2019-07-31【机器学习】无监督学习之降维NMF算法 (人脸特征提取)
代码
from numpy.random import RandomState #加载RandomState用于创建随机种子
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_olivetti_faces
from sklearn import decomposition n_row, n_col = 2, 3 #设置图像展示时的排列情况
n_components = n_row * n_col #
image_shape = (64, 64) #设置人脸数据图片的大小 dataset = fetch_olivetti_faces(shuffle=True, random_state=RandomState(0)) #array 二维
#print(dataset)
faces = dataset.data #array 一维
#print(faces) def plot_gallery(title, images, n_col=n_col, n_row=n_row):
plt.figure(figsize=(2. * n_col, 2.26 * n_row)) #指定图片大小
plt.suptitle(title, size=16) #设置标题和字号大小 for i, comp in enumerate(images):
plt.subplot(n_row, n_col, i + 1)#选择画制的子图
vmax = max(comp.max(), -comp.min()) plt.imshow(comp.reshape(image_shape), cmap=plt.cm.gray,
interpolation='nearest', vmin=-vmax, vmax=vmax)#对数值归一化,并以灰度图形显示
plt.xticks(())
plt.yticks(())#去除子图坐标轴标签
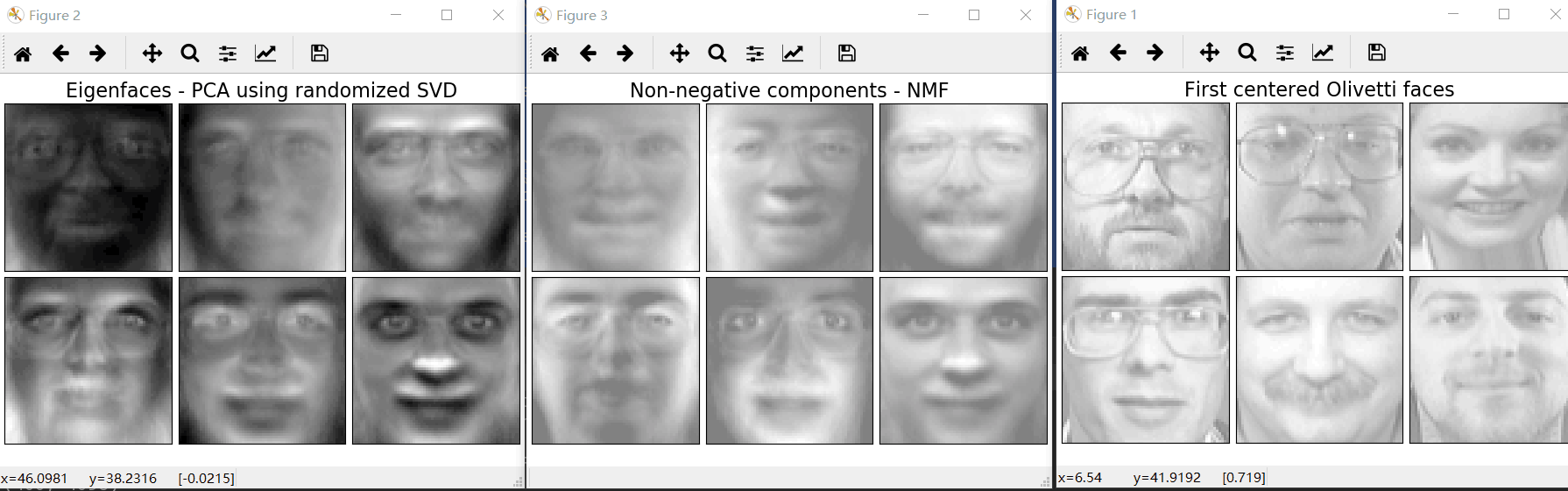
plt.subplots_adjust(0.01, 0.05, 0.99, 0.93, 00.04, 0.) #设置子图位置和间隔调整 plot_gallery("First centered Olivetti faces", faces[:n_components]) estimators = [
('Eigenfaces - PCA using randomized SVD',
decomposition.PCA(n_components=6, whiten=True)),
('Non-negative components - NMF',
decomposition.NMF(n_components=6, init='nndsvda', tol=5e-3))
] for name, estimator in estimators:
#print(estimator)
print("Extracting the top %d %s..."% (n_components, name))
print(faces.shape) #输出图片大小 400,4096
estimator.fit(faces) #调用算法提取特征
components_ = estimator.components_ #获取提取的特征,一个二维列表
#print(components_)
plot_gallery(name, components_[:n_components]) #按照固定格式进行排列 plt.show()
效果图:
2019-07-31【机器学习】无监督学习之降维NMF算法 (人脸特征提取)的更多相关文章
- 2019-07-31【机器学习】无监督学习之降维PCA算法实例 (鸢尾花)
样本 代码: import matplotlib.pyplot as plt from sklearn.decomposition import PCA from sklearn.datasets i ...
- agentzh 的 Nginx 教程(版本 2019.07.31)
agentzh 的 Nginx 教程(版本 2019.07.31) agentzh 的 Nginx 教程(版本 2019.07.31) https://openresty.org/download/a ...
- <机器学习>无监督学习算法总结
本文仅对常见的无监督学习算法进行了简单讲述,其他的如自动编码器,受限玻尔兹曼机用于无监督学习,神经网络用于无监督学习等未包括.同时虽然整体上分为了聚类和降维两大类,但实际上这两类并非完全正交,很多地方 ...
- 无监督学习——K-均值聚类算法对未标注数据分组
无监督学习 和监督学习不同的是,在无监督学习中数据并没有标签(分类).无监督学习需要通过算法找到这些数据内在的规律,将他们分类.(如下图中的数据,并没有标签,大概可以看出数据集可以分为三类,它就是一个 ...
- 2019-07-25【机器学习】无监督学习之聚类 K-Means算法实例 (1999年中国居民消费城市分类)
样本 北京,2959.19,730.79,749.41,513.34,467.87,1141.82,478.42,457.64天津,2459.77,495.47,697.33,302.87,284.1 ...
- 2019-07-31【机器学习】无监督学习之聚类 K-Means算法实例 (图像分割)
样本: 代码: import numpy as np import PIL.Image as image from sklearn.cluster import KMeans def loadData ...
- 斯坦福机器学习视频笔记 Week8 无监督学习:聚类与数据降维 Clusting & Dimensionality Reduction
监督学习算法需要标记的样本(x,y),但是无监督学习算法只需要input(x). 您将了解聚类 - 用于市场分割,文本摘要,以及许多其他应用程序. Principal Components Analy ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
- Python 机器学习实战 —— 无监督学习(下)
前言 在上篇< Python 机器学习实战 -- 无监督学习(上)>介绍了数据集变换中最常见的 PCA 主成分分析.NMF 非负矩阵分解等无监督模型,举例说明使用使用非监督模型对多维度特征 ...
随机推荐
- Caused by: java.lang.IllegalArgumentException
Caused by: java.lang.IllegalArgumentException 是因为jdk较高而项目需要的是低版本的问题 1.将idea或idea里的语言级别调到适合自己项目的版本比如安 ...
- 洛谷P1957口算练习题题解
前言: 题目传送门:https://www.luogu.com.cn/problem/P1957 其实这很简单 纯模拟撒~~~~ 正文开始: _话说 ,就当本蒟蒻正高高兴兴的刷水题时,居然 碰到了这个 ...
- 安装arcgis server时提示“应用程序无法启动,因为应用程序......或使用命令行sxstrace.exe”
说一下这个原因:有几个条件不满足会产生这样的问题: 1.软件的发布是不需要安装的,直接在vs里编译好release版就发布了,而发布的时候如果缺少一些库文件,就会产生这样的问题. 一版都是目 ...
- 商品spu 和 sku的关系
总结一下在目前的电商系统中的商品涉及的属性spu,sku.搞清楚两者之间的关系对表的设计非常重要 spu Standard Product Unit (标准产品单位) ,一组具有共同属性的商品集 SK ...
- scrapy Selector用法及xpath语法
准备工作 html示例: <?xml version="1.0" encoding="UTF-8"?> <html <head> ...
- IBN-Net: 提升模型的域自适应性
本文解读内容是IBN-Net, 笔者最初是在很多行人重识别的库中频繁遇到比如ResNet-ibn这样的模型,所以产生了阅读并研究这篇文章的兴趣,文章全称是: <Two at Once: Enha ...
- 1+X Web前端开发(中级)理论考试样题(附答案)
传送门 教育部:职业教育将启动"1+X"证书制度改革 职业教育改革1+X证书制度试点启动 1+X成绩/证书查询入口 一.单选题(每小题2分,共30小题,共 60 分) 1.在Boo ...
- SWUST OJ 1075 求最小生成树(Prim算法)
求最小生成树(Prim算法) 我对提示代码做了简要分析,提示代码大致写了以下几个内容 给了几个基础的工具,邻接表记录图的一个的结构体,记录Prim算法中最近的边的结构体,记录目标边的结构体(始末点,值 ...
- css3之 景深
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- PTA | 1019 数字黑洞 (20分)
给定任一个各位数字不完全相同的 4 位正整数,如果我们先把 4 个数字按非递增排序,再按非递减排序,然后用第 1 个数字减第 2 个数字,将得到一个新的数字.一直重复这样做,我们很快会停在有" ...