Python数据分析实例操作
import pandas as pd #导入pandas
import matplotlib.pyplot as plt #导入matplotlib
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
%matplotlib inline
数据读取与索引
bra = pd.read_csv('data/bra.csv')
bra.head()

选取列
bra.content

bra[['creationTime','productColor']].head()

选择行
bra[1:6]
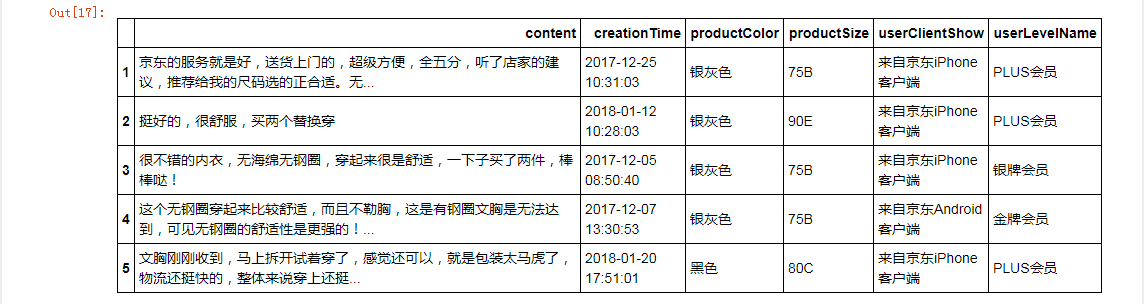
选择行和列
bra.ix[[2,3],[1,3]] #使用ix

bra.ix[1:5,['productColor']]

bra.iloc[[2,3],[1,3]] #使用iloc

bra.loc[1:5,['content','creationTime','productSize']] #使用loc

bra.loc[1:5,'content':'userClientShow']
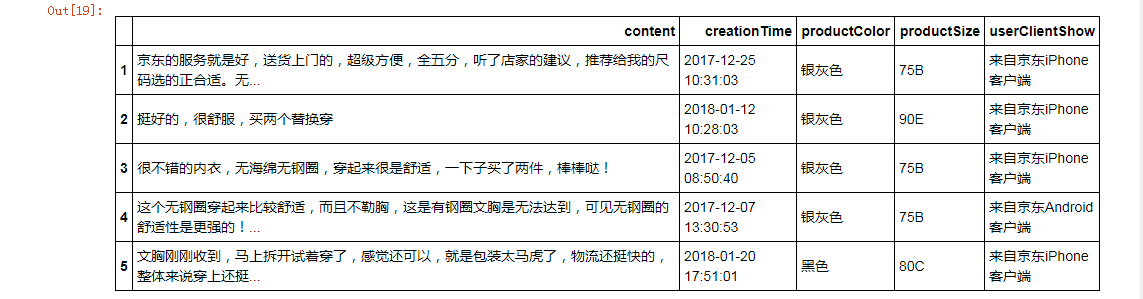
数据预处理
缺失值
bra.describe() #查看数据的分布情况,可返回变量和观测的数量、缺失值和唯一值的数目、平均值、分位数等相关信息

bra['userClientShow'].unique() #userClientShow列有几种选项
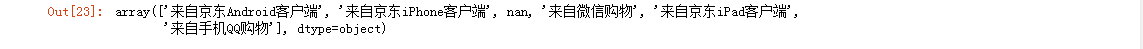
bra['userClientShow'].isnull().sum() #初始缺失值数量

bra['userClientShow'].fillna('不详',inplace=True) #缺失值替换为“不详”
bra['userClientShow'].isnull().sum() #赋值后的缺失值数量

新增列
bra.dtypes #查看属性

bra['creationTime'] = pd.to_datetime(bra['creationTime']) #更新类型
bra.dtypes

bra['hour'] = [i.hour for i in bra['creationTime']] #新建hour列
bra

字符串操作
bra.productSize.unique() #查看productSize的唯一值

cup = bra.productSize.str.findall('[a-zA-Z]+').str[0] #新增列cup
cup2 = cup.str.replace('M','B')
cup3 = cup2.str.replace('L','C')
cup4 = cup3.str.replace('XC','D')
bra['cup'] = cup4
bra.head()

bra['cup'].unique() #查看cup唯一值

数据转换
bra.productColor.unique() #查看productColor唯一值

def getColor(s):
if '黑' in s:
return '黑色'
elif '肤' in s:
return '肤色'
elif '蓝' in s:
return '蓝色'
elif '红' in s:
return '红色'
elif '紫' in s:
return '紫色'
elif '白' in s:
return '白色'
elif '粉' in s:
return '粉色'
elif '灰' in s:
return '灰色'
elif '绿' in s:
return '绿色'
elif '青' in s:
return '青色'
else:
return s
bra['color'] = bra['productColor'].map(getColor) #从productColor列查询,赋值到定义的函数getColor,最终新增列color
bra
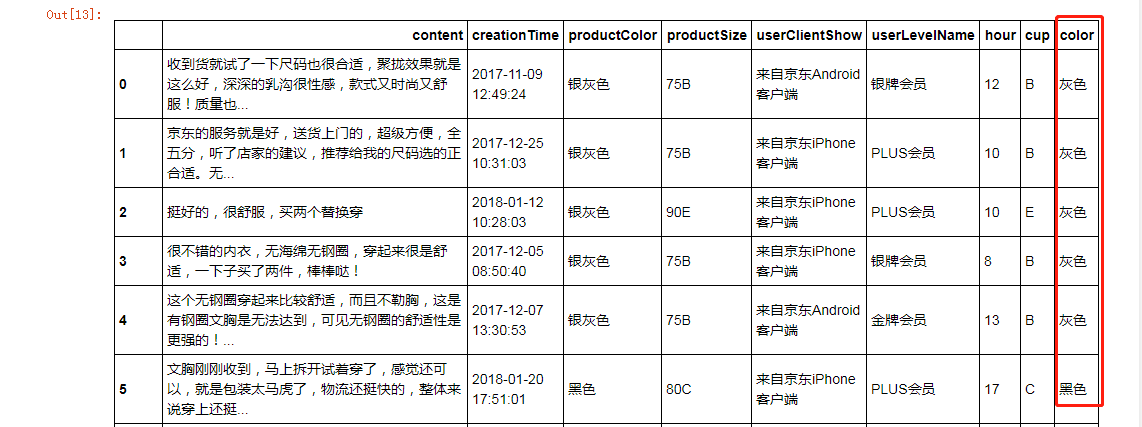
bra.color.unique() #查询color的唯一值

数据可视化
x = [1991,1992,1993,1994,1995,1996,1997]
y = [23,56,38,29,34,56,92]
plt.plot(x,y) #调用函数plot
plt.figure(figsize=(8,6),dpi=80) #调用函数firgure
plt.plot(x,y)
hour = bra.groupby('hour')['hour'].count() #hour列排序
hour

plt.xlim(0,25) #横轴0~25
plt.plot(hour,linestyle='solid',color='royalblue',marker='8') #颜色深蓝

cup_style = bra.groupby('cup')['cup'].count() #cup列唯一值得数量
cup_style

plt.figure(figsize=(8,6),dpi=80)
labels = list(cup_style.index)
plt.xlabel('cup') #x轴为cup
plt.ylabel('count') #y轴为count数量
plt.bar(range(len(labels)),cup_style,color='royalblue',alpha=0.7) #alpha为透明度
plt.xticks(range(len(labels)),labels,fontsize=12)
plt.grid(color='#95a5a6',linestyle='--',linewidth=1,axis='y',alpha=0.6)
plt.legend(['user-count'])
for x,y in zip(range(len(labels)),cup_style):
plt.text(x,y,y,ha='center',va='bottom')

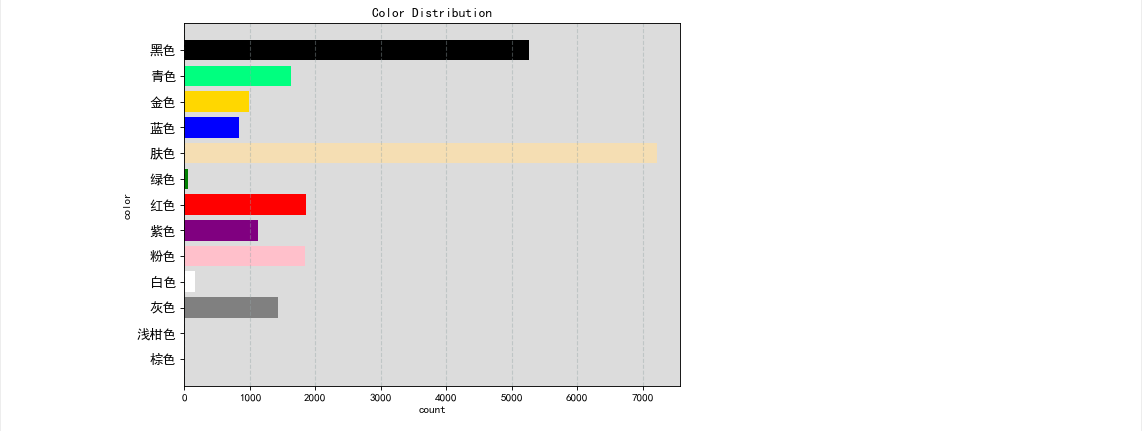
color_style = bra.groupby('color')['color'].count() #color列唯一值得数量
color_style

plt.figure(figsize=(8,6),dpi=80)
plt.subplot(facecolor='gainsboro',alpha=0.2)
colors = ['brown','orange','gray','white','pink','purple','red','green','wheat','blue','gold','springgreen','black'] #颜色种类
labels = list(color_style.index)
plt.xlabel('count') #x轴为count数量
plt.ylabel('color') #y轴为color
plt.title('Color Distribution') #定义标题
plt.barh(range(len(labels)),color_style,color=colors,alpha=1)
plt.yticks(range(len(labels)),labels,fontsize=12)
plt.grid(color='#95a5a6',linestyle='--',linewidth=1,axis='x',alpha=0.4)
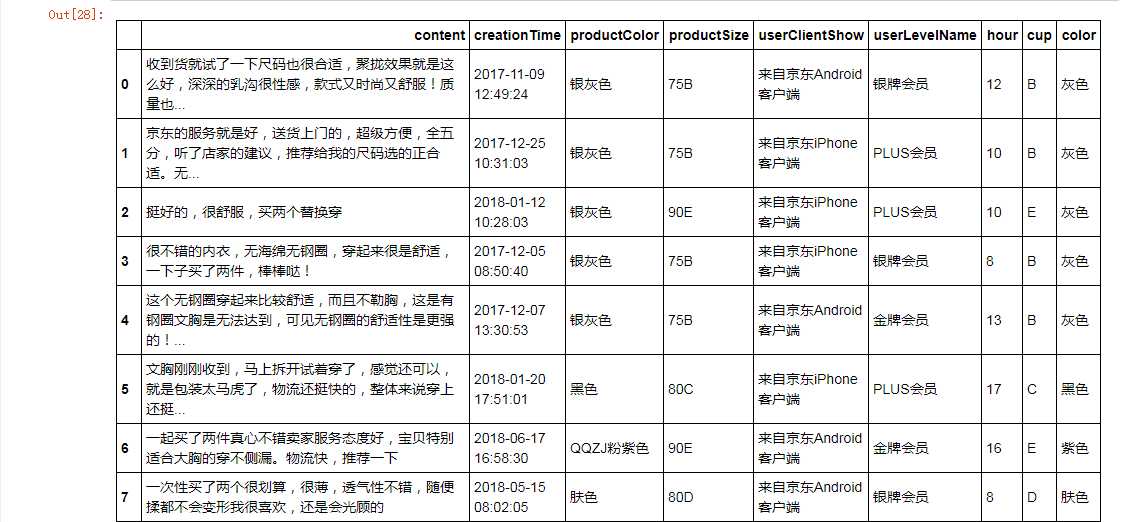
bra.head(30)
Python数据分析实例操作的更多相关文章
- python数据分析实例(1)
1.获取数据: 想要获得道指30只成分股的最新股价 import requests import re import pandas as pd def retrieve_dji_list(): try ...
- 创建Python数据分析的Docker镜像+Docker自定义镜像commit,Dockerfile方式解析+pull,push,rmi操作
实例解析Docker如何通过commit,Dockerfile两种方式自定义Dcoker镜像,对自定义镜像的pull,push,rmi等常用操作,通过实例创建一个Python数据分析开发环境的Dock ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- Python之虚拟机操作:利用VIX二次开发,实现自己的pyvix(系列一)成果展示和python实例
在日常工作中,需要使用python脚本去自动化控制VMware虚拟机,现有的pyvix功能较少,而且不适合个人编程习惯,故萌发了开发一个berlin版本pyvix的想法,暂且叫其OpenPyVix.O ...
- 小白学 Python 数据分析(5):Pandas (四)基础操作(1)查看数据
在家为国家做贡献太无聊,不如跟我一起学点 Python 人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Panda ...
- 小白学 Python 数据分析(6):Pandas (五)基础操作(2)数据选择
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- Python数据分析之Pandas操作大全
从头到尾都是手码的,文中的所有示例也都是在Pycharm中运行过的,自己整理笔记的最大好处在于可以按照自己的思路来构建矿建,等到将来在需要的时候能够以最快的速度看懂并应用=_= 注:为方便表述,本章设 ...
- 小白学 Python 数据分析(17):Matplotlib(二)基础操作
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
随机推荐
- mysql优化:慢查询分析、索引配置优化
一.优化概述二.查询与索引优化分析a.性能瓶颈定位show命令慢查询日志explain分析查询profiling分析查询b.索引及查询优化三.配置优化 max_connections back_log ...
- Tomcat8源码笔记(二)Bootstrap启动
TOMCAT源码调试入口是Bootstrap类的main方法,我的启动参数VM: -Dcatalina.home=E:/Tomcat_Source_Code/apache-tomcat-8.0.53- ...
- IdentityServer4关于多客户端和API的最佳实践【含多类型客户端和API资源,以及客户端分组实践】【下】
经过前两篇文章你已经知道了关于服务器搭建和客户端接入相关的基本资料,本文主要讲述整个授权系统所服务的对象,以ProtectApi资源为演示 目标: 1)实现多资源服务器针对请求的token校验,接入I ...
- C# 字符串拼接性能探索
本文通过ANTS Memory Profiler工具探索c#中+.string.Concat.string.Format.StringBuilder.Append四种方式进行字符串拼接时的性能. 本文 ...
- 深入理解JVM——对象
对象的创建 虚拟机遇到一条new指令时,首先检查指令的参数能否在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已经被加载.解析和初始化过.如果没有,必须先执行相应的类加载过程. 接下 ...
- blfs(systemv版本)学习笔记-编译安装ligtdm显示管理器
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! ligtdm带有显示管理器和登录器,参照我的笔记安装xorg和i3后安装lightdm,就可以组成一个简易的桌面环境了 下面是l ...
- blfs(systemv版本)学习笔记-编译安装sudo并创建普通用户配置sudo权限
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! blfs书中sudo的安装配置章节:http://www.linuxfromscratch.org/blfs/view/8.3/ ...
- js之跑马灯广告
目标效果:每过1秒重复把广告的第一个字符放到最后,达到动态跑马灯效果 代码如下: <!DOCTYPE html> <html lang="en"> < ...
- 前端开发面试题-CSS(转载)
本文由 本文的原作者markyun 收集总结. 介绍一下标准的CSS的盒子模型?低版本IE的盒子模型有什么不同的? (1)有两种, IE 盒子模型.W3C 盒子模型: (2)盒模型: 内容(conte ...
- Mybatis PageHelper 简单使用
流程 1,maven 依赖 2,在 mybatis 配置文件启用插件 3,修改 service 层 依赖 <!-- https://mvnrepository.com/artifact/com. ...