nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息。通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类,之后进入到每个分类下的视频列表,最后在具体到每一个视频,获取需要的信息。以订阅号YouTube 电影为例。源码请点击这里。
一、爬取YouTube 电影里面的视频分类列表
打开订阅号,我们可以发现订阅号下有许多视频分类如下图所示,接下来可以解析该订阅号信息,把视频分类的URL和名称爬取下来。

接下来我们通过浏览器点击检查查看网页,分析下如何获取分类,可以发现所有的视频分类都在ul 下的 li 里面,通过ul的id 我们便可以找到分类的相关信息,因此我们可以利用cheerio模块来解析页面,从而获取分类信息。

先将获取分类信息的相关代码分装成一个函数function categoryList (url , callback){},代码如下:
var request =require('superagent');
require('superagent-proxy')(request);
var cheerio = require('cheerio');
var debug = require('debug')('youtube:test:category-list');
var proxy = 'http://127.0.0.1:61481';//设置代理IP地址
//请求头信息
var header = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch, br',
'Accept-Language':'zh-CN,zh;q=0.8,en;0.6',
'Cookie':'WKcs6.resume=; _ga=GA1.2.1653214693.1476773935; _gid=GA1.2.943573022.1500212436; YSC=_X6aKoK1jMc; s_gl=1d69aac621b2f9c0a25dade722d6e24bcwIAAABVUw==; VISITOR_INFO1_LIVE=T3BczuPUIQo; PREF=hl=zh-CN&cvdm=grid&gl=US&f1=50000000&al=zh-CN&f6=1&f5=30; SID=7gR6XOImfW5PbJLOrScScD4DXf8cHCkWCkxSUFy9CbhnaFaPLBCVCElv97n_mjWgkPC_ow.; HSID=A0_bKgPkAZLJUfnTj; SSID=ASjQTON7p_q4UNgit; APISID=ZIVPX9a3vUKRa28E/A0dykxLiVJ4xDIUS_; SAPISID=t6dcqHC9pjGsE7Bi/ATm5wgRC27rqUQr5B; CONSENT=YES+CN.zh-CN+20160904-14-0; LOGIN_INFO=APUNbegwRQIhAPnMZ-qYHOSAKq0s9ltEQIUvnWNj9CHQ8J5s2JtZK15TAiBLzfS4HEUh-mWGo2Qo6XOruItGRdpPZ2v3cXLqYY7xtA:QUZKNV9BajdRR2VZQ2QyRlVDdXh3VDdKZ1AzMlFqRmg3aTBfR2pxWXFHWXlXYm1BaVVnQWk4UzZfWmZGSGcxRkNuTDBFYTk2a2tKLUEtNmtNaWZKM3hTMWNTZkgyOVlvTF9DNENwTG5XTlJudEVHQzVIeGxMbTFTdkl6YS02QlBmMmM0NVgteWI3QVNIa3c5c2ZkV1NSa3AzbWhwOHBtbzVrVTVSbTBqaWpIZ0dWNTd4UjJRSllr',
'Upgrade-insecure-requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36',
'X-Chrome-Uma-Enabled':'1',
'X-Client-Data':'CJa2yQEIorbJAQjBtskBCKmdygE=',
'Connection': 'keep-alive'
};
//获取订阅号下视频分类列表
function categoryList (url , callback){
debug('读取订阅号下视频分类列表',url);
request
.get(url)//需要获取的网址
.set('header',header)
.proxy(proxy)
.end(onresponse);
function onresponse(err,res){
//res.setEncoding('utf-8'); //防止中文乱码
if(err){
return callback(err);
}else{
console.log('status:'+res.status);//打印状态码
//console.log(res.text);
var $ = cheerio.load(res.text);
//获取订阅号Id
var $channelName = $('#c4-primary-header-contents .branded-page-header-title a').attr('href');
var $channelId = $channelName.match(/channel\/([a-zA-Z0-9_-]+)/);
var categoryList = [];
$('#browse-items-primary .branded-page-module-title').each(function(){
var $category = $(this).find('a').first();
var item = {
name : $category.text().trim(),
url : 'https://www.youtube.com' + $category.attr('href')
};
//根据URL判断为订阅号或者是视频分类
if(item.url.indexOf('list')!==-1){
item.channelId = $channelId[1];
}else{
var s = item.url.match(/channel\/([a-zA-Z0-9_-]+)/);
item.id = s[1];
}
//获取youtube某个订阅号下的视频分类
if(item.name!==''){
categoryList.push(item);
}
});
callback(null,categoryList);
}
}
}
接着调用categoryList函数:
categoryList('https://www.youtube.com/channel/UClgRkhTL3_hImCAmdLfDE4g',function(err,categoryList){
if(err){
return console.log(err);
}
return console.log(categoryList);
});
在后台运行就得到了视频分类信息,这是会发现视频分类里面又包含了某些订阅号,而我们只需要提取视频分类。

去除订阅号信息(当然也可以添加到订阅号列表,然后再依次读取订阅号下的视频分类)
//获取youtube某个订阅号下的视频分类
if(item.name!==''){
categoryList.push(item);
}
替换为
//获取youtube某个订阅号下的视频分类
if(item.categoryName!==''&&item.hasOwnProperty('channelId')){
categoryList.push(item);
}
这时再运行会发现订阅号的信息已经剔除了,只保留了分类列表,接下来进入到下一层,通过视频分类获取视频列表。
二、获取视频列表
我们以最卖座电影为例,获取其下面的视频列表。点击打开页面,我们会发现该分类下视频列表全部在在里面,我们同样只获取其url 以及名称等信息。

点击检查(ps:我用的Google浏览器),先查看下网页结构,再用cheerio进行解析。检查发现我们可以通过tbody中的tr获取每个视频。

相关代码如下:
//获取视频列表
function videoList (url , callback){
debug('读取视频列表',url) request
.get(url)//需要获取的网址
.set('header',header)
.proxy(proxy)
.end(onresponse); function onresponse(err,res){
res.setEncoding('utf-8'); //防止中文乱码
if(err){
return callback(err);
}else{
console.log('status:'+res.status);//打印状态码
//console.log(res.text);
var $ = cheerio.load(res.text);
var videoList = [];
//获取视频分类名称
var $category = $('#pl-header .pl-header-content .pl-header-title').text().trim();
$('#pl-video-table tr .pl-video-title').each(function(){
var $video = $(this).find('a');
var item = {
categoryName : $category,
name : $video.text().trim(),
url : 'https://www.youtube.com' + $video.attr('href')
};
//从url中提取index
var s = item.url.match(/index\=(\d+)/);
if(Array.isArray(s)){
item.order = s[1];
//获取youtube某个订阅号下的某个视频分类下的所有视频列表
videoList.push(item);
} }); callback(null,videoList);
}
}
} videoList('https://www.youtube.com/playlist?list=PLHPTxTxtC0iaN9kA37m6MRrxFkgby2CDR',function(err,videoList){
if(err){
return console.log(err);
}
return console.log(videoList);
});
运行后我们可以发现后台打印出了视频列表的想关信息

三、获取具体视频信息
以第一个视频为例,点击可以看到发布时间,简介等视频信息多可以提取出来。
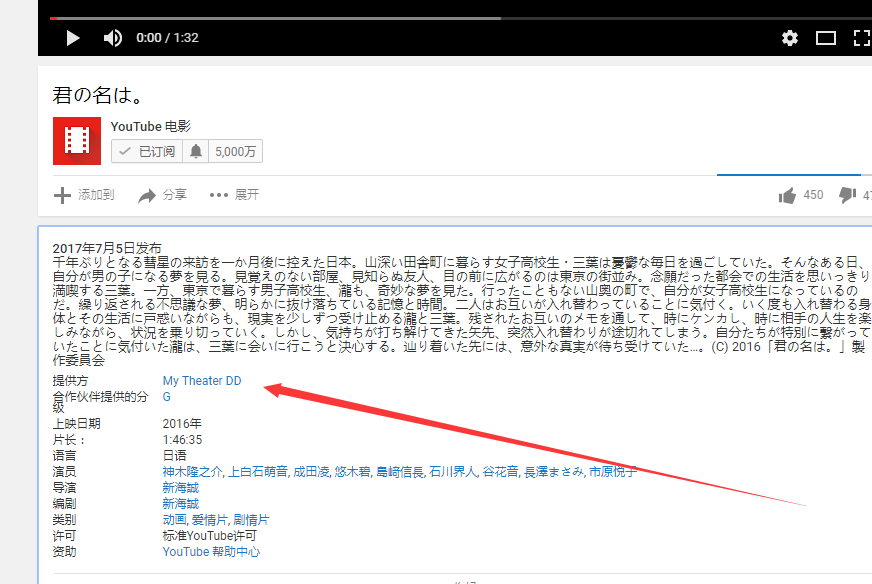
同样通过检查,分析页面后,我们的代码如下:
//获取视频详细信息
function information (url , callback){
debug('读取视频详细信息',url); request
.get(url)//需要获取的网址
.set('header',header)
.proxy(proxy)
.end(onresponse); function onresponse(err,res){ if(err){
return callback(err);
}else{
console.log('status:'+res.status);//打印状态码
//console.log(res.text);
var $ = cheerio.load(res.text);
var information = {};
information.url = 'https://www.youtube.com'+$('#playlist-autoscroll-list .currently-playing a').attr('href');
information.videoName = $('#watch-headline-title').text().trim();
information.pubTime = $('#watch-uploader-info').text().trim();
information.intro = $('#watch-description-text').text().trim(); var filmLen = $('#watch-description-extras .watch-extras-section li').text().trim();
var s = filmLen.match(/(\d+\:\d+\:\d+)/);
if(Array.isArray(s)){
information.filmLen = s[1];
} callback(null,information);
}
}
} information('https://www.youtube.com/watch?v=sjhbO8lIc2s&index=1&list=PLHPTxTxtC0iaN9kA37m6MRrxFkgby2CDR',function(err,information){
if(err){
return console.log(err);
}
return console.log(information);
})
运行后发现视频的部分信息已经打印出来啦!

到这我们已经完成了从订阅号到视频分类再到具体视频的一整个过程,接下来我们利用nodejs爬虫笔记一中的方法对其进行保存。
四、整理并保存
1、首先在youtube目录下新建config.js、read.js、save.js以及index.js文件,config文件用于存储订阅号网址等信息,read文件用于读取页面信息,save文件用于将数据存储在mysql,index作为主文件,通过调用read和save文件运行,将信息依次保存。
2、安装相关模块,如mysql,debug,async等。
3、 在数据库中,新建YouTube数据库,分别新建channel,categroy,video和information四个数据表,依次保存订阅号信息,分类列表,视频列表和视频信息。
4、因为每个视频对应着唯一的ID,因而对得到的视频列表进行去重处理,然后再到具体的视频,以免获取重复的视频信息。
config.js
exports.URL = {
url : 'https://www.youtube.com'
};
exports.channel = [
{url:'https://www.youtube.com/channel/UCYfdidRxbB8Qhf0Nx7ioOYw'},//news
{url:'https://www.youtube.com/channel/UC-9-kyTW8ZkZNDHQJ6FgpwQ'},//musics
{url:'https://www.youtube.com/channel/UCEgdi0XIXXZ-qJOFPf4JSKw'},//physical
{url:'https://www.youtube.com/channel/UClgRkhTL3_hImCAmdLfDE4g'},//movies
{url:'https://www.youtube.com/channel/UCOpNcN46UbXVtpKMrmU4Abg'} //games
];
read.js
var request =require('superagent');
require('superagent-proxy')(request);
var cheerio = require('cheerio');
var debug = require('debug')('youtube:read');
var proxy = 'http://127.0.0.1:61481';//设置代理IP地址
//请求头信息
var header = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch, br',
'Accept-Language':'zh-CN,zh;q=0.8,en;0.6',
'Cookie':'WKcs6.resume=; _ga=GA1.2.1653214693.1476773935; _gid=GA1.2.943573022.1500212436; YSC=_X6aKoK1jMc; s_gl=1d69aac621b2f9c0a25dade722d6e24bcwIAAABVUw==; VISITOR_INFO1_LIVE=T3BczuPUIQo; PREF=hl=zh-CN&cvdm=grid&gl=US&f1=50000000&al=zh-CN&f6=1&f5=30; SID=7gR6XOImfW5PbJLOrScScD4DXf8cHCkWCkxSUFy9CbhnaFaPLBCVCElv97n_mjWgkPC_ow.; HSID=A0_bKgPkAZLJUfnTj; SSID=ASjQTON7p_q4UNgit; APISID=ZIVPX9a3vUKRa28E/A0dykxLiVJ4xDIUS_; SAPISID=t6dcqHC9pjGsE7Bi/ATm5wgRC27rqUQr5B; CONSENT=YES+CN.zh-CN+20160904-14-0; LOGIN_INFO=APUNbegwRQIhAPnMZ-qYHOSAKq0s9ltEQIUvnWNj9CHQ8J5s2JtZK15TAiBLzfS4HEUh-mWGo2Qo6XOruItGRdpPZ2v3cXLqYY7xtA:QUZKNV9BajdRR2VZQ2QyRlVDdXh3VDdKZ1AzMlFqRmg3aTBfR2pxWXFHWXlXYm1BaVVnQWk4UzZfWmZGSGcxRkNuTDBFYTk2a2tKLUEtNmtNaWZKM3hTMWNTZkgyOVlvTF9DNENwTG5XTlJudEVHQzVIeGxMbTFTdkl6YS02QlBmMmM0NVgteWI3QVNIa3c5c2ZkV1NSa3AzbWhwOHBtbzVrVTVSbTBqaWpIZ0dWNTd4UjJRSllr',
'Upgrade-insecure-requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36',
'X-Chrome-Uma-Enabled':'1',
'X-Client-Data':'CJa2yQEIorbJAQjBtskBCKmdygE=',
'Connection': 'keep-alive'
};
//获取订阅号列表
exports.channelList = function(url , callback){
debug('读取订阅号列表', url);
request
.get(url)//需要获取的网址
.set('header',header)
.proxy(proxy)
.end(onresponse);
function onresponse(err,res){
//res.setEncoding('utf-8'); //防止中文乱码
if(err){
return callback(err);
}else{
//console.log('status:'+res.status);//打印状态码
//console.log(res.text);
var $ = cheerio.load(res.text);
var channelList = [];
var s = $('#guide-container .guide-toplevel li').eq(4);
// console.log(s);
s.find('a').each(function(){
var item = {
channelName : $(this).text().trim(),
url : 'https://www.youtube.com' + $(this).attr('href')
};
var s = item.url.match(/channel\/([a-zA-Z0-9_-]+)/);
if(Array.isArray(s)){
item.id = s[1];
//获取youtube主页下的订阅号
channelList.push(item);
}
});
callback(null,channelList);
}
}
};
//获取订阅号下视频分类列表
exports.categoryList = function(url , callback){
debug('读取订阅号下视频分类列表',url);
request
.get(url)//需要获取的网址
.set('header',header)
.proxy(proxy)
.end(onresponse);
function onresponse(err,res){
//res.setEncoding('utf-8'); //防止中文乱码
if(err){
return callback(err);
}else{
//console.log('status:'+res.status);//打印状态码
//console.log(res.text);
var $ = cheerio.load(res.text);
//获取订阅号Id
var $channelName = $('#c4-primary-header-contents .branded-page-header-title a').attr('href');
var $channelId = $channelName.match(/channel\/([a-zA-Z0-9_-]+)/);
var categoryList = [];
$('#browse-items-primary .branded-page-module-title').each(function(){
var $category = $(this).find('a').first();
var item = {
categoryName : $category.text().trim(),
url : 'https://www.youtube.com' + $category.attr('href')
};
//根据URL判断为订阅号还是视频分类
if(item.url.indexOf('list')!==-1){
if(Array.isArray($channelId)){
item.channelId = $channelId[1];
}
}else{
var s = item.url.match(/channel\/([a-zA-Z0-9_-]+)/);
if(Array.isArray(s)){
item.id = s[1];
}
}
//获取youtube某个订阅号下的视频分类
if(item.categoryName!==''&&item.hasOwnProperty('channelId')){
categoryList.push(item);
}
});
callback(null,categoryList);
}
}
};
//获取视频列表
exports.videoList =function (url , callback){
debug('读取视频列表',url)
request
.get(url)//需要获取的网址
.set('header',header)
.proxy(proxy)
.end(onresponse);
function onresponse(err,res){
//res.setEncoding('utf-8'); //防止中文乱码
if(err){
return callback(err);
}else{
//callback(null,'status:'+res.status);//打印状态码
//console.log(res.text);
var $ = cheerio.load(res.text);
var videoList = [];
//获取视频分类名称
var $category = $('#pl-header .pl-header-content .pl-header-title').text().trim();
$('#pl-video-table tr .pl-video-title').each(function(){
var $video = $(this).find('a');
var item = {
categoryName : $category,
videoName : $video.text().trim(),
url : 'https://www.youtube.com' + $video.attr('href')
};
var s = item.url.match(/index\=(\d+)/);
if(Array.isArray(s)){
item.sequence = s[1];
//获取youtube某个订阅号下的某个视频分类下的所有视频列表
videoList.push(item);
}
});
callback(null,videoList);
}
}
};
//获取视频详细信息
exports.information = function (url , callback){
debug('读取视频详细信息',url);
request
.get(url)//需要获取的网址
.set('header',header)
.proxy(proxy)
.end(onresponse);
function onresponse(err,res){
//res.setEncoding('utf-8'); //防止中文乱码
if(err){
return callback(err);
}else{
//console.log('status:'+res.status);//打印状态码
//console.log(res.text);
var $ = cheerio.load(res.text);
var information = {};
information.videoName = $('#watch-headline-title').text().trim();
information.pubTime = $('#watch-uploader-info').text().trim();
information.intro = $('#watch-description-text').text().trim();
var filmLen = $('#watch-description-extras .watch-extras-section li').text().trim();
var s = filmLen.match(/(\d+\:\d+\:\d+)/);
if(Array.isArray(s)){
information.filmLen = s[1];
}
callback(null,information);
}
}
};
//去重处理
exports.unique = function(arr){
var ret=[];
var hash={};
for(var i=0;i<arr.length;i++){
var item=arr[i];
var s = item.url.match(/v\=([a-zA-Z0-9_-]+)/);
var key = typeof(item)+s[1];
if(hash[key]!==1){
ret.push(item);
hash[key] =1;
}
}
return ret;
};
save.js
var mysql = require('mysql');
var debug = require('debug')('youtube:save');
var async = require('async');
var pool = mysql.createPool({
host : 'localhost',
user : 'root',
password : 'z2457098495924',
database : 'youtube'
});
//保存订阅列表
exports.channelList = function(list,callback){
debug('保存订阅列表',list.length);
pool.getConnection(function(err,connection){
if(err){
return callback(err);
}
var findsql = 'select * from channel where id=?';
var insertsql = 'insert into channel(channelName,url,id) values(?,?,?)';
var updatesql = 'update channel set channelName=?,url=? where id=?';
async.eachSeries(list,function(item,next){
//查询订阅号是否存在
connection.query(findsql,[item.id],function(err,result){
if(err){
return next(err);
}
if(result.length>=1){
//订阅号已经存在,更新
connection.query(updatesql,[item.channelName,item.url,item.id],next);
}else{
//将订阅号信息插入到数据表channel
connection.query(insertsql,[item.channelName,item.url,item.id],next);
}
});
},callback);
connection.release();
});
};
//保存订阅号下的视频分类列表
exports.categoryList = function(list,callback){
debug('保存订阅号下的视频分类列表',list.length);
pool.getConnection(function(err,connection){
if(err){
return callback(err);
}
var findsql = 'select * from category where channelId=? and categoryName=?';
var updatesql = 'update category set url=? where channelId=? and categoryName=?';
var insertsql = 'insert into category(channelId,categoryName,url) values(?,?,?)';
async.eachSeries(list,function(item,next){
//检查视频分类是否存在
connection.query(findsql,[item.channelId,item.categoryName],function(err,result){
if(err){
return next(err);
}
if(result.length>=1){
//如果存在则进行更新
connection.query(updatesql,[item.url,item.channelId,item.categoryName],next);
}else{
//不存在则讲数据插入数据表category
connection.query(insertsql,[item.channelId,item.categoryName,item.url],next);
}
});
},callback);
connection.release();
});
};
//保存订阅号下某个视频分类的视频列表
exports.videoList = function(list,callback){
debug('//保存订阅号下某个视频分类的视频列表',list.length);
pool.getConnection(function(err,connection){
if(err){
return callback(err);
}
var findsql = 'select * from video where sequence=? and categoryName=?';
var updatesql = 'update video set url=? where sequence=? and categoryName=?';
var insertsql = 'insert into video(categoryName,url,sequence) values(?,?,?)';
async.eachSeries(list,function(item,next){
connection.query(findsql,[item.sequence,item.categoryName],function(err,result){
if(err){
return next(err);
}
if(result.length>=1){
//如果存在则进行更新
connection.query(updatesql,[item.url,item.sequence,item.categoryName],next);
}else{
//不存在则讲数据插入数据表video
connection.query(insertsql,[item.categoryName,item.url,item.sequence],next);
}
});
},callback);
connection.release();
});
};
//保存视频信息
exports.information = function(videoUrl,list,callback){
debug('保存视频信息',videoUrl,list.length);
pool.getConnection(function(err,connection){
if(err){
return callback(err);
}
var findsql = 'select * from information where videoName=? and url=?';
var updatesql = 'update information set pubTime=?,intro=?,filmLen=? where videoName=? and url=?';
var insertsql = 'insert into information(videoName,url,pubTime,intro,filmLen) values(?,?,?,?,?)'
async.eachSeries(list,function(item,next){
connection.query(findsql,[item.videoName,videoUrl],function(err,result){
if(err){
return next(err);
}
if(result.length>=1){
//如果存在则进行更新
connection.query(updatesql,[item.pubTime,item.intro,item.filmLen,item.videoName,videoUrl],next);
}else{
//不存在则讲数据插入数据表information
connection.query(insertsql,[item.videoName,videoUrl,item.pubTime,item.intro,item.filmLen],next);
}
});
},callback);
connection.release();
});
};
//保存视频信息
exports.videoDetail = function(videoUrl,list,callback){
debug('保存视频信息',videoUrl);
pool.getConnection(function(err,connection){
if(err){
return callback(err);
}
var findsql = 'select * from information where videoName=?';
var updatesql = 'update information set pubTime=?,intro=?,url=?,filmLen=? where videoName=?';
var insertsql = 'insert into information(videoName,url,pubTime,intro,filmLen) values(?,?,?,?,?)'
connection.query(findsql,[list.videoName],function(err,result){
if(err){
return next(err);
}
if(result.length>=1){
//如果存在则进行更新
connection.query(updatesql,[list.pubTime,list.intro,videoUrl,list.filmLen,list.videoName],callback);
}else{
//不存在则讲数据插入数据表information
connection.query(insertsql,[list.videoName,videoUrl,list.pubTime,list.intro,list.filmLen],callback);
}
});
connection.release();
});
};
index.js
var async = require('async');
var config = require('./config');
var read = require('./read');
// var save = require('./save');
var debug = require('debug')('youtube:index');
var channelList;
var categoryList = {};//存储获取的分类列表
var newCgList = [];//用于存储整理后的分类列表
var videoList = {};
var newVdList = [];
var informationList = {};
async.series([
//从YouTube主页获取部分订阅号
function(done){
read.channelList(config.URL.url,function(err,list){
channelList = list;
done(err);
});
},
// //保存订阅号
// function(done){
// save.channelList(channelList,done);
// },
// //从所得的订阅号中获取视频分类列表
// function(done){
// async.eachSeries(channelList,function(item,next){
// read.categoryList(item.url,function(err,list){
// categoryList[item.id]=list;
// next(err);
// });
// //console.log(categoryList);
// },done);
// },
// //保存订阅号下视频分类列表
// function(done){
// async.eachSeries(Object.keys(categoryList),function(channelId,next){
// save.categoryList(categoryList[channelId],next);
// },done);
// }
//从config文件中读取订阅号,获取视频分类列表
function(done){
async.eachSeries(config.channel,function(item,next){
read.categoryList(item.url,function(err,list){
var s = item.url.match(/channel\/([a-zA-Z0-9_-]+)/);
item.id = s[1];
categoryList[item.id]=list;
next(err);
});
//console.log(categoryList);
},done);
},
//保存订阅号下视频分类列表
function(done){
async.eachSeries(Object.keys(categoryList),function(channelId,next){
save.categoryList(categoryList[channelId],next);
},done);
},
//重新整理分类列表
function(done){
debug('重新整理分类列表');
Object.keys(categoryList).forEach(function(channelId){
categoryList[channelId].forEach(function(item){
newCgList.push(item);
});
});
done();
},
//获取所有分类下视频列表
function(done){
async.eachSeries(newCgList,function(item,next){
read.videoList(item.url,function(err,list){
videoList[item.categoryName] = list;
next(err);
});
},done);
},
//保存视频列表
function(done){
async.each(Object.keys(videoList),function(categoryName,next){
save.videoList(videoList[categoryName],next);
},done);
},
//重新整理视频列表
function(done){
debug('重新整理视频列表并去重');
Object.keys(videoList).forEach(function(categoryName){
videoList[categoryName].forEach(function(item){
newVdList.push(item);
});
});
console.log(newVdList);
newVdList = read.unique(newVdList);
console.log(newVdList);
done();
},
//获取视频信息
function(done){
async.eachSeries(newVdList,function(item,next){
read.information(item.url,function(err,list){
informationList[item.url] = list;
//边读取边保存视频信息
console.log(informationList);
save.videoDetail(item.url,list,next);
});
},done);
}
],function(err){
if(err){
console.log(err);
}
console.log('finish');
process.exit(0);
});
最后设置环境变量,debug= youtube:*(ps:Windows下为set debug=youtube:*),并在youtube目录下执行node index,命令窗口将会依次打印出相关信息。
五、小结
通过本次练习,加深了对nodejs爬虫的理解,已经相关模块的应用,但通过爬取的信息,我们可以发现网站中有很多加载更多,而里面的内容我们并没有爬取下来,只爬取到了没点击加载时的页面信息,接下来得好好琢磨如何获取加载更多的内容。
nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息的更多相关文章
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 网络爬虫 002 (入门) 爬取一个网站之前,要了解的知识
网站站点的背景调研 1. 检查 robots.txt 网站都会定义robots.txt 文件,这个文件就是给 网络爬虫 来了解爬取该网站时存在哪些限制.当然了,这个限制仅仅只是一个建议,你可以遵守,也 ...
- python爬虫笔记之爬取足球比赛赛程
目标:爬取某网站比赛赛程,动态网页,则需找到对应ajax请求(具体可参考:https://blog.csdn.net/you_are_my_dream/article/details/53399949 ...
- 【Python3 爬虫】14_爬取淘宝上的手机图片
现在我们想要使用爬虫爬取淘宝上的手机图片,那么该如何爬取呢?该做些什么准备工作呢? 首先,我们需要分析网页,先看看网页有哪些规律 打开淘宝网站http://www.taobao.com/ 我们可以看到 ...
- python爬虫学习-爬取某个网站上的所有图片
最近简单地看了下python爬虫的视频.便自己尝试写了下爬虫操作,计划的是把某一个网站上的美女图全给爬下来,不过经过计算,查不多有好几百G的样子,还是算了.就首先下载一点点先看看. 本次爬虫使用的是p ...
- windows下使用python的scrapy爬虫框架,爬取个人博客文章内容信息
scrapy作为流行的python爬虫框架,简单易用,这里简单介绍如何使用该爬虫框架爬取个人博客信息.关于python的安装和scrapy的安装配置请读者自行查阅相关资料,或者也可以关注我后续的内容. ...
- Python 002- 爬虫爬取淘宝上耳机的信息
参照:https://mp.weixin.qq.com/s/gwzym3Za-qQAiEnVP2eYjQ 一般看源码就可以解决问题啦 #-*- coding:utf-8 -*- import re i ...
随机推荐
- 富文本编辑器Quill的使用
我们经常需要使用富文本编辑器从后台管理系统上传文字,图片等用于前台页面的显示,Quill在后台传值的时候需要传两个参数,一个用于后台管理系统编辑器的显示,一个用前台页面的显示,具体代码如下截图: 另Q ...
- SSM框架实现分页
SSM框架实现分页 1,.首先创建一个分页的工具类 package cn.page.po; import java.io.Serializable; public class Page impleme ...
- better-scroll不能滚动之 滚动监听-左右联动
滚动监听 better-scroll 无法滚动的分析,直接翻到最后,看问题汇总,希望能帮助你解决. 借用一下人家这个好看的项目图片,做一个解释.左边的内容会跟右边的内容一起关联,点击左边的菜单,右边会 ...
- selenium获取动态网页信息(某东)-具体配置信息
需要安装的包: selenium 关于软件的驱动:selenium之 驱动环境配置chrome.firefox.IE 1 # encoding:utf-8 2 # Author:"richi ...
- 【转载】IdentityServer4 使用OpenID Connect添加用户身份验证
使用IdentityServer4 实现OpenID Connect服务端,添加用户身份验证.客户端调用,实现授权. IdentityServer4 目前已更新至1.0 版,在之前的文章中有所介绍.I ...
- python实现简单函数发生器
最近学校又抽风把我自动化系的苦逼童鞋留下做课设,简直无聊到爆的-->用VB实现函数发生器,(语言不限制) 大伙不知从哪搞来的MATLAB版本,于是几十个人就在这基础上修修改改蒙混过关了,可我实在 ...
- 模板层(template)
模板: 什么是模板? html+模板语法 模板语法: 1 变量:{{}} 深度查询: 通过句点符号 . 过滤器 filter {{var|filter_name}} 2 标签: {% tag %} f ...
- hdu 5919--Sequence II(主席树--求区间不同数个数+区间第k大)
题目链接 Problem Description Mr. Frog has an integer sequence of length n, which can be denoted as a1,a2 ...
- HDU 1874 畅通工程续【Floyd算法实现】
畅通工程续 Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submi ...
- [国嵌笔记][005][Linux命令详解]
用户管理类命令 添加用户:useradd name 删除用户:userdel -r name "-r"表示删除对应用户的目录 修改密码:passwd name 切换用户:su - ...