mapreduce实验
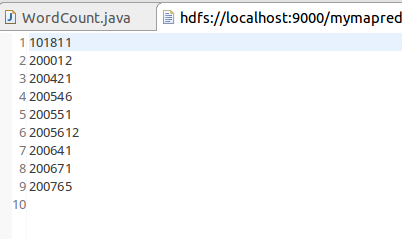
代码:
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path("hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1");
Path out = new Path("hdfs://localhost:9000/mymapreduce1/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class doMapper extends Mapper<Object, Text, Text, IntWritable>{
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString(), " ");
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
}
mapreduce实验的更多相关文章
- 实验六 MapReduce实验:二次排序
实验指导: 6.1 实验目的基于MapReduce思想,编写SecondarySort程序. 6.2 实验要求要能理解MapReduce编程思想,会编写MapReduce版本二次排序程序,然后将其执行 ...
- Mapreduce实验一:WordCountTest
1.确定Hadoop处于启动状态 [root@neusoft-master ~]# jps 23763 Jps3220 SecondaryNameNode3374 ResourceManager293 ...
- Mit6.824 Lab1-MapReduce
前言 Mit6.824 是我在学习一些分布式系统方面的知识的时候偶然看到的,然后就开始尝试跟课.不得不说,国外的课程难度是真的大,一周的时间居然要学一门 Go 语言,然后还要读论文,进而做MapRed ...
- 实验6:Mapreduce实例——WordCount
实验目的1.准确理解Mapreduce的设计原理2.熟练掌握WordCount程序代码编写3.学会自己编写WordCount程序进行词频统计实验原理MapReduce采用的是“分而治之”的 ...
- 大型数据库技术实验六 实验6:Mapreduce实例——WordCount
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1. buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t ...
- Hadoop大实验——MapReduce的操作
日期:2019.10.30 博客期:114 星期三 实验6:Mapreduce实例——WordCount 实验说明: 1. 本次实验是第六次上机,属于验证性实验.实验报告上交截止 ...
- 云计算——实验一 HDFS与MAPREDUCE操作
1.虚拟机集群搭建部署hadoop 利用VMware.centOS-7.Xshell(secureCrt)等软件搭建集群部署hadoop 远程连接工具使用Xshell: HDFS文件操作 2.1 HD ...
- mapreduce课上实验
今天我们课上做了一个关于数据清洗的实验,具体实验内容如下: 1.数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中: 2.数据处理: ·统计最受欢迎的视频/文章的Top10访问次数 (v ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
随机推荐
- hover()函数的用法
定义和用法 hover() 方法规定当鼠标指针悬停在被选元素上时要运行的两个函数. 实例 当鼠标指针悬停在上面时,改变 <p> 元素的背景颜色: $("p").hove ...
- Ubuntu中可以卸载的软件(持续更新)
sudo apt-get -y --auto-remove purge unity unity-2d* sudo apt-get -y purge empathy sudo apt-get -y pu ...
- null,blank,default
null 是针对数据库而言,如果 null=True, 表示数据库的该字段可以为空. blank 是针对表单的,如果 blank=True,表示你的表单填写该字段的时候可以不填,比如 admin 界面 ...
- spring-boot整合mybaits多数据源动态切换案例
1.运行环境 开发工具:intellij idea JDK版本:1.8 项目管理工具:Maven 4.0.0 2.GITHUB地址 https://github.com/nbfujx/springBo ...
- sql server 2000安装程序配置服务器失败
第一种方法 今天安装SQL Server 2000遇到了个很BT的问题,提示出下: 安装程序配置服务器失败.参考服务器错误日志和C:\Windows\sqlstp.log了解更多信息. 以前进安装目录 ...
- BZOJ 4710: [Jsoi2011]分特产(容斥)
传送门 解题思路 首先所有物品是一定要用完的,那么可以按照物品考虑,就是把每种物品分给\(n\)个人,每个人分得非负整数,可以用隔板法计算.设物品有\(m\)个,方案数为\(C(n+m-1,n-1)\ ...
- 5 August
P1016 旅行家的预算 单调队列. 再看看单调队列怎么用的. #include <cstdio> int n, l, r; double D, dd, d[9], C, p[9], an ...
- Borůvka (Sollin) 算法求 MST 最小生成树
基本思路: 用定点数组记录每个子树的最近邻居. 对于每一条边进行处理: 如果这条边连成的两个顶点同属于一个集合,则不处理,否则检测这条边连接的两个子树,如果是连接这两个子树的最小边,则更新 (合并). ...
- spring boot 修改banner
在resources目录下新建一个banner.txt,里面添加要显示的内容,如: ////////////////////////////////////////////////////////// ...
- mybatis如何通过接口查找对应的mapper.xml及方法执行详解
转:http://www.jb51.net/article/116402.htm 本文主要介绍的是关于mybatis通过接口查找对应mapper.xml及方法执行的相关内容,下面话不多说,来看看详细的 ...