python数据分析实例(1)
1.获取数据:
想要获得道指30只成分股的最新股价
import requests
import re
import pandas as pd def retrieve_dji_list():
try:
r = requests.get('https://money.cnn.com/data/dow30/')
except ConnectionError as err:
print(err)
search_pattern = re.compile('class="wsod_symbol">(.*?)<\/a>.*?<span.*?">(.*?)<\/span>.*?\n.*?class="wsod_stream">(.*?)<\/span>')
dji_list_in_text = re.findall(search_pattern, r.text)
dji_list = []
for item in dji_list_in_text:
dji_list.append([item[0], item[1], float(item[2])])
return dji_list dji_list = retrieve_dji_list()
djidf = pd.DataFrame(dji_list)
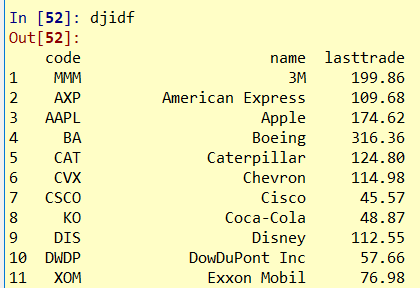
print(djidf)
整理数据, 改变列名, index等
cols=['code','name','lasttrade']
djidf.columns=cols # 改变列名
djidf.index=range(1,len(djidf)+1)
最后结果为:
数据的选择
djidf.code # 获取code列+index
djidf['code'] # 获取code列 , 两者同功能
djidf.loc[1:5,] # 前5行
djidf.loc[:,['code','lasttrade']] #所有行
djidf.loc[1:5,['code','lasttrade']] #1-5行, loc表示标签index
djidf.loc[1,['code','lasttrade']] #1行
djidf.at[1,'lasttrade'] # 只有一个值的时候可以用at
djidf.iloc[2:4,[0,2]] # 表示物理文职, 并且4取不到, 就只有第三行第四行
djidf.iat[1,2] # 单个值
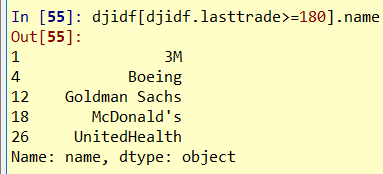
简单的数据筛选: 平均股价, 股价大于180的公司名
djidf.lasttrade.mean() # 121.132
djidf[djidf.lasttrade>=180].name
找到股价前三名的公司 , 降序排列
tempdf=djidf.sort_values(by='lasttrade',ascending=False)
tempdf[:3].name
如何根据index排序呢? 专门有函数sort_index()
df=pd.DataFrame(np.random.randn(3,3),index=['c','b','a'],columns=list('xyz'))
df.sort_index() # 根据index 进行排序
*获取AXP公司过去一年的股价数据获取
import requests
import re
import json
import pandas as pd
from datetime import date
def retrieve_quotes_historical(stock_code):
quotes = []
url = 'https://finance.yahoo.com/quote/%s/history?p=%s' % (stock_code, stock_code)
try:
r = requests.get(url)
except ConnectionError as err:
print(err)
m = re.findall('"HistoricalPriceStore":{"prices":(.*?),"isPending"', r.text)
if m:
quotes = json.loads(m[0]) # m = ['[{...},{...},...]']
quotes = quotes[::-1] # 原先数据为date最新的在最前面
return [item for item in quotes if not 'type' in item]
quotes = retrieve_quotes_historical('AXP')
list1=[]
for i in range(len(quotes)):
x=date.fromtimestamp(quotes[i]['date'])
y=date.strftime(x,'%Y-%m-%d')
list1.append(y)
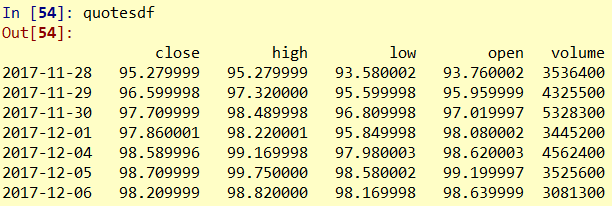
quotesdf_ori=pd.DataFrame(quotes,index=list1)
quotesdf_m = quotesdf_ori.drop(['adjclose'], axis = 1) #删除adjclose列
quotesdf=quotesdf_m.drop(['date'],axis=1)
print(quotesdf)
上述需要对时间进行处理, 将时间转为'%Y-%m-%d'的格式, 并且将这个时间作为一个list 成为quotesdf的index.
数据的筛选
quotesdf[(quotesdf.index>='2017-03-01') & (quotesdf.index<='2017-03-31')]
quotesdf[(quotesdf.index>='2017-11-30') & (quotesdf.index<='2018-03-31')&
(quotesdf.close>=90)]
简单计算
(1) 统计AXP股价涨跌的天数 (close>open)
len(quotesdf.close>quotesdf.open)
(2) 相邻两天的涨跌
import numpy as np
status=np.sign(np.diff(quotesdf.close))
status # 250 的长度, 比quotesdf 少1
status[np.where(status==1)].size # np.where(status==1)是由下标构成的array
#
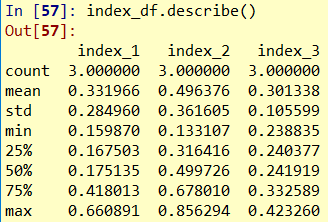
上述统计还可以直接用describe函数, 得到基本统计信息
import pandas as pd
import numpy as np
index_df = pd.DataFrame(np.random.rand(3,3), index=['a','b','c'], columns=['index_1','index_2','index_3'])
index_df.describe() # 超级强大
(3) 统计2018一月的交易日天数
t=quotesdf[(quotesdf.index>='2018-01-01') & (quotesdf.index<'2018-02-01')]
len(t) #21
进一步, 如何统计近一年每个月的交易日天数?
统计每个月的出现天数就行了, 如何提取月份信息? 要把时间的字符串转化为 时间格式,
import time
list2=[]
for i in range(len(quotesdf)):
temp=time.strptime(quotesdf.index[i],'%Y-%m-%d')
list2.append(temp.tm_mon) # 取月份
tempdf=quotesdf.copy()
tempdf['month']=list2 # 新增一列月份的数据
print(tempdf['month'].value_counts()) # 计算每个月的出现次数
注意:
strptime 将字符串格式化为time结构, time 中会包含年份, 月份等信息
strftime 将time 结构格式化一个字符串, 之前生成quotesdf中用到过
上述方法略微麻烦, 如何快速知道每个月的交易日天数? groupby
# 统计每一月的股票开盘天数
x=tempdf.groupby('month').count()
# 统计近一年每个月的成交量
tempdf.groupby('month').sum().volume
# 先每个月进行求和, 但是这些对其他列也进行了求和, 属于无效计算, 如何避免?
tempdf.groupby('month').volume.sum() # 交换顺序即可
引申: 一般groupby 与apply 在一起用. 具体不展开了
def f(df):
return df.age.count()
data_df.groupby('taste of mooncake').apply(f)
(二) 合并DataFrame: append, concat, join
# append
p=quotesdf[:2]
q=quotesdf['2018-01-01':'2018-01-05']
p.append(q) # concat
pieces=[tempdf[:5],tempdf[len(tempdf)-5:]]
pd.concat(pieces)
两个结构不同的DataFrame 如何合并?
piece1=quotesdf[0:3]
piece2=tempdf[:3]
pd.concat([piece1,piece2],ignore_index=True)
piece2有month 但是piece1中没有这个字段
join函数中的各种参数, 可以用来实现SQL的各种合并功能.
#join 两个dataframe要有共同的字段(列名)
#djidf: code/name
#AKdf: volume/code/month
# 合并之后的字段: code/name/volume/month
pd.merge(djidf.drop(['lasttrade'],axis=1),AKdf, on='code')
python数据分析实例(1)的更多相关文章
- Python数据分析实例操作
import pandas as pd #导入pandas import matplotlib.pyplot as plt #导入matplotlib from pylab import * mpl. ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- Python数据分析实战
Python数据分析实战(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1nlHM1IW8MYg3z79TUwIsWg 提取码:ux8t 复制这段内容后打开百度网盘手 ...
- python数据分析之pandas数据选取:df[] df.loc[] df.iloc[] df.ix[] df.at[] df.iat[]
1 引言 Pandas是作为Python数据分析著名的工具包,提供了多种数据选取的方法,方便实用.本文主要介绍Pandas的几种数据选取的方法. Pandas中,数据主要保存为Dataframe和Se ...
- 创建Python数据分析的Docker镜像+Docker自定义镜像commit,Dockerfile方式解析+pull,push,rmi操作
实例解析Docker如何通过commit,Dockerfile两种方式自定义Dcoker镜像,对自定义镜像的pull,push,rmi等常用操作,通过实例创建一个Python数据分析开发环境的Dock ...
- Python数据分析【炼数成金15周完整课程】
点击了解更多Python课程>>> Python数据分析[炼数成金15周完整课程] 课程简介: Python是一种面向对象.直译式计算机程序设计语言.也是一种功能强大而完善的通用型语 ...
- 【python数据分析实战】电影票房数据分析(二)数据可视化
目录 图1 每年的月票房走势图 图2 年票房总值.上映影片总数及观影人次 图3 单片总票房及日均票房 图4 单片票房及上映月份关系图 在上一部分<[python数据分析实战]电影票房数据分析(一 ...
- python&数据分析&数据挖掘--参考资料推荐书籍
1.要用python做数据分析,先得对python语言熟悉,推荐一本入门书 :笨方法学python (learn python the hard way),这本书用非常有趣的讲述方式介绍了python ...
- 《Python金融大数据分析》高清PDF版|百度网盘免费下载|Python数据分析
<Python金融大数据分析>高清PDF版|百度网盘免费下载|Python数据分析 提取码:mfku 内容简介 唯一一本详细讲解使用Python分析处理金融大数据的专业图书:金融应用开发领 ...
随机推荐
- Tomcat服务器下载、安装、配置环境变量教程(超详细)
请先配置安装好Java的环境,若没有安装,请参照我以下的步骤进行安装! 请先配置安装好Java的环境,若没有安装,请参照我以下的步骤进行安装! 请先配置安装好Java的环境,若没有安装,请参照我以下上 ...
- ubuntu fiddler firefox http网页不能访问 Secure Connection Failed
1. 给firefox导入fiddler的证书 1) fiddler:tools --> fiddler opthins --> https --> 勾选Capture HTTPS ...
- Django模板语言进阶
一.母板 1.什么情况下使用母版 当多个页面的大部分内容都一样的时候,我们可以把相同的部分提取出来,放到一个单独的母版HTML文件中 然后在母版中定义需要被替换的block 例如:母板页面 <! ...
- vue 中 echart 在子组件中只显示一次的问题
问题描述 一次项目开发过程中,需要做一些图表,用的是百度开源的 echarts. vue推荐组件化开发,所以就把每个图表封装成子组件,然后在需要用到该图表的父组件中直接使用. 实际开发中,数据肯定都是 ...
- 从浅入深详解独立ip网站域名恶意解析的解决方案
立IP空间的好处想必大家都能耳熟闻详,稳定性强,利于seo等让大家选择了鼎峰网络香港独立IP空间.那么, 网站独享服务器IP地址,独立IP空间利于百度收录和权重的积累.不受牵连.稳定性强等诸多优势为一 ...
- Luogu P2057 [SHOI2007]善意的投票
题目链接 \(Click\) \(Here\) 考虑模型转换.变成文理分科二选一带收益模型,就一波带走了. 如果没有见过这个模型的话,这里讲的很详细. #include <bits/stdc++ ...
- busybox编译
sync.c:(.text.sync_main+0x7c): undefined reference to `syncfs'Coreutils—>sync选项去掉 nsenter.c:(.tex ...
- Docker下安装GitLab
1.需要先安装Docker和Docker Compose,参考:https://www.cnblogs.com/hackyo/p/9280042.html 2.配置GitLab SSL(可跳过): m ...
- python中的GIL详解
GIL是什么 首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念.就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可 ...
- 如何解决failed to push some refs to git
$ git push -u origin master To git@github.com:yangchao0718/cocos2d.git ! [rejected] master -& ...