Hadoop系列(二):Hadoop单节点部署
环境:CentOS 7
JDK: 1.7.0_80
hadoop:2.8.5
hadoop(192.168.56.101)
配置基础环境
1. 测试环境可以直接关闭selinux和防火墙
2. 主机添加hosts记录
# vim /etc/hosts
192.168.56.101 hadoop
3. 创建hadoop用户
# useradd hadoop
# passwd hadoop
4. 添加免密登陆(如果不添加免密登陆,后面启动服务时候会提示输入密码)
# su - hadoop
$ ssh-keygen -t rsa
$ ssh-copy-id hadoop@localhost
安装JDK
1. 卸载系统自带的openjdk
yum remove *openjdk*
2. 安装JDK
JDK下载地址:https://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html
# tar zxvf jdk1.7.0_80.tgz -C /usr/local/
# vim /etc/profile
#添加
export JAVA_HOME=/usr/local/jdk1.7.0_80
export JAVA_BIN=$JAVA_HOME/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
# source /etc/profile
# java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
部署Hadoop
在一台机器上配置,之后拷贝到其他节点主机
1. 安装Hadoop
# su - hadooop
$ wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
$ tar zxvf hadoop-2.8.5.tar.gz
$ mv hadoop-2.8.5 hadoop #添加环境变量(每个节点都配置)
$ vim ~/.bash_profile
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export PATH $ source ~/.bash_profile
2. 配置Hadoop
配置文件在`hadoop/etc/hadoop`目录下
$ cd hadoop/etc/hadoop #1. 修改core-site.xml
$ vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
</property>
</configuration> # 2. 修改hdfs-site.xml
$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9001</value>
</property>
</configuration> # 3. 修改mapred-site.xml
$ cp mapred-site.xml.template mapred-site.xml
$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> # 4. 修改hadoop-env.sh(如果不声明JAVA_HOME,在启动时会出现找不到JAVA_HOME 错误)
$ vim hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
改为
export JAVA_HOME=/usr/local/jdk1.7.0_80 # 5. 修改yarn-env.sh(如果不声明JAVA_HOME,在启动时会出现找不到JAVA_HOME 错误)
$ vim yarn-env.sh
在脚本前面添加
export JAVA_HOME=/usr/local/jdk1.7.0_80
3. 格式化HDFS
$ hadoop namenode -format
4. 启动服务
$ sbin/start-dfs.sh
$ sbin/start-yarn.sh
查看启动情况
$ jps
16321 NameNode
16658 ResourceManager
16511 SecondaryNameNode
16927 Jps
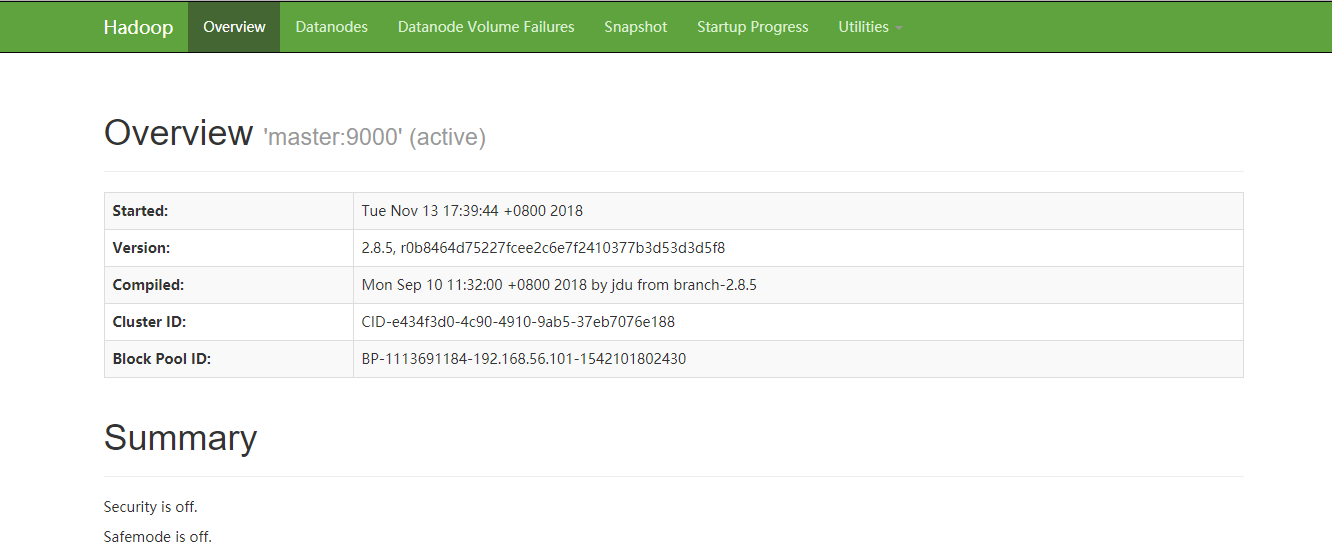
浏览器中访问http://192.168.56.101:50070 查看管理页面
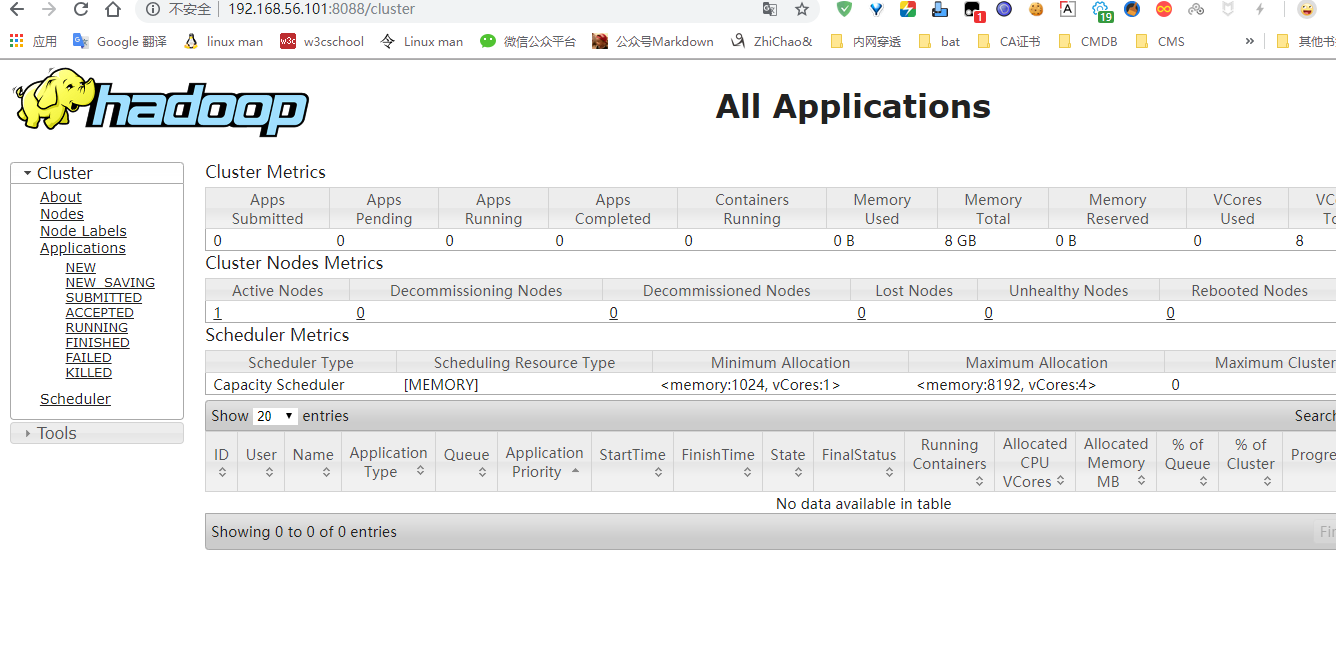
浏览器中访问http://192.168.56.101:8088
测试hadoop使用

Hadoop系列(二):Hadoop单节点部署的更多相关文章
- Hadoop 2.6.4单节点集群配置
1.安装配置步骤 # wget http://download.oracle.com/otn-pub/java/jdk/8u91-b14/jdk-8u91-linux-x64.rpm # rpm -i ...
- Ubuntu下用devstack单节点部署Openstack
一.实验环境 本实验是在Vmware Workstation下创建的单台Ubuntu服务器版系统中,利用devstack部署的Openstack Pike版. 宿主机:win10 1803 8G内存 ...
- .netcore consul实现服务注册与发现-单节点部署
原文:.netcore consul实现服务注册与发现-单节点部署 一.Consul的基础介绍 Consul是HashiCorp公司推出的开源工具,用于实现分布式系统的服务发现与配置.与其他分 ...
- HyperLedger Fabric 1.4 单机单节点部署(10.2)
单机单节点指在一台电脑上部署一个排序(Orderer)服务.一个组织(Org1),一个节点(Peer,属于Org1),然后运行官方案例中的example02智能合约例子,实现转财交易和查询功能.单机单 ...
- Kubernetes 二进制部署(一)单节点部署(Master 与 Node 同一机器)
0. 前言 最近受“新冠肺炎”疫情影响,在家等着,入职暂时延后,在家里办公和学习 尝试通过源码编译二进制的方式在单一节点(Master 与 Node 部署在同一个机器上)上部署一个 k8s 环境,整理 ...
- 单节点部署Hadoop教程
搭建HDFS 增加主机名 我这里仅仅增加了master主机名 [root@10 /xinghl/hadoop/bin]$ cat /etc/hosts 127.0.0.1 localhost 10.0 ...
- Hadoop HDFS 单节点部署方案
初学者,再次记录一下. 确保Java 和 Hadoop已安装完毕(每个人的不一定一样,但肯定都有数据,仅供参考) [root@jans hadoop-2.9.0]# pwd /usr/local/ha ...
- Hadoop入门--HDFS(单节点)配置和部署 (一)
一 配置SSH 下载ssh服务端和客户端 sudo apt-get install openssh-server openssh-client 验证是否安装成功 ssh username@192.16 ...
- Hadoop 2.2.0单节点的伪分布集成环境搭建
Hadoop版本发展历史 第一代Hadoop被称为Hadoop 1.0 1)0.20.x 2)0.21.x 3)0.22.x 第二代Hadoop被称为Hadoop 2.0(HDFS Federatio ...
随机推荐
- #6 判断一个数是否为2的n次方
「ALBB面试题」 [题目] 如何判断一个数是否为2的n次方 [题目分析] 看到这种题,相信大家第一反应就是循环除2,这样做肯定是可以得出结果的:但是这种做法无疑大大增加了计算机的运行时间,一个非常大 ...
- Js-函数式编程
前言 JavaScript是一门多范式语言,即可使用OOP(面向对象),也可以使用FP(函数式),由于笔者最近在学习React相关的技术栈,想进一步深入了解其思想,所以学习了一些FP相关的知识点,本文 ...
- DSAPI 3张图片实现花开动画
效果图 素材 代码 Dim B0, B1, B3 As Bitmap Private B As Bitmap = Nothing Private Sub Loading_Load(sender As ...
- AngularJs with Webpackv1 升級到 Webpack4
本篇記錄一下升級的血淚過程 請注意升級前請先創一個新目錄將升級應用與舊應用隔離 1. 需要將相關的套件做統一升級的動作,已確認需要升級所有舊的loaders 其它應用的套件可先不做升級的動作 (如果編 ...
- KsUML 免费的类图建模工具
最近基于SharpDevelop和NClass两个开源软件,开发了一个免费的类图建模工具,详情请访问 www.TimeGIS.com KsUML类图建模工具是一个用来给软件开发人员使用的一种UML类图 ...
- Android RecyclerView 快速平滑返回顶部
先看下实现的效果,没效果什么都白扯 下面直接上方法: //目标项是否在最后一个可见项之后 private boolean mShouldScroll; //记录目标项位置 private int mT ...
- Android 报错:error: too many padding sections on bottom border
一.发生错误 [我以为我做了一张完美的.9图片,没想到.9图片还需要画左边和上边,尴尬···] 二.解决方法 .9图片造成错误 [具体内容] 最后修改.9图为
- Android视频录制从不入门到入门系列教程(三)————视频方向
运行Android视频录制从不入门到入门系列教程(二)————显示视频图像中的Demo后,我们应该能发现视频的方向是错误的. 由于Android中,Camera给我们的视频图片的原始方向是下图这个样子 ...
- Java的多线程实现生产/消费模式
Java的多线程实现生产/消费模式 在Java的多线程中,我们经常使用某个Java对象的wait(),notify()以及notifyAll() 方法实现多线程的通讯,今天就使用Java的多线程实现生 ...
- QT之setstylesheet防止子窗体继承父窗体样式
/* 1.这里的#号表示,主控件不会影响子控件 2.设置多个样式,可以用双引号和分号 */ ui->groupBox_1->setStyleSheet("#groupBox_1{ ...