关于select Count()的使用和性能问题
比如Count(*) FROM E_Table WHERE [date] > '2008-1-1' AND istrue = 0
由于操作的数据比较大(400万以上),所以使用了两个数据库,一个用于更新,执行频繁的Insert、Update操作,把索引建在了主键id上,另一个数据库定时复制前一个数据库的数据,用于检索查询,在[date]字段上建立了聚簇索引,在[istrue]字段上建立了非聚簇索引。这样下来,每次Count花费不超过2s的时间。
后来又复制了一份数据库,做了一些字段的调整,其中istrue字段被删除,非聚簇索引也去除了,而[date]字段和聚簇索引没有变动。
结果在执行Count(*) FROM E_Table WHERE [date] > '2008-1-1'的时候,却出现了奇怪的现象,原本以为会更快完成的检索(因为表的条数有减少),反而花费了30+s。
反复检查两个表,没有发现除了非聚簇索引外的不同,又测试在前一个表上执行相同的Count(*) FROM E_Table WHERE [date] > '2008-1-1',花费时间在1s左右。
只好把非聚簇索引和istrue字段加上,结果检索速度立刻回到1s!
一个在检索条件中不出现的字段为什么会影响检索的效率呢?仔细对比两次的Excuting Plan,终于发现了问题所在:
花费30s的检索第一步:
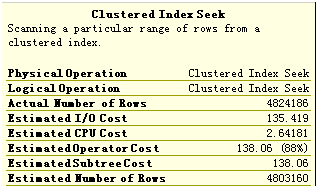
花费1s的检索第一步:

除了两者的操作不同(一般情况下,Clustered Index Seek的速度应该快于Index Scan),CPU Cost是近似的,Number of Rows是一样的,最大的差别在I/O Cost上,前者是后者的5倍!
究其原因,主要是因为SQL Server执行Count操作的策略。当建有索引时,而且Count的参数是*或者Not Null类型的字段时,SQL Server会对所有索引列中体积最小的索引进行Scan。而istrue字段是bit类型的,只占1个字节,[date]字段是smalldatetime类型的,占4个字节。检索前者的I/O自然远远小于检索后者的,在同样的内存条件下,通过前者检索花费的时间也要远小于后者。
当然,如果Count的参数是某个Null类型的字段,SQL Server则只能对该字段进行Scan,因为这时该字段为Null的记录不记录的。所以,一个优化建议是,尽量少用Null类型字段,使用默认值+bit类型的索引字段会提高Count检索的效率。
另外:关于where条件
COUNT时的WHERE
简单说下,就是COUNT的时候,如果没有WHERE限制的话,MySQL直接返回保存有总的行数
而在有WHERE限制的情况下,总是需要对MySQL进行全表遍历。
优化总结:
1.任何情况下SELECT COUNT(*) FROM tablename是最优选择;
2.尽量减少SELECT COUNT(*) FROM tablename WHERE COL = ‘value’ 这种查询;
3.杜绝SELECT COUNT(COL) FROM tablename WHERE COL2 = ‘value’ 的出现。
关于select Count()的使用和性能问题的更多相关文章
- 通过非聚集索引让select count(*) from 的查询速度提高几十倍、甚至千倍
通过非聚集索引,可以显著提升count(*)查询的性能. 有的人可能会说,这个count(*)能用上索引吗,这个count(*)应该是通过表扫描来一个一个的统计,索引有用吗? 不错,一般的查询,如果用 ...
- SQLSERVER 里SELECT COUNT(1) 和SELECT COUNT(*)哪个性能好?
SQLSERVER 里SELECT COUNT(1) 和SELECT COUNT(*)哪个性能好? 今天遇到某人在我以前写的一篇文章里问到 如果统计信息没来得及更新的话,那岂不是统计出来的数据时错误的 ...
- select count(*)和select count(1)哪个性能高
select count(*).count(数字).count(字段名)在相同的条件下是没有性能差别的,一般我们在统计行数的时候都会把NULL值统计在内的,所以这样的话,最好就是使用COUNT(*) ...
- SQL Select count(*)和Count(1)的区别和执行方式及SQL性能优化
SQL性能优化:http://www.cnblogs.com/CareySon/category/360333.html Select count(*)和Count(1)的区别和执行方式 在SQL S ...
- MYSQL性能调优与架构设计之select count(*)的思考
select count(*)的思考 原文:MYSQL性能调优与架构设计 举例: 这里我们就拿一个看上去很简单的功能来分析一下. 需求:一个论坛帖子总量的统计 附加要求:实时更新 在很多人看来,这 ...
- 转】MYSQL性能调优与架构设计之select count(*)的思考
原博文出自于: http://blog.fens.me/category/%E6%95%B0%E6%8D%AE%E5%BA%93/page/5/ 感谢! Posted: Feb 7, 2013 Tag ...
- Select count(*)和Count(1)的区别和执行方式
在SQL Server中Count(*)或者Count(1)或者Count([列])或许是最常用的聚合函数.很多人其实对这三者之间是区分不清的.本文会阐述这三者的作用,关系以及背后的原理. ...
- select count(*)和select count(1)的区别 (转)
A 一般情况下,Select Count (*)和Select Count(1)两着返回结果是一样的 假如表沒有主键(Primary key), 那么count(1)比count(*)快, 如果有主键 ...
- select count(*) 底层究竟做了什么?
阅读本文大概需要 6.6 分钟. SELECT COUNT( * ) FROM t是个再常见不过的 SQL 需求了.在 MySQL 的使用规范中,我们一般使用事务引擎 InnoDB 作为(一般业务)表 ...
随机推荐
- coding 绑定腾讯云开放平台注意事项
coding升级后需要绑定腾讯云开放平台,按照coding文档的提示操作就好 1.创建腾讯云平台后,不要自定义邮箱和用户名 2.直接绑定原来我们使用的coding账号即可 绑定成功后,邮箱和用户名会自 ...
- qt的webkit
qt4里面,在pro文件添加 QT += webkit qt5里面,在pro文件添加 QT += webkit webkitwidgets 备注: webkit不支持静态编译
- HDOJ5521(巧妙构建完全图)
Meeting Time Limit: 12000/6000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total ...
- python查找字符串 函数find() 用法
sStr1 = 'abcdefg' sStr2 = 'cde' print sStr1.find(sStr2) 输出 2意思是在sStr1字符里的第2位置找到了包含cde字符的字段
- 在Eclipse中使用Maven部署项目的Tomcat
方式一:打war包到tomcat/webapps目录 点击在项目上面 -> 右键 -> Run As -> Maven install 之后查看Maven输出路径: D:\apach ...
- python学习 (二十九) range函数
1:list函数可以将其他类型转成list. print(list(range(0, 10))) 2: list函数把元组转成list t = (1, 3, 3, 5) print(list(t)) ...
- canvas之绘制一张图片
<canvas id="canvas" width="600" height="500" style="background ...
- ceph journal更换位置
只在这里做简单的演示 ceotos7 环境 3个mon节点 3个osd节点 环境搭建我这里不再叙述 我们查看一下分区情况: [root@ceph_1 ~]# lsblkNAME MAJ: ...
- Ubuntu无法获得锁 /var/lib/dpkg/lock - open (11: 资源暂时不可用)
结果终端提示:无法获得锁 /var/lib/dpkg/lock - open (11: 资源暂时不可用) E: 无法锁定管理目录(/var/lib/dpkg/),是否有其他进程正占用它?” 解决办法如 ...
- 读《分布式一致性原理》JAVA客户端API操作2
创建节点 通过客户端API来创建一个数据节点,有一下两个接口: public String create(final String path, byte data[], List<ACL> ...