容器之分类与各种测试(三)——list部分用法
list是一个双向链表
例程
#include<stdexcept>
#include<memory.h>
#include<string>
#include<cstdlib>//abort()
#include<stdio.h>
#include<algorithm>//find()
#include<iostream>
#include<ctime>
#include<list>
using namespace std; long get_a_target_long()
{
long target = 0;
cout<<"target(0~"<<RAND_MAX<<"):";
cin>>target;
return target;
}
string get_a_target_string()
{
long target = 0;
char buf[10];
cout<<"target(0~"<<RAND_MAX<<"):";
cin>>target;
snprintf(buf, 10, "%d", target);
return string(buf);
}
int compareLongs(const void* a, const void* b)
{
return (*(long*)a - *(long*)b);
} int compareStrings(const void *a, const void *b)
{
if(*(string*)a > *(string*)b)
return 1;
else if(*(string*)a < *(string*)b)
return -1;
else
return 0;
}
void test_list(long& value)
{
cout << "\ntest_list().......... \n"; list<string> c; //链表中存储着string类型(字符串)的数据
char buf[10]; clock_t timeStart = clock();
for(long i=0; i< value; ++i)
{
try//由于例程中的value使用一百万,所以为了防止内存不足出错,这里使用了try catch来尝试捕捉并处理错误,关于try和catch得用法可以查看这个博客
{
snprintf(buf, 10, "%d", rand());
c.push_back(string(buf));
}
catch(exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock()-timeStart) << endl;
cout << "list.size()= " << c.size() << endl; //list含有的元素个数
cout << "list.max_size()= " << c.max_size() << endl; //这里的max_size函数在不同计算机上的表现不同,具体大小和预装内存大小正相关
cout << "list.front()= " << c.front() << endl; //链表头
cout << "list.back()= " << c.back() << endl; //链表尾 string target = get_a_target_string();
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target); //::的意思是让编译器在stdio.h/iostream中寻找find方法,而不用现在当前代码中寻找
cout << "std::find(), milli-seconds : " << (clock()-timeStart) << endl; if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl; timeStart = clock();
c.sort();
cout << "c.sort(), milli-seconds : " << (clock()-timeStart) << endl;
}
int main()
{
long int value;
cout<<"how many elements:";
cin>>value;
test_list(value);
return 0;
}
运行效果
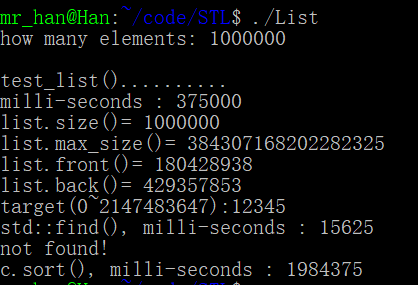
没找到
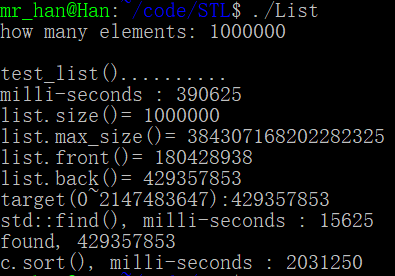
找到了
这里有个需要注意的地方,如果一个模板类有自己的排序方法时,尽量使用自己的排序方法,这一定比通用的排序方式快。
容器之分类与各种测试(三)——list部分用法的更多相关文章
- 容器之分类与各种测试(三)——stack
stack是栈,其实现也是使用了双端队列(只要不用双端队列的一端,仅用单端数据进出即完成单端队列的功能),由于queue和stack的实现均是使用deque,没有自己的数据结构和算法,所以这俩也被称为 ...
- 容器之分类与各种测试(三)——queue
queue是单端队列,但是在其实现上是使用的双端队列,所以在queue的实现上多用的是deque的方法.(只要用双端队列的一端只出数据,另一端只进数据即可从功能上实现单端队列)如下图 例程 #incl ...
- 容器的分类与各种测试(三)——deque
deque是双端队列,其表象看起来是可以双端扩充,但实际上是通过内存映射管理来营造可以双端扩充的假象,如图所示 比如,用户将最左端的buff用光时,map会自动向左扩充,继续申请并映射一个新的buff ...
- 容器之分类与各种测试(三)——slist的用法
slist和forward_list的不同之处在于其所在的库 使用slist需要包含 #include<ext\list> 而使用forward_list则需要包含 #include< ...
- 容器之分类与各种测试(三)——forward_list的用法
forward_list是C++11规定的新标准单项链表,slist是g++以前的规定的单项链表 例程 #include<stdexcept> #include<string> ...
- 容器的分类与各种测试(二)——vector部分用法
向量 vector 是一种对象实体, 能够容纳许多其他类型相同的元素, 因此又被称为容器. 与string相同, vector 同属于STL(Standard Template Library, 标准 ...
- 容器之分类与各种测试(四)——unordered-multiset
unordered-multiset是不定序关联式容器,其底部是通过哈希表实现功能. (ps:黑色框就是bucket,白色框即为bucket上挂载的元素) 为了提高查找效率,bucket(篮子)的数量 ...
- 容器之分类与各种测试(四)——multiset
multiset是可重复关键字的关联式容器,其与序列式容器相比最大的优势在于其查找效率相当高.(牺牲空间换取时间段) 例程 #include<stdexcept> #include< ...
- 容器之分类与各种测试(四)——unordered_set和unordered_map
关于set和map的区别前面已经说过,这里仅是用hashtable将其实现,所以不做过多说明,直接看程序 unordered_set #include<stdexcept> #includ ...
随机推荐
- (一)lamp 环境搭建之编译安装apache
apache的编译安装: 安装步骤大概参考:http://www.cnblogs.com/iyoule/archive/2013/10/24/3385540.html 简单的将分为三步: (1)安装a ...
- 策略路由——使用Router-Policy策略路由进行路由协议的引入
1.实验目的:实现R3-R2-R1为访问主线路,R3-R4-R1为访问备份线路 2.实验拓扑及IP,如图; 3.基本配置(端口IP) R1: <Huawei>sys[Huawei]sys ...
- gitbook热更新时报错operation not permitted
在使用gitbook写东西的时候,当文档内容有更新的时候,会自动更新内容到页面上,方便预览.但是,存在一个bug,就是会神奇的崩溃掉,出现如下的错误提示: Restart after change i ...
- 关于Arrays类的静态方法asList()
Array.asList():是数组转成集合的方法 List<String> list = Arrays.asList(new String[]{"AA", " ...
- Eclipse简单介绍
1.编码设置:Windows>preference>Workspace>Other-UTF-8>apply and close: 2.字体大小设置:Windows>pre ...
- Linux mem 2.7 内存错误检测 (KASAN) 详解
文章目录 1. 简介 2. Shadow 区域初始化 3. 权限的判断 3.1 read/write 3.2 memxxx() 4. 权限的设置 4.1 buddy 4.1.1 kasan_free_ ...
- 通过t-sql定期自动备份SQL Server 上的所有数据库
项目背景 解决方案 方案一,是采用SQL的定时备份,建立作业来操作,这里有完整的使用手册: 方案二:基于t-sql方法进行查询备份 方案思路: 1.1 在 Master 数据库上创建一个备份所有数据库 ...
- php 变量和数据类型
$ 定义变量: 变量来源数学是计算机语言中能存储计算结果或能表示值抽象概念.变量可以通过变量名访问.在指令式语言中,变量通常是可变的. php 中不需要任何关键字定义变量(赋值,跟Java不同,Jav ...
- Linux下Zabbix5.0 LTS添加MySQL监控,实现邮件报警并执行预处理操作
依据前文:Linux下Zabbix5.0 LTS监控基础原理及安装部署(图文教程) 环境,继续添加MySQL应用集. 第一部分:添加Zabbix自带的MySQL应用集. 在ZabbixClient-0 ...
- 【JVM】JVM 概述、内存结构、溢出、调优(基础结构+StringTable+Unsafe+ByteBuffer)
什么是 JVM ? 定义 Java Virtual Machine - java 程序的运行环境(java 二进制字节码的运行环境) 好处 一次编写,到处运行 自动内存管理,垃圾回收功能 数组下标越界 ...