大数据笔记(十六)——Hive的客户端及自定义函数
一.Hive的Java客户端
JDBC工具类:JDBCUtils.java
package demo.jdbc; import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement; //工具类:(1)获取数据库的链接 (2)释放数据库资源
public class JDBCUtils { //Hive驱动
private static String driver = "org.apache.hive.jdbc.HiveDriver"; //Hive的位置
private static String url = "jdbc:hive2://192.168.153.11:10000/default"; //注册数据库的驱动:Java的反射
static{
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
throw new ExceptionInInitializerError(e);
}
} //获取数据库链接
public static java.sql.Connection getConnection(){
try {
return DriverManager.getConnection(url);
} catch (SQLException e) {
e.printStackTrace();
}
return null;
} //释放资源
public static void release(java.sql.Connection conn,Statement st,ResultSet rs){
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}finally{
rs = null;
}
} if(st != null){
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}finally{
st = null;
}
} if(conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}finally{
conn = null;
}
}
}
}
DemoTest.java
package demo.jdbc; import java.sql.ResultSet;
import java.sql.Statement; public class DemoTest { public static void main(String[] args) {
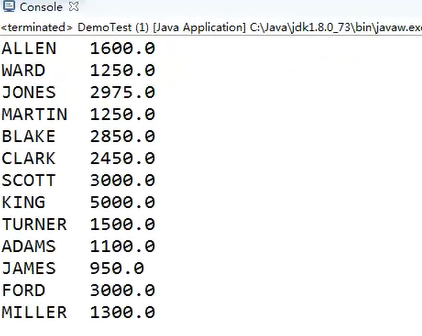
String sql = "select * from emp1"; java.sql.Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnection();
//得到SQL的运行环境
st = conn.createStatement();
//ִ执行SQL
rs = st.executeQuery(sql); while (rs.next()) {
//姓名 薪水
String name = rs.getString("ename");
double sal = rs.getDouble("sal");
System.out.println(name + "\t" +sal);
}
}catch(Exception e){
e.printStackTrace();
}finally {
JDBCUtils.release(conn, st, rs);
}
}
}
启动HiveServer:hiveserver2,会报错:
java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException:User:
root is not allowed to impersonate anonymous
在老版本的Hive中,是没有这个问题的
解决:
把Hadoop HDFS的访问用户(代理用户) ---> *
core-site.xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property> <property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
二.Hive的自定义函数
例子:
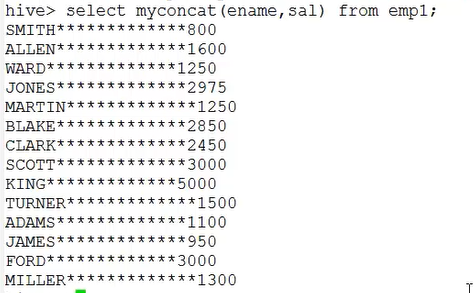
1.concat 拼加两个字符串
package udf; import org.apache.hadoop.hive.ql.exec.UDF; /**
* 实现关系型数据库中的concat函数:拼加字符串
* 需要继承的类:UDF
*
*/
public class MyConcatString extends UDF{ //必须重写一个方法,方法名叫: evaluate
public String evaluate(String a,String b){
return a + "*************"+b;
}
}
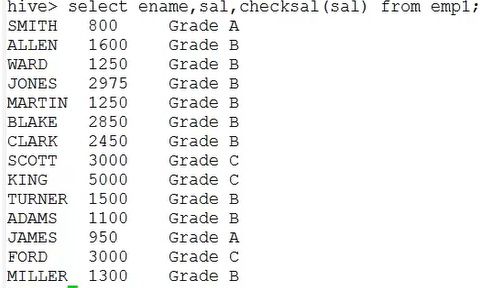
2.判断员工工资的级别
package udf; import org.apache.hadoop.hive.ql.exec.UDF; /**
* 根据员工薪水判断级别
*
*/
public class CheckSalaryGrade extends UDF{
public String evaluate(String salary){
int sal = Integer.parseInt(salary); if (sal<1000) {
return "Grade A";
}else if (sal>=1000 && sal<3000) {
return "Grade B";
}else {
return "Grade C";
}
}
}
3、打包
将jar包加入hive的classpath
在hive命令行执行:add jar /root/temp/myudf.jar;
创建别名(函数名称)
create temporary function myconcat as 'demo.udf.MyConcatString';
create temporary function checksal as 'demo.udf.CheckSalaryGrade';

结果:
大数据笔记(十六)——Hive的客户端及自定义函数的更多相关文章
- 大数据笔记(六)——HDFS的底层原理:JAVA动态代理和RPC
一.Java的动态代理对象 实现代码如下: 1.接口类MyService package hdfs.proxy; public interface MyService { public void me ...
- 大数据工具篇之Hive与MySQL整合完整教程
大数据工具篇之Hive与MySQL整合完整教程 一.引言 Hive元数据存储可以放到RDBMS数据库中,本文以Hive与MySQL数据库的整合为目标,详细说明Hive与MySQL的整合方法. 二.安装 ...
- 跟上节奏 大数据时代十大必备IT技能
跟上节奏 大数据时代十大必备IT技能 新的想法诞生新的技术,从而造出许多新词,云计算.大数据.BYOD.社交媒体……在互联网时代,各种新词层出不穷,让人应接不暇.这些新的技术,这些新兴应用和对应的IT ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
- 大数据应用之Windows平台Hbase客户端Eclipse开发环境搭建
大数据应用之Windows平台Hbase客户端Eclipse开发环境搭建 大数据应用之Windows平台Hbase客户端Eclipse环境搭建-Java版 作者:张子良 版权所有,转载请注明出处 引子 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- CentOS6安装各种大数据软件 第六章:HBase分布式集群的配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- python3.4学习笔记(十六) windows下面安装easy_install和pip教程
python3.4学习笔记(十六) windows下面安装easy_install和pip教程 easy_install和pip都是用来下载安装Python一个公共资源库PyPI的相关资源包的 首先安 ...
随机推荐
- [转帖]NetSuite 进入中国市场满一年,甲骨文公布首份成绩单
NetSuite 进入中国市场满一年,甲骨文公布首份成绩单 https://baijiahao.baidu.com/s?id=1617073148682281883&wfr=spider&am ...
- xss过滤与单例模式(对象的实例永远用一个)
kindeditor里面可以加入script代码,使用re可以过滤掉python有个专门的模块可以处理这种情况,beautifulsoup4 调用代码: content = XSSFilter().p ...
- QRCode.js一个生成二维码的javascript库
前言 最近在开发中遇到一个需求:将后端返回的链接转换成二维码,那么如何来实现呢?我们可以使用QRCode.js来解决这一问题 什么是 QRCode.js? QRCode.js 是一个用于生成二维码的 ...
- Java中静态变量和实例变量的区别
静态变量属于类的级别,而实例变量属于对象的级别. 主要区别有两点: 1,存放位置不同 类变量随着类的加载存在于方法区中,实例变量随着对象的对象的建立存在于堆内存中. 2,生命周期不同 类变量的生命周期 ...
- Window Operations详解
window(windowLength, slideInterval):返回窗口长度为windowLength,每隔slideInterval滑动一次的window DStream countByWi ...
- 1-ES简单介绍
一.ES简单介绍 ES:Elastic Search,一个分布式.高扩展.高实时的搜索与数据分析引警.它可以准实时地快速存储.搜索.分析海量的数据. 1.ES实现原理 a.用户数据提交到ES数据库中 ...
- 原生js实现深度克隆
总体思路: 判断对象当中的值为引用值还是原始值 如果是引用值,判断是数组还是对象,如果是原始值直接copy 递归 注意:不要忘了排除null,因为typeof null = 'object' func ...
- mybatis报错(三)报错Result Maps collection does not contain value for java.lang.Integer解决方法
转自:https://blog.csdn.net/zengdeqing2012/article/details/50978682 1 [WARN ] 2016-03-25 13:03:23,955 - ...
- SpringMVC拦截器(资源和权限管理)
转自:https://www.cnblogs.com/downey/p/4928951.html 1.DispatcherServlet SpringMVC具有统一的入口DispatcherServl ...
- rest_framework框架的分页
class MyPageNumberPagination(PageNumberPagination): page_size = 1 page_query_param = 'page' page_siz ...