强化学习之CartPole
0x00 任务
通过强化学习算法完成倒立摆任务,控制倒立摆在一定范围内摆动。
0x01 设置jupyter登录密码
jupyter notebook --generate-config
jupyter notebook password (会输入两次密码,用来验证)
jupyter notebook 登录
0x02 创建python note
0x03 代码
# 声明包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import gym
# 声明绘图功能
from JSAnimation.IPython_display import display_animation
from matplotlib import animation
from IPython.display import display
def display_frames_as_gif(frames):
plt.figure(figsize=(frames[0].shape[1]/72.0,frames[0].shape[0]/72.0),dpi=72)
patch=plt.imshow(frames[0])
plt.axis("off")
def animate(i):
patch.set_data(frames[i])
anim=animation.FuncAnimation(plt.gcf(),animate,frames=len(frames),interval=50)
anim.save('move_carpole.mp4') # 保存动画
display(display_animation(anim,default_mode='loop'))
# 随机移动CartPole
frames=[]
env=gym.make('CartPole-v0')
observation=env.reset() # 重置环境
for step in range(0,200):
frames.append(env.render(mode='rgb_array')) # 加载各个时刻图像到帧
action=np.random.choice(2) # 随机返回: 0 小车向左,1 小车向右
gym.logger.set_level(40)
observation,reward,done,info=env.step(action) # 执行动作
运行后
移动 Caprpole的代码并不重要,重要的是最后一行observation,reward,done,info=env.step(action)
reward 是 即时奖励,若执行了action后,小车位置在+-2.4范围之内而且杆的倾斜成都没有超过20.9°,则设置奖励为1.相反,若小车移出+-2.4范围或者杆倾斜超过了20.9°的话,则奖励为0。退出时 done是一个变量。若为结束状态 则为true
这里代码忽略了done, info变量保存调试信息。
最后使用display_frames_as_gif(frames) 函数去保存我们的gif
# 保存并绘制视频
display_frames_as_gif(frames)

可正常保存视频
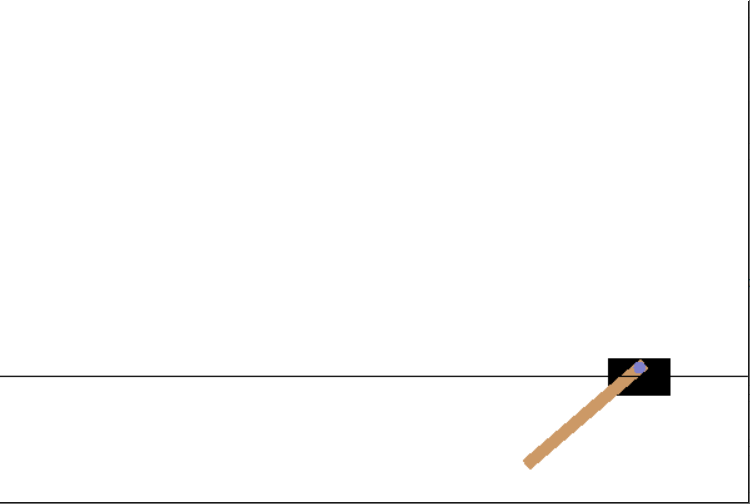
CartPole的状态
之前讨论的迷宫问题中,状态指的是每个格子的编号,由单个变量表示,0~8,然而倒立摆具有更复杂的状态定义。
CartPole的状态存储在observation中,变量observarion是4个变量组成的列表,每个变量的内容如
小车位置 -2.4~2.4
小车速度 -∞~+∞
杆的角度 -41.8°~+41.8°
杆的角速度 -∞~+∞
因为变量是连续值,如果想要通过表格的形式来表达Q函数,就需要将他们进行离散化
比如使用0~5来标记变量的连续值
-2.4~-1.6=0
-1.6~-0.8=1
依次类推
则总共有6的4次方总组合 1296种类型 数字 表示 CartPole的状态
而这个时候小车的方向只有向左和向右
所以,可以用1296行x2列的表格来表示Q函数
算法实现
- 变量设置
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import gym
# 变量设定
ENV='CartPole-v0' # 设置任务名
NUM_DIZITIZED=6 # 设置离散值个数
# 尝试运行 CartPole
env=gym.make(ENV) # 设置要执行的任务
observarion=env.reset() # 环境初始化
- 求取用于离散化的阙值
# 求取用于离散化的阙值
def bins(clip_min,clip_max,num):
return np.linespace(clip_min,clip_max,num+1)[1:-1] # 返回[-1.6,-0.8,0,0,0.8,1.6]
-∞~-1.6=0 -1.6~0.8=1
依次类推
- 创建函数 根据获得的阙值对连续变量进行离散化
def digitize_state(observation):
cart_pos,cart_v,pole_angle,pole_v=observation
digitized=[
np.digitize(cart_pos,bins=bins(-2.4,2.4,NUM_DIZITIZED)),
np.digitize(cart_v,bins=bins(-3.0,3.0,NUM_DIZITIZED)),
np.digitize(pole_angle,bins=bins(-0.5,0.5,NUM_DIZITIZED)),
np.digitize(pole_v,bins=bins(-2.0,2.0,NUM_DIZITIZED))
]
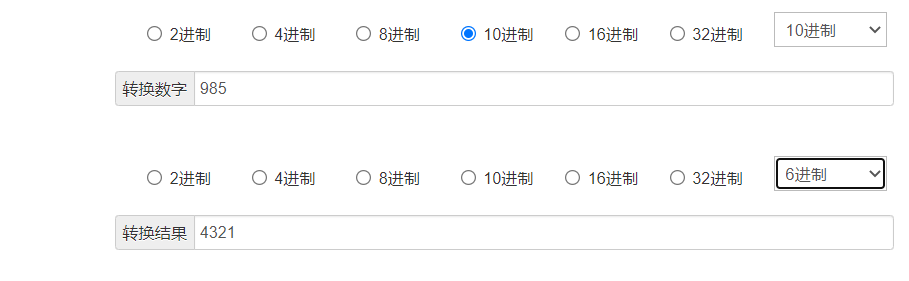
return sum([x*(NUM_DIZITIZED)**i) for i,x in enumerate(digitized)])
以6进制进行计算 如果 存在一个离散值(1,2,3,4) 则求得当前状态值为 160+2*61+362+4*63=985
- Q学习实现
这里需要定义实现类,主要有三个类 Agent Brain 和 Environmet
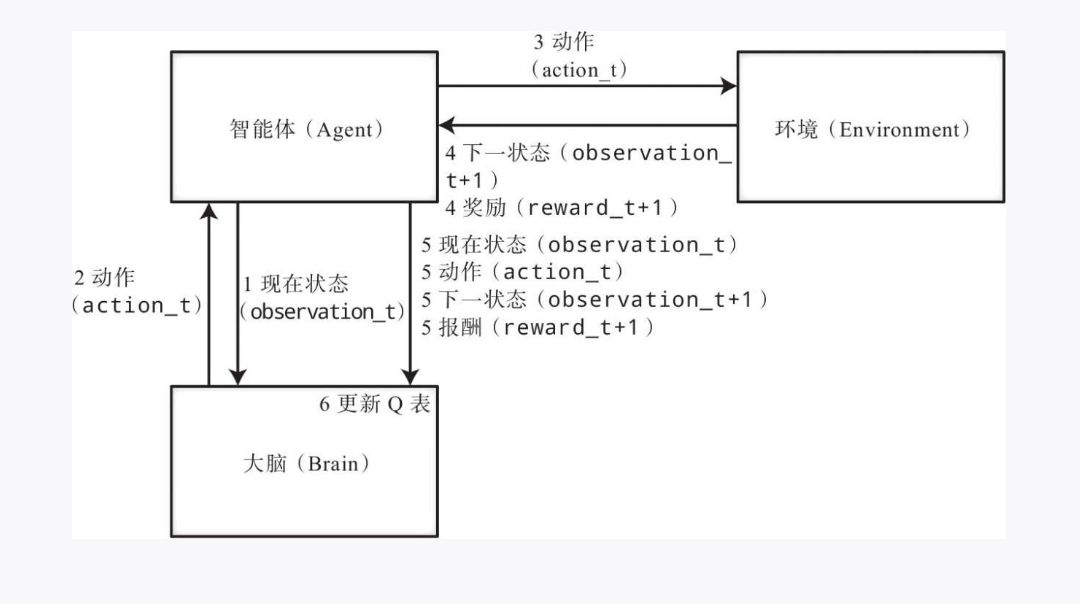
Agent类表示小推车对象,主要有2个函数,更新Q函数,和确定下一步动作函数
Agent中有一个Brain类的对象作为成员变量。
Brain类可认为是Agent的大脑,通过Q表来实现Q学习,主要有4个函数 bin digitize_state 用来离散化Agent观察到的observation
函数update_Q_table来更新Q表
函数decision_action 来确定来自Q表的动作。
为什么需要将Agent和Brain类分开》? 因为如果使用深度强化学习,将表格型Q改成深度强化学习时只需要改变Brain类就行了。
Environment类是OpenAI Gym的执行环境,执行CartPole环境的是run函数
- start
首先我们需要决定要执行的值动作,所以 Agent将当前状态 observation_t传给Brain ,Brain 离散化状态再根据Q表来确定动作,并将确定的动作返回给Agent,
之后是动作的实际执行环境步骤,Agent将动作action_t传递给Environment,Environment执行动作action_t并将执行后的状态observation_t+1和即时奖励 reward+1 返回给Agent
再更新Q 表, Agent将当前状态observation_t 执行动作 action_t 和执行动作后的observation_t+1 即时奖励reward_t+1传回给Brain,Brain更新Q表,这4个变量综合起来被称为transition
之后 重复该过程就行了,因为获得最大价值的方式只有一种,所以通过Q学习不断拟合,最后会形成唯一解。
0x04 强化学习之Q学习的原理(重点!)-》瞬间开悟
观察代码 self.q_table[state,action]=self.q_table[state,action]+ETA(reward+GAMMAMax_Q_next-self.q_table[state,action]) ,刚开始看时,一脸懵逼,直到想通了某个点。
首先我们需要清楚在大量的数据面前,能够满足我们想要的最好的策略 只有一条,有些时候我们可以自己求得该策略,比如迷宫问题,我们可以轻松做到,这里的倒立摆问题我们也能轻松做到,但是小球消方块呢? 我们人类几乎不能在很短时间做出判断,然后消除掉所有的方块,但是机器能。为什么?
满足最优策略只有一条,大数据训练只是为了让我们的策略最终拟合成为最优策略
还是拿这段代码来说 self.q_table[state,action]=self.q_table[state,action]+ETA(reward+GAMMAMax_Q_next-self.q_table[state,action]) Q表的更新是当前Q表+变化值。
所以Q表的更新量其实就是 ETA*(reward+GAMMA*Max_Q_next-self.q_table[state,action])
ETA是学习率。 reward是奖励,这里可以认为是0, GAMMA是时间折扣率为0.99 接近为1 self.q_table[state,action] 为当前Q表,记录了当前状态和当前的方向。
当我们设置变化值为很小时,最终实现Q表几乎不变,此时Q表代表了我们的最优策略。 但是为什么,为什么它就能拟合到最优,而不是别的?每次拟合的过程是什么?
抽象概念
我们可以假设有1000多个大的游泳池,我们设定的阙值范围用游泳圈来表示,水的体积来表示数据范围,策略可用来表示水体积的变化。第一个游泳池我们随机生成,游泳池里灌满了水,游泳圈的数量固定,当我们的智能体根据当前策略进行了运动,而我们定义的策略是如果到达我们的目标则获得奖励,抽象到游泳池可以认为是,我们从第一个游泳池跳到第二个游泳池的游泳圈范围里。当我们这样做后会得到奖励,因为奖励的存在,使得我们不断往游泳圈跳来获得最大价值,在一,二,三的泳池中,
强化学习之CartPole的更多相关文章
- 【转载】 深度强化学习处理cartpole为什么reward很难超过200?
原贴地址: https://www.zhihu.com/question/266493753 一直在看强化学习方面的内容,cartpole是最简单的入门实验环境,最原始的评判标准是连续100次epis ...
- 强化学习 CartPole实验的一些启发 有没有可能设计一个新的实验呢?(杆子可以向360度方向倾倒,可行吗?)
最近在看强化学习方面的东西,突然想到了这么一个事情,那就是经典的CartPole游戏我们改变一下,或者说升级一下,那么使用强化学习是否能得到不错的效果呢? 原始游戏如图: 一点个人的想法: ===== ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 强化学习(十五) A3C
在强化学习(十四) Actor-Critic中,我们讨论了Actor-Critic的算法流程,但是由于普通的Actor-Critic算法难以收敛,需要一些其他的优化.而Asynchronous Adv ...
- 强化学习(九)Deep Q-Learning进阶之Nature DQN
在强化学习(八)价值函数的近似表示与Deep Q-Learning中,我们讲到了Deep Q-Learning(NIPS 2013)的算法和代码,在这个算法基础上,有很多Deep Q-Learning ...
- 【转载】 强化学习(九)Deep Q-Learning进阶之Nature DQN
原文地址: https://www.cnblogs.com/pinard/p/9756075.html ------------------------------------------------ ...
- 强化学习之Q-learning简介
https://blog.csdn.net/Young_Gy/article/details/73485518 强化学习在alphago中大放异彩,本文将简要介绍强化学习的一种q-learning.先 ...
- Ubuntu下常用强化学习实验环境搭建(MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2)
http://lib.csdn.net/article/aimachinelearning/68113 原文地址:http://blog.csdn.net/jinzhuojun/article/det ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
随机推荐
- visual studio 将他人的 vtk 程序在本机生成
在网上下载了一些关于vtk的资源,在本机使用visual studio 打开后,生成时出现类似与以下的错误 无法打开包括文件:"vtkStructuredPointsToPolyDataFi ...
- Day003 数据类型拓展
数据类型拓展 整数拓展 进制 通常我们使用的都是10进制的整数,java中可以表示不同进制的整数 进制 表示方法 二进制 0b 八进制 0 十进制 默认 十六进制 0x 看看下面这个例子吧 int ...
- 实时计算框架:Flink集群搭建与运行机制
一.Flink概述 1.基础简介 Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算.Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算.主要特性包 ...
- 【vue】报错This dependency was not found
报错 ERROR Failed to compile with 1 errors 10:33:34 ├F10: PM┤ This dependency was not found: * @/views ...
- Mybatis-Plus02 CRUD
先将快速开始01看完,再看这个文档 配置日志 我们所有的sql现在都是不可见的,我们希望知道它是怎么执行的,所以我们就必须看日志,开发的时候打开,上线的时候关闭 在application.proper ...
- 学javaweb 先学Servlet 应用理论很重要
package cn.Reapsun.servlet; import java.io.IOException; import java.io.PrintWriter; import javax.ser ...
- SpringBoot系列——自定义统一异常处理
前言 springboot内置的/error错误页面并不一定适用我们的项目,这时候就需要进行自定义统一异常处理,本文记录springboot进行自定义统一异常处理. 1.使用@ControllerAd ...
- Python设计模式知多少
设计模式 设计模式是前辈们经过相当长的一段时间的试验和错误总结出来的最佳实践.我找到的资料列举了以下这些设计模式:工厂模式.抽象工厂模式.单例模式.建造者模式.原型模式.适配器模式.桥接模式.过滤器模 ...
- 大量客户名片如何轻松导入到CRM系统里?
当您组织或参与了一次线下活动或展会,肯定会收集到非常多的潜在客户的名片.这个时候您是不是在发愁如何将这些信息导入到CRM系统中? 可以想到,您肯定会将这些名片分发给销售人员,让他们手动录入--这也确实 ...
- CSS3文本样式
目录 文本阴影 text-shadow 文本轮廓 text-outline 文本换行 word-break normal break-all keep-all word-wrap 新文本属性 text ...