文献阅读报告 - Social Ways: Learning Multi-Modal Distributions of Pedestrian Trajectories with GANs
文献引用
Amirian J, Hayet J B, Pettre J. Social Ways: Learning Multi-Modal Distributions of Pedestrian Trajectories with GANs[J]. 2019.
文章是继Social LSTM、Social GAN模型后的进一步提升,在理想的监控俯瞰数据库ETH、UCY上进行数据的预测。重点贡献有:
- 引入了注意力机制使模型自主分配对交互信息的关注。
- 舍弃了L2代价函数,引入基于互信息的Information Loss,增强了模型对多合理轨迹的预测能力。
- 提供了一种能够验证各模型的多轨迹预测能力的小型合成场景和轨迹生成效果的判断指标。
模型框架
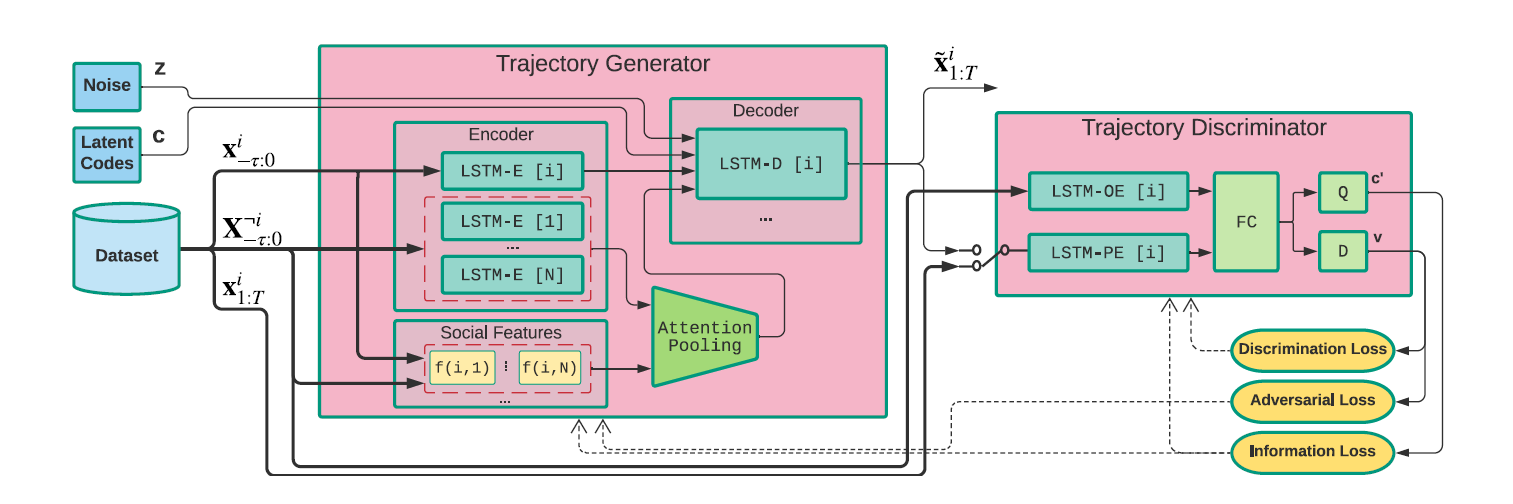
如上图所示,文章的基本框架是GAN网络,在不考虑batch批处理的情况下,模型逐一为每个行人预测轨迹。
- 在Generator中,对于待预测行人\(i\),首先会将所有行人的已知轨迹进行编码,而后基于\(i\)和其他行人之间的地理和运动信息,引入注意力机制使得模型对其他行人的交互信息自主适应。行人\(i\)的轨迹编码、注意力池化后的交互信息、噪音、latent code(新引入内容,之后会讲到)四种输入作为Decoder的输入,解码出行人\(i\)的预测轨迹。
- 在Discriminator中,会对生成轨迹/真实轨迹进行判别,判别的结果作为Generator/Discriminator的代价函数。
- 模型框架具体来说是InfoGAN,InfoGAN网络解决的是在无监督的情况下通过修改latent code倾向从而控制GAN的生成分布,与GAN相比其强调latent code对生成的控制性,与cGAN相比其强调能够在有潜在类别的数据中无监督(无数据标签)学习。因而GAN网络中新引入了Latent Code和Information Loss两个结构。
HighLight 1 - 注意力机制
注意力机制采用Key-Value-Query型定义,从认知角度引入合适的手工指标,基于这些指标使模型能够对周围轨迹产生不同的注意力。
- Key = Value = \(H_t\)(除目标行人\(i\)外,其他的行人的轨迹编码信息)。
- Query:\(f^{ij}\)由三种运动地理运动信息合成
- \(i\)和\(j\)之间的欧式距离
- \(i\)和\(j\)之间运动方向的夹角。
- 以当前运动姿态,\(i\)和\(j\)未来将会出现的最短距离。
\[\sigma (f^{ik},h^k)={{N-1}\over \sqrt d_{\sigma}}<f^{ik},W_\sigma h^k>\]
\[\alpha^{i,j}={exp(\sigma(f^{ij},h^j)) \over \sum_{k \neq i} exp(\sigma(f^{ik},h^k))}\]
HighLight 2 - InfoGAN
原文[推荐阅读] Chen X, Duan Y, Houthooft R, et al. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets[J]. 2016.
InfoGAN模型解读:https://www.jiqizhixin.com/articles/2018-10-29-21,内容过简练,建议阅读原文。
模型结构
InfoGAN的模型结构相较于GAN的改进是较小的,在上文的模型中,首先是在输入中新增了Latent Code,而后弃用了SGAN中的L2损失函数,在Discriminator在加入了一个子网络\(Q\)产生Information Loss。
原理简介
Motivation: InfoGAN训练后的理想状态是通过调整Latent Code(潜码)——\(c\)输入控制生成的分布。然而GAN自由灵活性很高,网络很容易直接忽视Latent Code的存在,因此必须调整代价函数使网络重视Latent Code的存在。InfoGAN提出使用互信息\(I\)作为优化目标,\(I\)越大则潜码和生成的关系越大:
\[I(X;Y) = H(X) - H(X|Y)\]
对于互信息\(I(X;Y)\),其本意是指在已知\(Y\)的情况下,\(X\)的不确定性下降程度,当两者结合得非常紧密时,互信息将变得非常大。因此我们希望\(I(c;G(z,c))\)能够尽可能大,这样潜码就能控制Generator的生成了。
Restriction:
\(H(c)\)是信息熵的计算,文章中在此假定\(H(c)\)是一个固定的值,因此优化目标转化为令\(H(c|x)\)最大化。
知识补充:
- 信息熵的计算公式:\(H(X) = E[I(x_i)] = - \sum_{i=1}^NP(x_i)logP(x_i)\)
- 具体计算:\(H(c|x)=-E_{x \sim G(z,c)}[E_{c'\sim P(c|x)}[logP(c'|x)]]\)
需要后验概率\(P(c|x)\),要获取其非常困难,因此使用\(Q(c|x)\)(辅助分布)来近似求解后验的概率\(P(c|x)\),并且作者通过数学推导了在互信息的计算中\(P(c|x)\)和\(Q(c|x)\)间的关系:

[!] 这里请务必留意将“=“变为”>=“时移除的部分是P和Q的KL散度,KL散度是用于衡量P和Q之间分布差异性的指标。这将为后文解释优化的合理性提供重要支撑。
我们继续与\(P(c|x)\)的斗争,之前我们求出了\(I(c;G(z,c))\)的下界:
\[E_{x\sim G(z,c)}[E_{c'\sim P(c|x)}[logQ(c'|x)]] + H(c)\]
下界中相较原式\(E[.]\)中的\(P(c|x)\)被替代了,但是求期望的随机变量\(c'\)的分布中依然涉及\(P(c'|x)\),要进一步替换,作者用了如下公式:
\[E_{x\sim X,y\sim Y | x}[f(x,y)] = E_{x\sim X, y\sim Y|x,x'\sim X|y}[f(x',y)]\]
至此,\(P(c|x)\)被彻底干掉了,从而变得可以被实现:
\[E_{x\sim G(z,c)}[E_{c'\sim P(c|x)}[logQ(c'|x)]] + H(c) = E_{c \sim P(c),x \sim G(z,c)}[logQ(c|x)] + H(c)\]
Target:作者将最大化\(I(c;G(z,c))\)的目标转移为最大化\(I\)的下界
\[L_1(G,Q)=E_{c \sim P(c),x \sim G(z,c)}[logQ(c|x)] + H(c)\]
[敲黑板]!!!
为什么最大化互信息可以变为最大化互信息的下界呢?这就是InfoGAN最精华、最巧妙的地方!
我们从训练调整参数的角度来看这个问题,InfoGAN网络的参数可分为Generator、Discriminator和Q三个部分,训练时(Generator)(Discriminator+Q)迭代训练,由于Discriminator与互信息无关,我们先不考虑,因此G和Q实际在两个迭代中完成:
- 训练Q时:G的参数固定,因此互信息\(I\)是不变的,这时候训练Q就是为了减小互信息下界和互信息的差异。而我们前文重点说道,差异恰好就是P和Q的KL散度,即分布差异,实现了调整Q的参数拟合P的过程。
- 训练G时:在Q不断拟合P的过程中,互信息\(I\)的下界也越来越接近互信息\(I\)(直至等于)。在这种条件下,训练G增大互信息的下界等同于增大互信息。
一句话来说,G和Q在计算互信息时有着不同的目标(提升互信息\增强拟合),但是却都通过最大化L1(G,Q)损失函数实现了。(在原文中,作者也提到了这种方式类似于"Wake-Sleep Algorithm" - 同样的训练目标,最终两个权重都正确更新了)
Implement:
最终加入了GAN原有的损失函数后,总优化目标变化为:
\[min_{G,Q}max_DV_1(D,G)=V(D,G) - \mu L_1(G,Q)\]
Q是含有待定参数的分布器。
- 在InfoGAN实现时,Q实际输出的是假设的正则分布的参数,并随着Discriminator进行训练,负似然对数作为损失函数。
- 在Social Ways模型在实现时,Q实际上是一个latent code reconstructor(潜码恢复器)。Information Loss实指Q所恢复的潜码\(\hat c\)和真实潜码\(c\)之间的MSE。
HighLight 3 - 多轨迹预测的生成场景
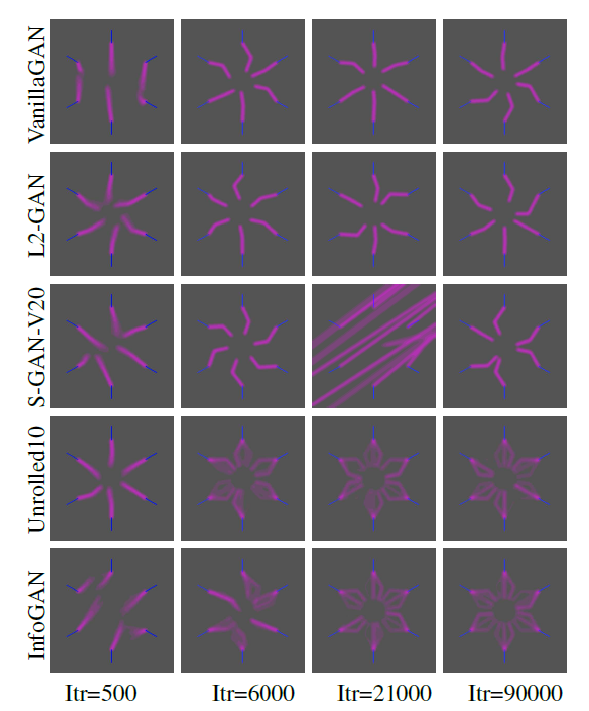
GAN模型引入轨迹预测的重要目的就是有助于生成多条轨迹(分布),文章为探究不同类GAN模型对多轨迹的预测能力,特地人工生成了一个测试场景(如下图):
- 蓝色为已知轨迹,红色为待预测轨迹。
- 从六个方向上产生轨迹,并在每个方向轨迹上又产生三个具体的分支。

不同的baseline模型在不同的迭代周期产生的预测结果如下图所示,从而验证了InfoGAN对多合理轨迹预测的有效性,其能够在更短的迭代周期中识别出多种可能性的轨迹:
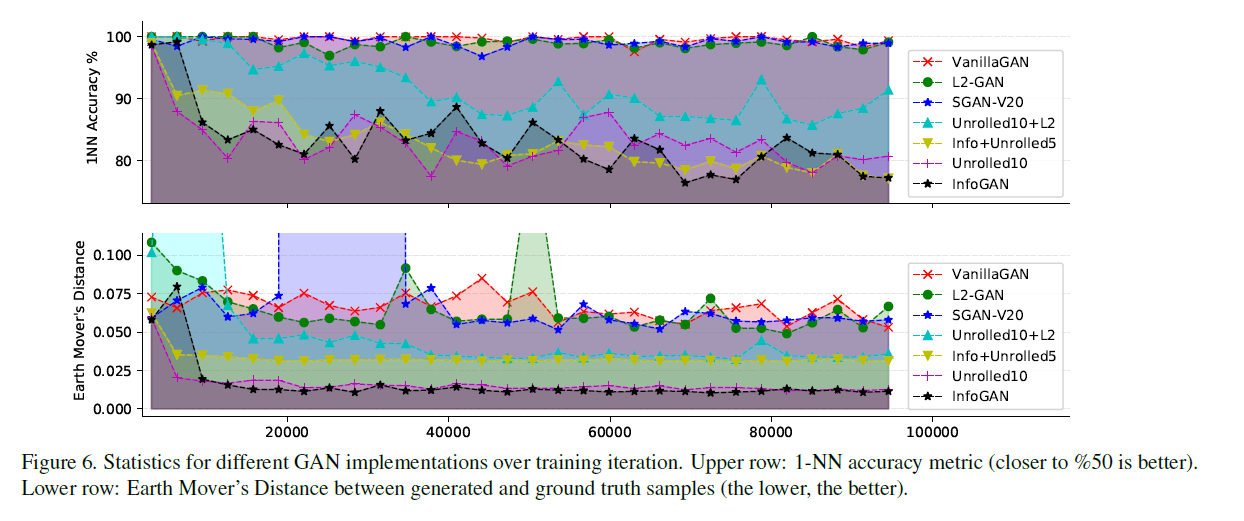
此外,文章还使用了1-Nearest Neighbor classifier和Earth Mover's Distance两种方法对真实未来轨迹和生成轨迹的质量进行评估:
- 对于1-Nearest Neighbor classifier,越接近50%越好。
- 对于EMD,越低越好。
文献阅读报告 - Social Ways: Learning Multi-Modal Distributions of Pedestrian Trajectories with GANs的更多相关文章
- 文献阅读报告 - Social BiGAT + Cycle GAN
原文文献 Social BiGAT : Kosaraju V, Sadeghian A, Martín-Martín R, et al. Social-BiGAT: Multimodal Trajec ...
- 文献阅读报告 - Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks
paper:Gupta A , Johnson J , Fei-Fei L , et al. Social GAN: Socially Acceptable Trajectories with Gen ...
- 文献阅读报告 - Social LSTM:Human Trajectory Prediction in Crowded Spaces
概览 简述 文献所提出的模型旨在解决交通中行人的轨迹预测(pedestrian trajectory prediction)问题,特别是在拥挤环境中--人与人交互(interaction)行为常有发生 ...
- 文献阅读报告 - Situation-Aware Pedestrian Trajectory Prediction with Spatio-Temporal Attention Model
目录 概览 描述:模型基于LSTM神经网络提出新型的Spatio-Temporal Graph(时空图),旨在实现在拥挤的环境下,通过将行人-行人,行人-静态物品两类交互纳入考虑,对行人的轨迹做出预测 ...
- 【文献阅读】Deep Residual Learning for Image Recognition--CVPR--2016
最近准备用Resnet来解决问题,于是重读Resnet的paper <Deep Residual Learning for Image Recognition>, 这是何恺明在2016-C ...
- 文献阅读报告 - 3DOF Pedestrian Trajectory Prediction
文献 Sun L , Yan Z , Mellado S M , et al. 3DOF Pedestrian Trajectory Prediction Learned from Long-Term ...
- 文献及代码阅读报告 - SS-LSTM:A Hierarchical LSTM Model for Pedestrian Trajectory Prediction
概览 简述 SS-LSTM全称Social-Scene-LSTM,是一种分层的LSTM模型,在已有的考虑相邻路人之间影响的Social-LSTM模型之上额外增加考虑了行人背景的因素.SS-LSTM架构 ...
- 文献阅读报告 - Move, Attend and Predict
Citation Al-Molegi A , Martínez-Ballesté, Antoni, Jabreel M . Move, Attend and Predict: An Attention ...
- 文献阅读报告 - Pedestrian Trajectory Prediction With Learning-based Approaches A Comparative Study
概述 本文献是一篇文献综述,以自动驾驶载具对外围物体行动轨迹的预测为切入点,介绍了基于运动学(kinematics-based)和基于机器学习(learning-based)的两大类预测方法. 并选择 ...
随机推荐
- 对Python中列表和数组的赋值,浅拷贝和深拷贝的实例讲解
引用:https://www.jb51.net/article/142775.htm 列表赋值: 1 2 3 4 5 6 7 >>> a = [1, 2, 3] >>&g ...
- 为U盘装备Ubuntu工作学习两不误
题记: 在上一篇文章中,我介绍了让Ubuntu 10.04完美支持Thinkpad小红点Trackpoint.看上去,显得有些不痛不痒,实际上有些同学会因为小红点中键不能正常使用,而放弃在Th ...
- Linux下,Tomcat启动成功,发现ip:8080访问失败
Linux下,Tomcat启动成功,发现ip:8080访问失败 Chasel_H 2018.04.23 20:47* 字数 195 阅读 566评论 0喜欢 3 相信很多人都和我一样,在Linux环境 ...
- 标准模板库中的优先队列(priority_queue)
//C++数据结构与算法(第4版) Adam Drozdek 著 徐丹 吴伟敏<<清华大学出版社>> #include<queue> priority_queu ...
- Day9 - A - Apple Catching POJ - 2385
Description 有两棵APP树,编号为1,2.每一秒,这两棵APP树中的其中一棵会掉一个APP.每一秒,你可以选择在当前APP树下接APP,或者迅速移动到另外一棵APP树下接APP(移动时间可 ...
- 「AT2292」Division into Two
传送门 Luogu 解题思路 考虑如何 \(\text{DP}\) 为了方便处理,我们设 \(A > B\) 设 \(dp[i]\) 表示处理完 \(1...i\) ,并且第 \(i\) 个数放 ...
- Windows编程常用api
转载网络 黑客常用WIN API函数整理 一.进程 创建进程: CreateProcess (,,,,,,,&si,&pi); WinExec("notepad", ...
- Codestorm:Counting Triangles 查各种三角形的个数
题目链接:https://www.hackerrank.com/contests/codestorm/challenges/ilia 这周六玩了一天的Codestorm,这个题目是真的很好玩,无奈只做 ...
- 安卓10GB内存旗舰手机的普及,能成为拯救DRAM厂商的救命稻草吗?
你对2019年手机即将展现出的全新变化,有哪些期待?是全新的处理器.更名副其实的全面屏,还是愈发强大的拍照功能,抑或折叠屏幕?但不管你有怎样的期待,手机厂商似乎总是"不解风情".常 ...
- PAN3501与AS3933完美兼容替代
现在不少校园门禁卡都是采用奥地利的AS3933,市场需求是供不应求,当然价格上还是不断上升趋势.成本上压力也是越来越大,不少厂家在寻找能替代软硬件兼容AS3933的芯片方案.今天我就为大家介绍一款能否 ...