【转载】 深度强化学习处理cartpole为什么reward很难超过200?
原贴地址:
https://www.zhihu.com/question/266493753
一直在看强化学习方面的内容,cartpole是最简单的入门实验环境,最原始的评判标准是连续100次episode的奖励均值在195以上即可认定是到达最优,说明此问题得以解决,(但是有很多的研究是没有采用这个条件的,也就是按照训练的次数固定,在一定的训练次数后看测试时的奖励均值和方差)。如果我们不按照这个评价标准来运行该环境的话,那么我们需要对gym中的某些原始设定进行修改。
----------------------------------------------------------------------------------------

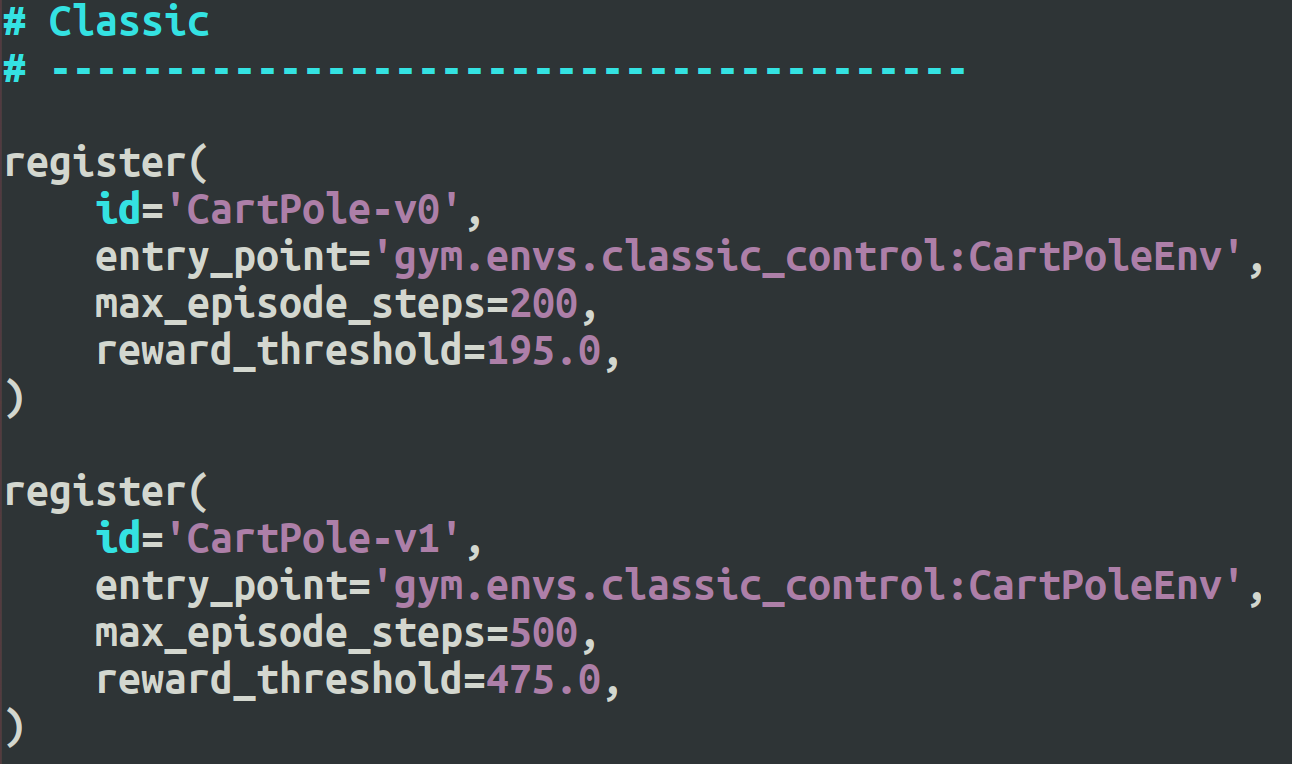
在文件gym/envs/__init__.py 中,限定了max_episode_steps
register(
id='CartPole-v0',
entry_point='gym.envs.classic_control:CartPoleEnv',
max_episode_steps=200,
reward_threshold=195.0,
)
作者:冰璐
链接:https://www.zhihu.com/question/266493753/answer/317795225
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

【转载】 深度强化学习处理cartpole为什么reward很难超过200?的更多相关文章
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 【转载】 强化学习(八)价值函数的近似表示与Deep Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9714655.html ------------------------------------------------ ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 【转载】 强化学习(七)时序差分离线控制算法Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9669263.html ------------------------------------------------ ...
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- 强化学习之CartPole
0x00 任务 通过强化学习算法完成倒立摆任务,控制倒立摆在一定范围内摆动. 0x01 设置jupyter登录密码 jupyter notebook --generate-config jupyt ...
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 【转载】 强化学习(五)用时序差分法(TD)求解
原文地址: https://www.cnblogs.com/pinard/p/9529828.html ------------------------------------------------ ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
随机推荐
- 关于ORA-06508 , ORA-04068异常的详细说明
参考:程序包调用报ORA-06508: PL/SQL: 无法找到正在调用的程序单元 出现这种情况的原因是因为,对于全局变量,每一个session会生成一个本地copy,如果程序重新编译的话,就会因程序 ...
- Spring注解之BeanPostProcessor与InitializingBean
/*** BeanPostProcessor 为每个bean实例化时提供个性化的修改,做些包装等*/ package org.springframework.beans.factory.config; ...
- C++ leetcode::ZigZag Conversion
mmp,写完没保存,又得重新写.晚上写了简历,感觉身体被掏空,大学两年半所经历的事,一张A4纸都写不满,真是一事无成呢.这操蛋的生活到底想对我这个小猫咪做什么. 今后要做一个早起的好宝宝~晚起就诅咒自 ...
- Android Studio向项目添加C/C++原生代码教程
说明:本文相当于官方文档的个人重新实现,官方文档链接:https://developer.android.com/studio/projects/add-native-code 向项目添加C/C++代 ...
- linux过滤旧文件中的空行和注释行剩余内容组成新文件
一.说明 在某些场景下我们想要将旧文件中空行和注释行过滤掉,将产生实际效果的行保留. 比如redis提供的配置示例文件中有很多用于说明的空行和注释行,我们想把产生实际效果的配置行筛选出来组成新的简洁的 ...
- sudo配置教程
一.相关说明 1.sudo配置文件是/etc/sudoers:另外会自动包含/etc/sudoers.d目录下的文件(/etc/sudoers文件最后有一句“#includedir /etc/sudo ...
- 使用Spring-data-jpa(2)(三十一)
创建实体 创建一个User实体,包含id(主键).name(姓名).age(年龄)属性,通过ORM框架其会被映射到数据库表中,由于配置了hibernate.hbm2ddl.auto,在应用启动的时候框 ...
- Author and Submission Instructions
This document contains information about the process of submitting a paper to NIPS 2014. You can als ...
- PHP7 ci框架session存文件,登录的时候session不能读取
config.php配置 $config['sess_driver'] = 'files';//以文件存储session $config['sess_cookie_name'] = 'ci_sessi ...
- 重绘(Repaint)和回流(Reflow)
重绘(Repaint)和回流(Reflow) 1.回流和重绘只是渲染步骤的一小节,是怎么做到影响性能的? css 会影响 javascrip 执行时间导致 javascript 脚本变慢 浏览器渲染一 ...