python爬虫笔记之爬取足球比赛赛程
目标:爬取某网站比赛赛程,动态网页,则需找到对应ajax请求(具体可参考:https://blog.csdn.net/you_are_my_dream/article/details/53399949)
# -*- coding:utf-8 -*-
import sys
import re
import urllib.request link = "https://***"
r = urllib.request.Request(link)
r.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')
html = urllib.request.urlopen(r,timeout=500).read()
html = bytes.decode(html,encoding="gbk")
#返回大量json,需提取 #找出返回json中对应正则匹配的字符串
js = re.findall('"n":"(.*?)"',html)
i=0 #循环打印比赛信息
try:
while(1):
#将字符串Unicode转化为中文,并输出
print (js[i].encode('utf-8').decode('unicode_escape'),js[i+1].encode('utf-8').decode('unicode_escape'),"VS",js[i+2].encode('utf-8').decode('unicode_escape'))
i=i+3
#当所有赛程爬取结束时,会报错“IndexError:list index out of range”,所以进行异常处理
except IndexError:
print ("finished")
总结注意点:
1、python 3 采用这个import urllib.request
因为urllib和urllib2合体了。
2、字符串Unicode转为中文需注意python3与python2的表示方法不同:
python3:print 字符串.encode('utf-8').decode('unicode_escape')
python2:print 字符串.decode('unicode_escape')
3、re.findall()
关于这个函数,他的输出内容规律可以参考我之前写的:http://www.cnblogs.com/4wheel/p/8497121.html
【"n":"(.*?)"】 这个表达式只输出(.*?)这部分(为什么,还是参考我之前写的那篇文章),加上问号就是非贪婪模式,不加就是贪婪模式,顺便实践解释下贪婪模式
example:
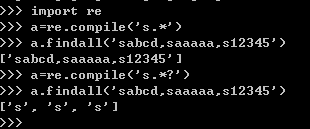
总结:非贪婪模式就是在满足正则表达式的情况下,尽可能少的匹配。
相反,贪婪模式就是在满足正则表达式的情况下,尽可能多的匹配。
so,爬取结果为:

python爬虫笔记之爬取足球比赛赛程的更多相关文章
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
随机推荐
- 利用BLCR加速android的启动(zygote加入checkpoint支持)
目前基于android4.2.2基线代码的blcr扩展,编译和启动是没有问题了,但是一重启就挂了. 弄这个有段时间了,很纠结,没有个可靠的结果,但是研究到现在,又舍不得放弃. 我想除了shuaiwen ...
- NFS服务设置
1.安装NFS服务sudo apt-get install nfs-common nfs-kernel-server 2.配置NFS服务首先需要手动编辑/etc/exports配置文件 权限参数说明如 ...
- 初涉Delphi Socket编程
不是第一次接触socket编程了,但以前都是看别人的依葫芦画瓢,也不知道具体的原理. 新的项目,有了新的开始,同时也需要有新的认识. Delphi 中带有两套TCP Socket组件: Indy So ...
- 海康威视频监控设备Web查看系统(三):Web篇
声明:本系列文章只提供交流与学习使用.文章中所有涉及到海康威视设备的SDK均可在海康威视官方网站下载得到.文章中所有除官方SDK以为的代码均可随意使用,任何涉及到海康威视公司利益的非正常使用由使用者自 ...
- python遍历多个列表生成列表或字典
key=['a','b','c','d'] value=[1,2,3,4] mydict=dict(zip(key,value)) print mydict 输出结果: {'a': 1, 'c': 3 ...
- mongodb批量更新操作文档的数组键
persons文档的数据如下: > db.persons.find(){ "_id" : 2, "name" : 2 }{ "_id" ...
- 在 Windows 中编译 Github 中的 GO 项目
1.相关软件与环境准备 1.1 GO 安装 下载地址,https://studygolang.com/dl,选择 Windows 版,本文安装到 D:\Go 1.2 LiteIDE 安装 下载地址,h ...
- 04 Javascript的运算符
js中的运算符跟python中的运算符有点类似,但也有不同.所谓运算,在数学上,是一种行为,通过已知量的可能的组合,获得新的量. 1.赋值运算符 以var x = 12,y=5来演示示例| 2.算数运 ...
- Spring事务原理一探
概括来讲,事务是一个由有限操作集合组成的逻辑单元.事务操作包含两个目的,数据 一致以及操作隔离.数据一致是指事务提交时保证事务内的所有操作都成功完成,并且 更改永久生效:事务回滚时,保证能够恢复到事务 ...
- Python自学day-6
一.编程范式 编程:程序员用特定的语法.数据结构和算法告诉计算机如何执行任务的过程.实现任务有很多不同的方式,根据编程方式的特点进行归纳总结出来的编程方式类别,就叫编程范式.大多数语言只支 ...