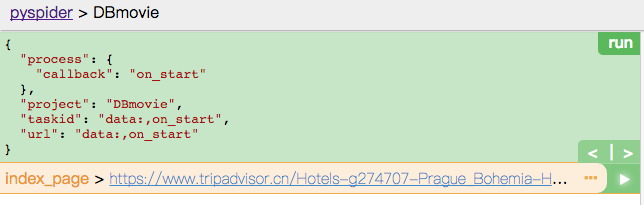
便出现 index_page 的页面,我们点击 web 选项卡,出现网页内容后点击 enable css selector helper ,选中酒店标题的超链接,这时上方便出现该标题的 CSS 选择器,把选择器内容复制粘贴替换掉右侧代码中的 a[href^="http"] ,save 后再次点击 run,但是 pyspider 的选择器并不一定准确,需要自己随时更改。这时我们便得到了我们想要的酒店标题超链接。
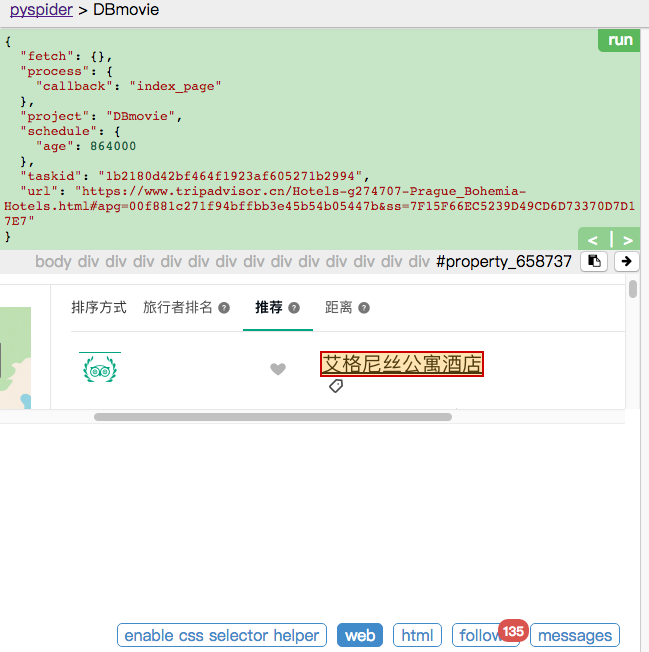
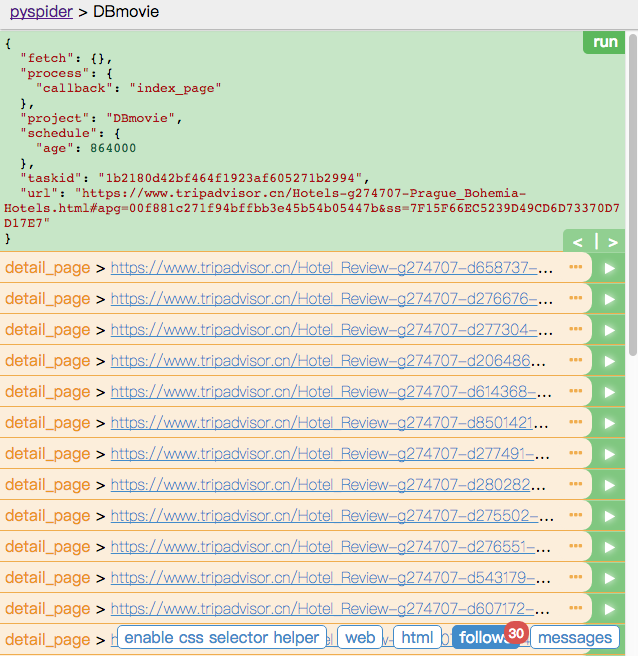
4.点击其中一个网页的右边的小箭头,进入详情页界面,我们要获取的信息便是详情页中的内容。类似的用 CSS 选择器获取酒店的信息,写入代码如下:
def detail_page(self, response):
url = response.url
name = response.doc('.heading_title').text()
rating = response.doc('.header_rating .taLnk').text()
ranking = response.doc('.prw_common_header_pop_index > span').text()
location = response.doc('.colCnt3').text()
phone = response.doc('.blEntry.phone > span:nth-child(2)').text()
grade = response.doc('.overallRating').text()
return {
"url": url,
"name": name,
"rating": rating,
"ranking": ranking,
"location": location,
"phone": phone,
"grade": grade }
便返回酒店链接,名称,点评,排名,地址,电话,评分这七个信息,保存后点击 run,我们便能看到打印的信息。
5.存储信息到 MongoDB:
import pymongo
client = pymongo.MongoClient('localhost')
db = client['trip']
def on_result(self, result):
if result:
self.save_to_mongo(result)
def save_to_mongo(self, result):
if self.db['布拉格'].insert(result):
print('存储到 MongoDB 成功', result)
6.模拟翻页抓取多页面:
在 index_page(self, response) 函数中插入:
next = response.doc('.pagination .nav.next').attr.href
self.crawl(next, callback=self.index_page)
7.到这时,我们代码便写完了,退出 project ,在控制面板中 status 栏更改方式为 DEBUG ,点击 run,运行代码,Active Tasks 可以查看当前任务。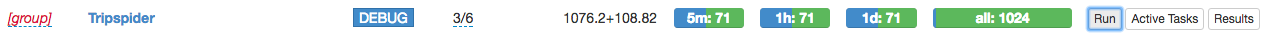
8.存储到MongoDB 的信息。
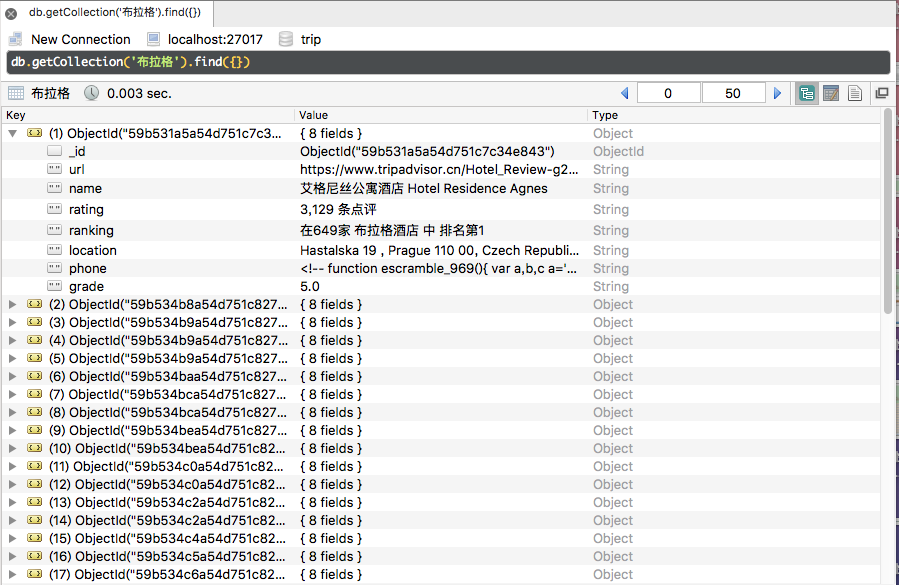
到现在,我们便完成了对猫途鹰网上布拉格酒店信息的爬取。
代码 github 地址:https://github.com/weixuqin/PythonProjects/blob/master/pyspider/spider.py
利用 pyspider 框架抓取猫途鹰酒店信息的更多相关文章
- 如何利用BeautifulSoup选择器抓取京东网商品信息
昨天小编利用Python正则表达式爬取了京东网商品信息,看过代码的小伙伴们基本上都坐不住了,辣么多的规则和辣么长的代码,悲伤辣么大,实在是受不鸟了.不过小伙伴们不用担心,今天小编利用美丽的汤来为大家演 ...
- 如何有效抓取SQL Server的BLOCKING信息
原文:如何有效抓取SQL Server的BLOCKING信息 转自:微软亚太区数据库技术支持组 官方博客 http://blogs.msdn.com/b/apgcdsd/archive/2011/12 ...
- 搜索会抓取网站域名的whoise信息吗
http://www.wocaoseo.com/thread-309-1-1.html 网站是否在信产部备案,这是不是会成为影响网站收录和排名的一个因素?百度是否会抓取域名注册人的相关whois信息吗 ...
- 利用python scrapy 框架抓取豆瓣小组数据
因为最近在找房子在豆瓣小组-上海租房上找,发现搜索困难,于是想利用爬虫将数据抓取. 顺便熟悉一下Python. 这边有scrapy 入门教程出处:http://www.cnblogs.com/txw1 ...
- 利用HttpClient抓取话费详单等信息
由于项目需要,需要获取授权用户的在运营商(中国移动.中国联通.中国电信)那里的个人信息.话费详单.月汇总账单信息(需要指出的是电信用户的个人信息无法从网上营业厅获取).抓取用户信息肯定是要模仿用户登录 ...
- 利用cookies+requests包登陆微博,使用xpath抓取目标用户的用户信息、微博以及对应评论
本文目的:介绍如何抓取微博内容,利用requests包+cookies实现登陆微博,lxml包的xpath语法解析网页,抓取目标内容. 所需python包:requests.lxml 皆使用pip安装 ...
- Python:利用 selenium 库抓取动态网页示例
前言 在抓取常规的静态网页时,我们直接请求对应的 url 就可以获取到完整的 HTML 页面,但是对于动态页面,网页显示的内容往往是通过 ajax 动态去生成的,所以如果是用 urllib.reque ...
- NET 5 爬虫框架/抓取数据
爬虫大家或多或少的都应该接触过的,爬虫有风险,抓数需谨慎. 爬虫有的是抓请求,有的是抓网页再解析 本着研究学习的目的,记录一下在 .NET Core 下抓取数据的实际案例.爬虫代码一般具有时效性,当 ...
- Python3利用BeautifulSoup4批量抓取站点图片的代码
边学边写代码,记录下来.这段代码用于批量抓取主站下所有子网页中符合特定尺寸要求的的图片文件,支持中断. 原理很简单:使用BeautifulSoup4分析网页,获取网页<a/>和<im ...
随机推荐
- 记录python接口自动化测试--requests使用和基本方法封装(第一目)
之前学习了使用jmeter+ant做接口测试,并实现了接口的批量维护管理(大概500多条用例),对"接口"以及"接口测试"有了一个基础了解,最近找了一些用pyt ...
- c语言-第零次作业
1.你认为大学的学习生活.同学关系.师生应该是怎样?请一个个展开描述. 我很荣幸能考进集美大学.集美大学历史悠久.师资力量雄厚.教师与学生素质高.并且集美大学的学习生活和我理想中的一样!首先老师认真负 ...
- 咸鱼翻身beta冲刺博客集
咸鱼翻身beta冲刺博客集 凡事预则立-于Beta冲刺前 beta冲刺1-咸鱼 beta冲刺2-咸鱼 beta冲刺3-咸鱼 beta冲刺4-咸鱼 beta冲刺5-咸鱼 beta冲刺6-咸鱼 beta冲 ...
- alpha-咸鱼冲刺day4-紫仪
总汇链接 一,合照 emmmmm.自然还是没有的. 二,项目燃尽图 三,项目进展 QAQ具体工作量没啥进展.但是前后端终于可以数据交互了!.. 四,问题困难 日常啥都不会,百度真心玩一年. 还 ...
- 冲刺NO.12
Alpha冲刺第十二天 站立式会议 项目进展 项目核心功能,如学生基本信息管理模块,学生信用信息模块,奖惩事务管理模块等等都已完成,测试工作大体结束. 问题困难 项目结束后对项目的阶段性总结缺乏一定的 ...
- Python upper()方法
描述 Python upper() 方法将字符串中的小写字母转为大写字母. 语法 upper()方法语法: str.upper() 参数 NA. 返回值 返回小写字母转为大写字母的字符串. 实例 以下 ...
- 老板怎么办,我们网站遭到DDoS攻击又挂了?
相信现在正在阅读此文的你,一定听说过发生在上个月的史上最大的DDoS攻击. 美国东部时间2月28日,GitHub在一瞬间遭到高达1.35Tbps的带宽攻击.这次DDoS攻击几乎可以堪称是互联网有史以来 ...
- 策略模式(Stratety)
namespace StrategyPattern //策略模式 { /// <summary> /// 定义所以支持的算法的公共接口 /// </summary> abstr ...
- Electron的代码调试
刚接触Electron,尝试调试程序时,竟无从下手,所以把这个过程做了下记录 参考工程 根据Electron的官方文档:使用 VSCode 进行主进程调试:https://electronjs.org ...
- 零基础大数据入门教程:Java调用阿里云短信通道服务
这里我们使用SpringBoot 来调用阿里通信的服务. 阿里通信,双11.收到短信,日发送达6亿条.保障力度非常高. 使用的步骤: 1.1. 第一步:需要开通账户 1.2. 第二步:阅读接口文档 1 ...