深入理解Linux文件系统与日志文件
目录:
一、inode与block
二、inode内容
三、inode的号码
四、inode的大小
五、链接文件
六、inode节点耗尽故障处理
七、恢复EXT类型的文件编译安装extundelete软件包
八、xfs类型文件的备份和恢复
九、日志文件
十、内核及系统日志
十一、用户日志文件
十二、程序日志分析
十三、日志管理策略
一、inode与block
inode和block概述
文件数据包括元信息与实际数据
文件存储在硬盘上,硬盘最小存储单位是"扇区",每个扇区存储512字节
block(块)
- 连续的八个扇区组成一个 block(4K)
- 是文件存取的最小单位
inode (索引节点)
- 中文译名为"索引节点",也叫i节点
- 用于存储文件元信息
知识拓展
文件是存储在硬盘上的,硬盘的最小存储单位叫做"扇区"(sector),每个扇区存储512字节。
一般连续八个扇区组成一个"块"(block),一个块是4K大小,是文件存取的最小单位。操作系统读取硬盘的时候,是一次性连续读取多个扇区,即一个块一个块的读取的。
文件数据包括实际数据与元信息(类似文件属性)。文件数据存储在"块"中,存储文件元信息(比如文件的创建者、创建日期、文件大小、文件权限等)的区域就叫做inode。因此,一个文件必须占用一个 inode,并且至少占用一个 block。 inode不包含文件名。文件名是存放在目录当中的。Linux 系统中一切皆文件,因此目录也是一种文件。
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称,文件名和inode号码是一一对应关系,每个inode号码对应一个文件名。
所以,当用户在Linux系统中试图访问一个文件时,系统会先根据文件名去查找它对应的inode号码; 通过inode号码,获取inode信息; 根据inode信息,看该用户是否具有访问这个文件的权限;如果有,就指向相对应的数据block,并读取数据。
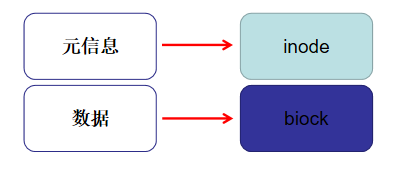
注:一个文件必须占用一个inode,但至少也占用一个block
二、inode的内容
1)inode包含文件的元信息
- 文件的字节数
- 文件拥有者的User ID
- 文件的Group ID
- 文件的读、写、执行权限
- 文件的时间戳
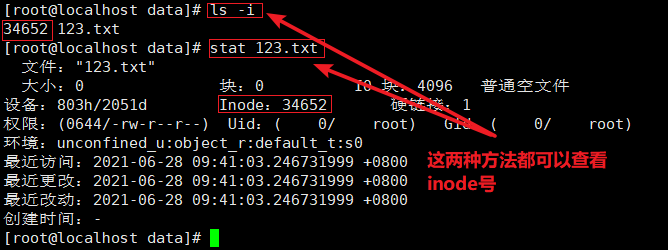
2)用命令可以查看某个文件的inode信息
两种方法
ls -i 文件名 stat 文件名
3)Linux系统文件三个主要的时间属性
atime (accesstime):
当使用这个文件的时候就会更新这个时间。
mtime (modification time) :
当修改文件的内容数据的时候,就会更新这个时间,而更改权限或者属性,mtime不会改变,这就是和ctime的区别。
ctime (status time) :
当修改文件的权限或者属性的时候,就会更新这个时间,ctime并不是create time,更像是change time,只有当更新文件的属性或者权限的时候才会更新这个时间,但是更改内容的话是不会更新这个时间。
4)目录文件的结构
- 目录也是一种文件
- 目录文件的结构
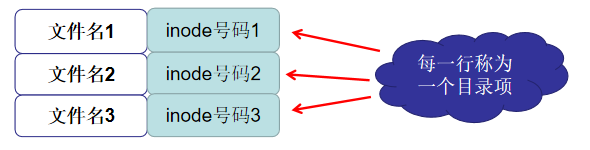
每个inode都有一个号码,操作系统用inode号码来识别不同的文件
Linux系统内部不使用文件名,而使用inode号码来识别文件
对于用户,文件名只是inode号码便于识别的别称
三、inode的号码
1、用户通过文件名打开文件时,系统内部的过程
- 系统找到这个文件名对应的inode号码
- 通过inode号码,获取inode信息
- 根据inode信息,找到文件数据所在的block,读出数据
2、硬盘分区后的结构
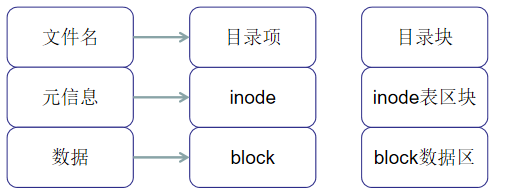
3、 访问文件的简单流程
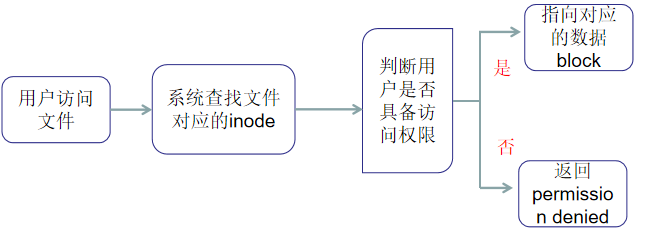
四、inode的大小
1、inode也会消耗硬盘空间
- 每个inode的大小
- 一般是128字节或256字节
格式化文件系统时确定inode的总数
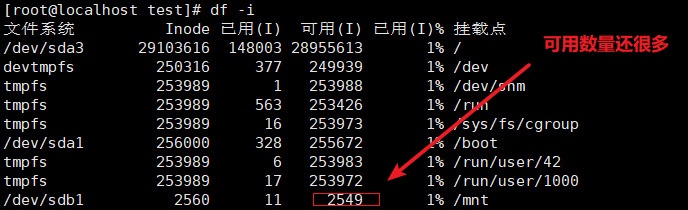
使用df -i命令可以查看每个硬盘分区的inode总数和已经使用的数量
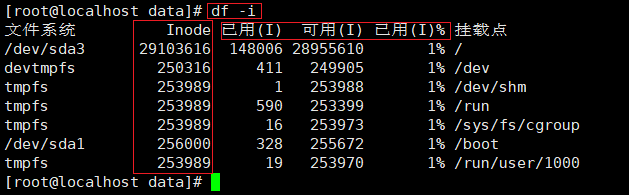
inode也会消耗硬器空间,所以格式化的时候,操作系统白动将矿盘分成两个区域。一个是数据,存放文件数据;另一个是 inode区,存放 inode 所包含的信息。每个 inode 的大小,一般是 128 字节或 256 字节。
通常情况下不需要关注单个 inode 的大小,而是需要重点关注 inode 总数。inode 的总数在格式化时就给定了,执行 "df-i"命令即可查看每个硬盘分区对应的的 inodo 总数和已经使用的inode 数量。
2、由于 inode 号码与文件名分离,导致Linux 系统具备以下几种特有的现象∶
1.文件名包含特殊字符,可能无法正常删除。这时直接删除 inode,能够起到删除文件的作用;
2.移动文件或重命名文件,只是改变文件名,不影响 inode 号码;
3.打开一个文件以后,系统就以 inode 号码来识别这个文件,不再考虑文件名。
4.文件数据被修改保存后,会生成一个新的 inode 号码。
find ./ -inum 52305140 -exec rm -i {} \;
find . /-inum 50464299 -delete
注:如果你移动到挂载目录下,会发现inode号也会改变
五、链接文件
为文件或目录建立链接文件
链接文件分类

标记文本
In 源文件 目标位置
软链接
In 【-s】源文件或目录…链接文件或目标位置
六、inode节点耗尽故障处理
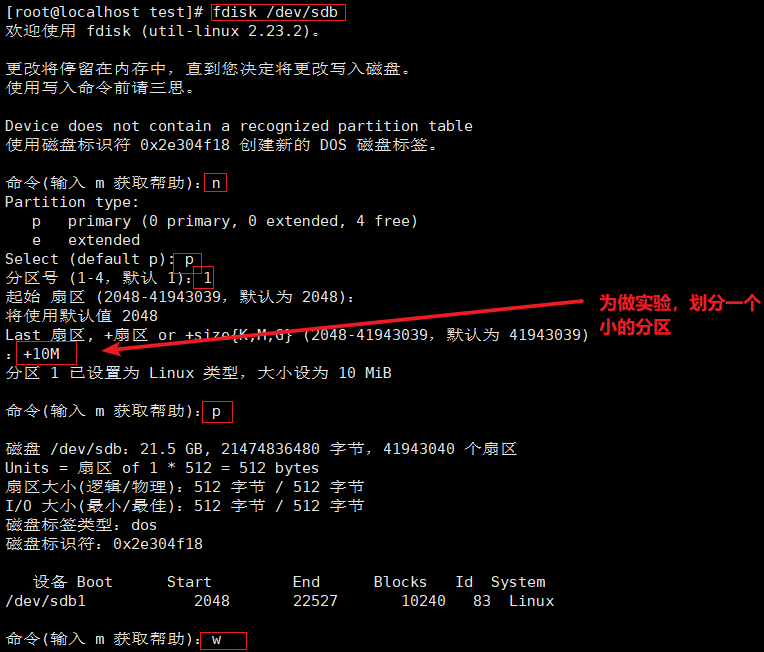
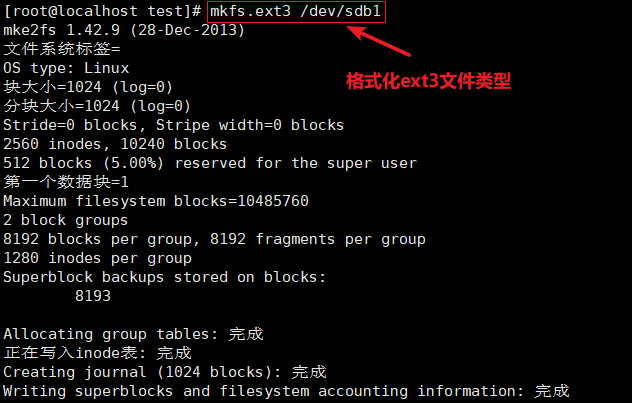
#使用fdisk创建分区/dev/sdb1,分区大小30M即可
fdisk /dev/ sdb .
mkfs.ext4 /dev/ sdb1
mkdir /test
mount /dev/sdb1 /mnt
df -i #模拟inode节点耗尽故障
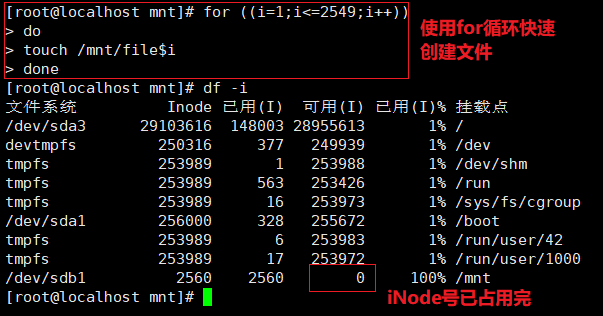
for ( (i=1; i<=7680; i++) )
>do
>touch /test/ file$i
>done
touch {1. . 7680} . txt df -i
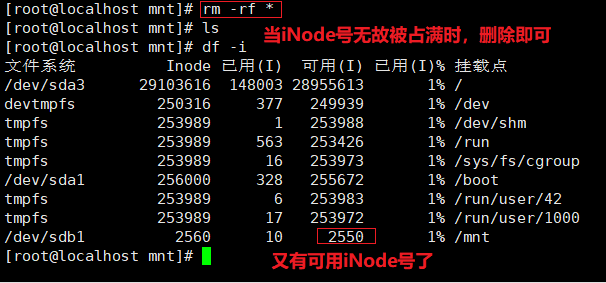
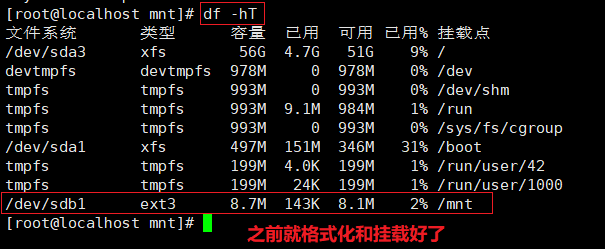
df -hT #删除文件恢复
rm -rf /test/ *
df -i
df -hT
举例

七、恢复EXT类型的文件编译安装extundelete软件包
安装依赖包
- e2fsprogs-libs-1.41.12-18.el6.x86_64.rpm
- e2fsprogs-devel-1.41.12-18.el6.x86_64.rpm
配置、编译及安装
- extundelete-0.2.4.tar.bz2
#使用fdisk创建分区/dev/sdc1,格式化ext3文件系统
fdisk /dev/sdb
partprobe /dev/sdb
mkfs.ext3 /dev/ sdb1
mkdir /mnt
mount /dev/sdb1 /mnt
df -hT #安装依赖包
yum -y install e2fsprogs-devel e2 fsprogs-l ibs #编译安装extundelete
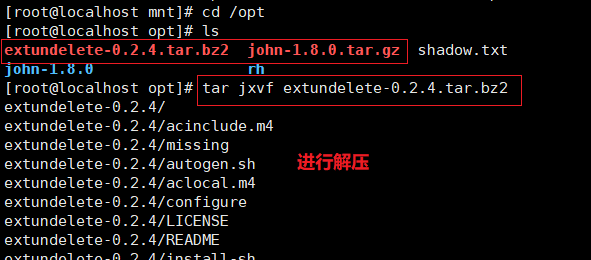
cd /opt
wget http: //nchc.dl.sourceforge.net/project/extundelete/extundelete/0.2.4/extundelete-0.2.4.tar.bz2 tar jxvf extundelete-0.2.4.tar.bz2
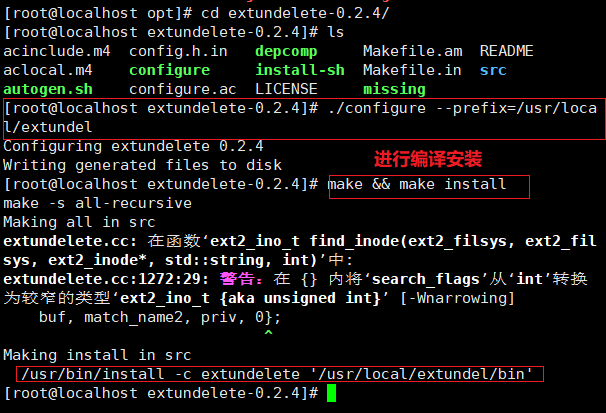
cd extundelete-0.2.4/
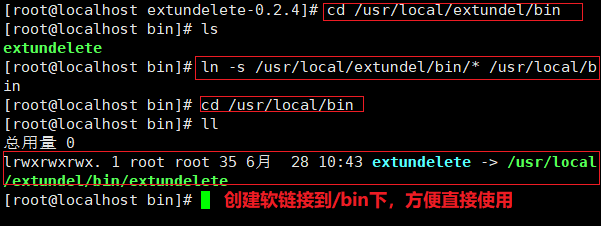
./configure --prefix=/usr/ local/ extundelete && make && make install ln -s /usr/ local/extundelete/bin/* /usr/bin/
模拟删除并执行恢复操作
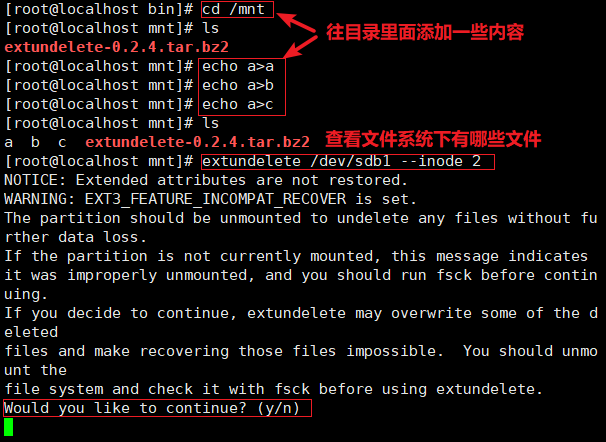
cd /mnt
echo a>a
echo a>b
echo a>C .
echo a>d
ls extundelete /dev/sdb1 --inode 2
#查看文件系统/dev/sdc1下存在哪些文件,i节点是从2开始的,2代表该文件系统最开始的目录 rm-rf a b
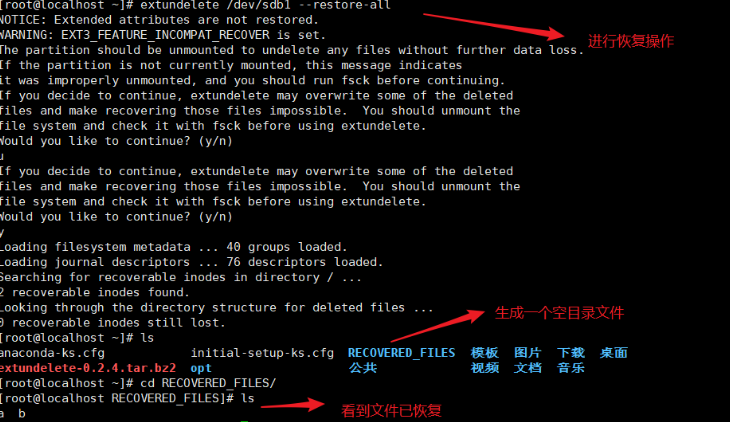
extundelete /dev/sdc1 -- inode 2
cd ~
umount /mnt
extundelete /dev/sdc1 --restore-all
#恢复/dev/sdc1文件系统下的所有内容 #在当前目录下会出现一-个RECOVERED_ FILES/目录,里面保存了已经恢复的文件
ls RECOVERED_FILES/
举例

八、xfs 类型文件备份和恢复
Centos 7 系统默认采用 xfs类型的文件,xfs 类型的文件可使用 xfsdump 与 xfsrestore 工具进行备份恢复,区xfsdump 的备份级别有两种∶ 0 表示完全备份; 1-9 表示增量备份。xfsdump 的备份级别默认为 0。
xfsdump 的命令格式为∶
xfsdump -f 备份存放位置 要备份的路径或设备文件
xfsdump 命令常用的选项∶-f∶指定备份文件目录
-L∶指定标签 session label
-M∶ 指定设备标签 media labe1
-s∶备份单个文件,-s 后面不能直接跟路径
xfsdump使用限制∶
1.只能备份已挂载的文件系统
2.必须使用root的权限才能操作
3.只能备份XFS文件系统
4.备份后的数据只能让xfsrestore解析
5.不能备份两个具有相同UUID的文件系统 (可用 blkid命令查看)
#使用fdisk创建分区/dev/sdb1,格式化xfs文件系统
fdisk /dev/ sdb
partprobe /dev/ sdb
mkfs.xfs [-f] /dev/ sdb1
mkdir /data
mount /dev/ sdb1 /data/
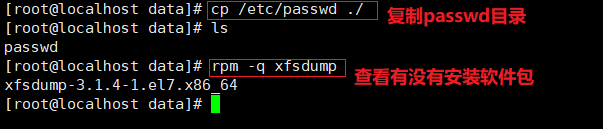
cd /data
cp /etc/passwd ./
mkdi rtest
touch test/a #使用xfsdump 命令备份整个分区
rpm -qa| grep xfsdump
yum install -y xfsdump
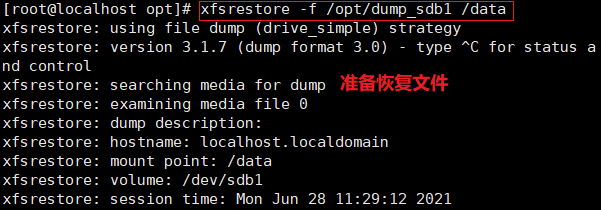
xfsdump -f /opt/dump_sdb1 /dev/sdb1 [-L dump sdb1 -M sdb1 ] #模拟数据丢失并使用 x fsrestore 命令恢复文件
cd /data/
rm -rf ./*
ls xfsrestore -f /opt/dump_ sdb1 /data/
举例




九、日志文件
1、日志的功能
- 用于记录系统、程序运行中发生的各种事件
- 通过阅读日志,有助于诊断和解决系统故障
2、日志文件的分类
内核及系统日志
- 由系统服务rsyslog统一进行管理,日志格式基本相似
- 主配置文件/etc/rsyslog.conf
用户日志
- 记录系统用户登录及退出系统的相关信息
程序日志
3、日志保存位置
●默认位于∶/var/log目录下
内核及公共消息日志
/var/log/messages
记录Linux内核消息及各种应用程序的公共日志信息,包括启动、Io错误、网络错误、程序故障等
/var/log/cron
记录crond计划任务产生的事件信息
/var/log/dmesg
记录Linux系统在引导过程中的各种事件信息
/var/log/maillog
记录进入或发出系统的电子邮件活动
/var /log/lastlog
记录每个用户最近的登录事件,二进制格式
记录用户认证相关的安全事件信息
记录每个用户登录、注销及系统启动和停机事件,二进制格式
记录失败的、错误的登录尝试及验证事件,二进制格式

十、内核及系统日志
1、由系统服务 rsyslog 统一管理
- 软件包∶rsyslog-7.4.7-16.el7.x86_64
- 主要程序∶ /sbin/rsyslogd
- 配置文件∶ /etc/rsyslog.conf
2、日志消息的级别
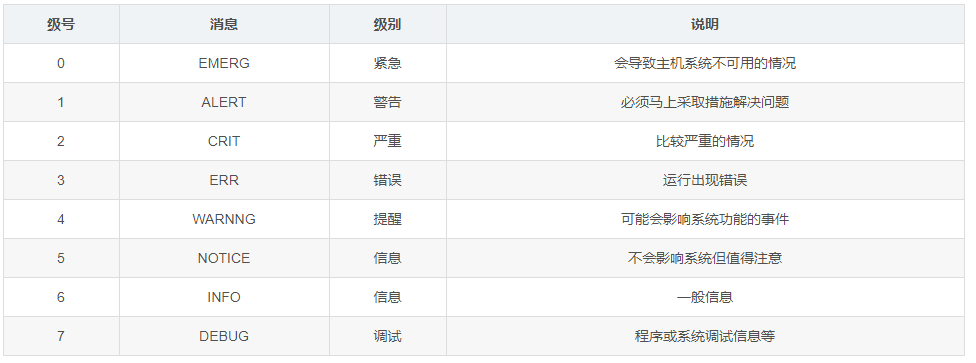
注:数字等级越小,优先级越高,消息越重要
日志记录的一般格式

时间标签: 消息发出的日期和时间
主机名: 生成消息的计算机的名称
子系统名称: 发出消息的应用程序的名称
消息: 消息的具体内容
十一、用户日志分析
1、保存了用户登录、退出系统等相关信息
- /var/log/lastlog∶ 最近的用户登录事件
- /var/log/wtmp∶ 用户登录、注销及系统开、关机事件
- /var/run/utmp∶ 当前登录的每个用户的详细信息
- /var/log/secure: 与用户验证相关的安全性事件
2、分析工具
- users、who、w、last、lastb
- last 命令用于查询成功登录到系统的用户记录
- lastb 命令用于查询登录失败的用户记录

十二、程序日志分析
1、由相应的应用程序独立进行管理
Web服务∶ /var/log/httpd/
- access_log //记录客户访问事件
- error_log //记录错误事件
代理服务∶ /var/og/squid/
- access.log、cache.log
2、分析工具
- 文本查看、grep过滤检索、Webmin管理套件中查看
- awk、sed等文本过滤、格式化编辑工具
- Webalizer、Awstats等专用日志分析工具
十三、日志管理策略
1、及时作好备份和归档
2、延长日志保存期限
3、控制日志访问权限
- 日志中可能会包含各类敏感信息,如账户、口令等
4、集中管理日志
- 将服务器的日志文件发到统一的日志文件服务器
- 便于日志信息的统一收集、整理和分析
- 杜绝日志信息的意外丢失、恶意篡改或删除
总结
1、 block与inode
2、 硬链接与软链接
3、恢复误删除的文件
4、 Linux主要包含的日志文件
5、 Linux系统的日志消息级别
6、 Linux系统中用户日志的查询命令
(who、W、users、 last、 lastb)
深入理解Linux文件系统与日志文件的更多相关文章
- 深入理解Linux文件系统与日志分析
一.inode和bolck概述 二.链接文件 三.inode节点耗尽故障处理 四.EXT类型文件恢复 五.xfs文件备份和恢复 六.日志文件 一.inode和bolck概述 1.定义 文件数据 文件数 ...
- Linux文件系统与日志文件
目录 一.inode和block 1.1.inode和block概述 1.2.inode的内容 inode包含文件的元信息: 查看inode号两种方式 目录文件的结构 1.3.inode的号码 用户通 ...
- Linux文件系统与日志分析
Linux文件系统与日志分析一.inode与block概述① 文件数据包括元信息(类似文件属性)与实际数据② 文件存储在硬盘上,硬盘最小存储单位是"扇区"(sector),每个扇区 ...
- Linux文件系统与日志分析的了解
Linux文件系统与日志分析 1.inode和block概述 2.模拟inode耗尽实验 3.ext类型文件恢复 4.xfs类型文件恢复 5.日志文件 6.日志分析 1.文件:文件是存储在硬盘上的,硬 ...
- Linux下重要日志文件及查看方式
http://os.51cto.com/art/201108/282184_all.htm 1.Linux下重要日志文件介绍 /var/log/boot.log 该文件记录了系统在引导过程中发生的 ...
- 【Linux学习】Linux文件系统5—查看文件内容命令
Linux文件系统5-查看文件内容命令 cat: 由第一行开始显示文件内容 more: 一页一页地显示文件内容,空格键可以继续翻页显示下一页内容 less:与more类似,但是可以往前翻页 head: ...
- 理解Linux文件系统之inode
很少转发别人的文章,但是这篇写的太好了. 理解inode 作者: 阮一峰 inode是一个重要概念,是理解Unix/Linux文件系统和硬盘储存的基础. 我觉得,理解inode,不仅有助于提高系统 ...
- 理解Linux文件系统之 inode
一.inode是什么? 理解inode,要从文件储存说起. 文件储存在硬盘上,硬盘的最小存储单位叫做”扇区”(Sector).每个扇区储存512字节(相当于0.5KB). 操作系统读取硬盘的时候,不会 ...
- [转]理解Linux文件系统之inode
很少转发别人的文章,但是这篇写的太好了. 理解inode 作者: 阮一峰 inode是一个重要概念,是理解Unix/Linux文件系统和硬盘储存的基础. 我觉得,理解inode,不仅有助于提高系统 ...
随机推荐
- 栅栏密码(The Rail-Fence Cipher)详解
最近训练CTF的时候,发现密码学这块的知识不太系统,所以自己接下来会陆陆续续整理出来 今天学习了栅栏密码,BugkuCTF里面的一道叫做"聪明的小羊"的题就与栅栏密码相关 特点 栅 ...
- swift文件调用oc分类时崩溃解决办法(可能全网唯一)
背景 oc为基础创建的sdk混编工程,在被sdk关联的混编demo工程中swift文件调用时,会崩溃,提示找不到sdk中oc分类方法.常规的,在demo中设置-Objc和-all_load也还是会崩. ...
- Java 14 新功能介绍
不做标题党,认认真真写个文章. 文章已经收录在 Github.com/niumoo/JavaNotes 和未读代码博客,点关注,不迷路. Java 14 早在 2019 年 9 月就已经发布,虽然不是 ...
- 使用Freemarker导出Word文档(包含图片)代码实现及总结
.personSunflowerP { background: rgba(51, 153, 0, 0.66); border-bottom: 1px solid rgba(0, 102, 0, 1); ...
- Python函数调用中的值传递和引用传递问题
这一问题O' Reilly出版的"Learning Python" 2nd Edition的 13.4 节有专门论述,对于不可变(immutabe)对象,函数参数(这里是x和y)只 ...
- 提取网页的markdown表格利器
在线Markdown表格转换器 markdown表格转换器,蛮好用的.偶然发现的开源工具,推荐一波. 这是目标链接:https://docs.locust.io/en/stable/configura ...
- win7环境下配置JDK&&安装Weblogic12.2.1.4.0
win7环境下安装Weblogic12.2.1.4.0 写在前面 最近因为想复现一下weblogic的CVE-2020-2555和CVE-2020-2883漏洞,需要weblogic环境,但是vulh ...
- SSM整合(Maven工程)
SSM整合(Maven工程) 一.概述 SSM(Spring+SpringMVC+MyBatis)框架集由Spring.MyBatis两个开源框架整合而成(SpringMVC是Spring中的部分内容 ...
- SpringBoot请求日期参数异常(Failed-to-convert-value-of-type-'java-lang-String'-
问题 Failed to convert value of type 'java.lang.String' to required type 'java.util.Date'; nested exce ...
- 经典树与图论(最小生成树、哈夫曼树、最短路径问题---Dijkstra算法)
参考网址: https://www.jianshu.com/p/cb5af6b5096d 算法导论--最小生成树 最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树. im ...