【Python3爬虫】12306爬虫
此次要实现的目标是登录12306网站和查看火车票信息。
具体步骤
一、登录
登录功能是通过使用selenium实现的,用到了超级鹰来识别验证码。没有超级鹰账号的先注册一个账号,充值一点题分,然后把下载这个Python接口文件,再在里面添加一个use_cjy的函数,以后使用的时候传入文件名就可以了(验证码类型和价格可以在价格体系查看):
def use_cjy(filename):
username = "" # 用户名
password = "" # 密码
app_id = "" # 软件ID
cjy = CJYClient(username, password, app_id) # 用户中心>>软件ID
im = open(filename, 'rb').read() # 本地图片文件路径
return cjy.PostPic(im, 9004) # 9004->验证码类型
然后进入12306的登录页面,网址为https://kyfw.12306.cn/otn/login/init,可以看到有一个像下面这样的验证码:
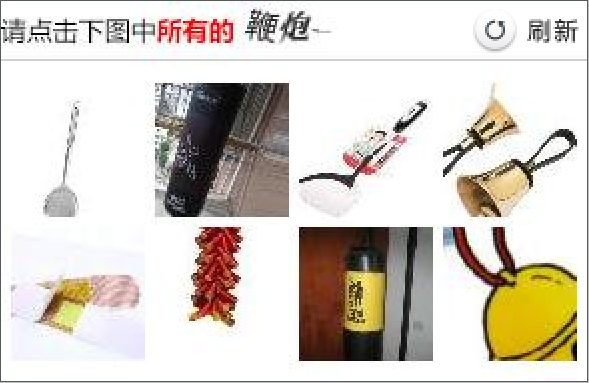
要破解这个验证码,第一个问题是怎么得到这个验证码图片,我们可以很轻松的找到这个验证码图片的链接,但是如果用requests去请求这个链接,然后把图片下载下来,这样得到的图片和网页上的验证码图片是不同的,因为每次请求都会刷新一次验证码。所以需要换个思路,比如先把网页截个图,然后我们可以知道验证码图片在网页中的位置,然后再根据这个位置,把截图相应的位置给截取出来,就相当于把验证码图片从整个截图中给抠出来了,这样得到的验证码图片就和网页上的验证码一样了。相关代码如下:
# 定位到验证码图片
captcha_img = browser.find_element_by_xpath('//*[@id="loginForm"]/div/ul[2]/li[4]/div/div/div[3]/img')
location = captcha_img.location
size = captcha_img.size
# 写成我们需要截取的位置坐标
coordinates = (int(location['x']), int(location['y']),
int(location['x'] + size['width']), int(location['y'] + size['height']))
browser.save_screenshot('screen.png')
i = Image.open('screen.png')
# 使用Image的crop函数,从截图中再次截取我们需要的区域
verify_code_image = i.crop(coordinates)
verify_code_image.save('captcha.png')
现在已经得到了验证码图片了,下一个问题是怎么识别?点触验证码识别起来有两个难点,一个是文字识别,要把图上的鞭炮文字识别出来,第二点是识别图片中的内容,比如上图就要把有鞭炮的图片识别出来,而这两个难点利用OCR技术都很那实现,因此选择使用打码平台(比如超级鹰)来识别验证码。对于上面这个图,在使用超级鹰识别之后会返回下面这个结果:
{'pic_id': '6048511471893900001', 'err_no': 0, 'err_str': 'OK', 'md5': 'bde1de3b886fe2019a252934874c6669', 'pic_str': '117,140'}
其中pic_str对应的值就是有鞭炮的图片的坐标位置(如果有多个坐标,会用“|”进行分隔),我们对这个结果进行解析,把坐标提取出来,再利用selenium模拟点击就可以了,相关代码如下:
# 调用超级鹰识别验证码
capture_result = use_cjy('captcha.png')
print(capture_result)
# 对返回的结果进行解析
groups = capture_result.get("pic_str").split('|')
points = [[int(number) for number in group.split(',')] for group in groups]
for point in points:
# 先定位到验证图片
element = WebDriverWait(browser, 20).until(
EC.presence_of_element_located((By.CLASS_NAME, "touclick-bgimg")))
# 模拟点击验证图片
ActionChains(browser).move_to_element_with_offset(element, point[0], point[1]).click().perform()
sleep(1)
二、查询
带有车票信息的ajax接口很容易找到,格式也是标准的json格式,解析起来会方便不少

但是爆保存车票的字符串很复杂,我们先把第一条信息打印出来看看,以下是部分信息:
'hH0qeKPBgl0X0aCnrtZFyBgzqydzV45U2M1r%2F32FsaPHeb7Mul00sIb7y9W%2B6df1tUdDGCxqdVs8%0Aw2VodSjdXjUQ2uNdwFprKdVK9iaW60Wj2jKpNKaViR4ndlBCjsYB0SIF
QR0pLksy7HDP0KcaoLe4%0A4RW6zRcscO7SRNJZOsF%2Fxj3Ooq76lzzdku3Uw957yjLFyf7ikixOaC%2FAOrLAwCc7y0krRpKJbSn3%0ApBsY%2F%2Fok%2Bmg2xNhXapoCPIt4w0p9', 这段字符是随机生成的,过几秒就回失效。
'39000D30280G', 列车编号
'D3028', 车次
'HKN', 始发站
'AOH', 终点站
'HKN', 出发站
'AOH', 目的站
'07:31', 出发时间
'13:06', 到达时间
'05:35', 总耗时
'Y', Y表示可以购票,N表示不可以
'20181111', 日期
后面基本都是座位的余票信息了。
对于提到的列车站点代码,可以通过请求这个链接,通过得到JS脚本中的station_names变量获取,对应的站点以@字符分隔,相关代码如下:
# 请求保存列车站点代码的链接
res1 = requests.get("https://kyfw.12306.cn/otn/resources/js/framework/station_name.js")
# 把分割处理后的车站信息保存在station_data中
self.station_data = res1.text.lstrip("var station_names ='").rstrip("'").split('@')
# 返回车站英文缩写
def get_station(self, city):
for i in self.station_data:
if city in i:
return i.split('|')[2] # 返回车站中文缩写
def get_city(self, station):
for i in self.station_data:
if station in i:
return i.split('|')[1]
由于ajax接口有了一点变化,所以我对之前的代码做了一点修改,在输入数据的部分:
# 需要按2018-01-01的格式输入日期,不然会出现错误
d = input("请输入日期(如:2018-01-01):")
f = self.get_station(input("请输入您的出发站:"))
t = self.get_station(input("请输入您的目的站:"))
url = "https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}" \
"&leftTicketDTO.to_station={}&purpose_codes=ADULT".format(d, f, t)
完整代码已上传到GitHub!
【Python3爬虫】12306爬虫的更多相关文章
- 利用Python实现12306爬虫--查票
在上一篇文章(http://www.cnblogs.com/fangtaoa/p/8321449.html)中,我们实现了12306爬虫的登录功能,接下来,我们就来实现查票的功能. 其实实现查票的功能 ...
- python3爬虫--反爬虫应对机制
python3爬虫--反爬虫应对机制 内容来源于: Python3网络爬虫开发实战: 网络爬虫教程(python2): 前言: 反爬虫更多是一种攻防战,针对网站的反爬虫处理来采取对应的应对机制,一般需 ...
- python3编写网络爬虫20-pyspider框架的使用
二.pyspider框架的使用 简介 pyspider是由国人binux 编写的强大的网络爬虫系统 github地址 : https://github.com/binux/pyspider 官方文档 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- 【java爬虫】---爬虫+基于接口的网络爬虫
爬虫+基于接口的网络爬虫 上一篇讲了[java爬虫]---爬虫+jsoup轻松爬博客,该方式有个很大的局限性,就是你通过jsoup爬虫只适合爬静态网页,所以只能爬当前页面的所有新闻.如果需要爬一个网站 ...
- [爬虫]Python爬虫基础
一.什么是爬虫,爬虫能做什么 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.比如它在抓取一个网 ...
- (Pyhton爬虫03)爬虫初识
原本的想法是这样的:博客整理知识学习的同时,也记录点心情...集中式学习就没这么多好记录的了! 要学习一门技术,首先要简单认识一下爬虫!其实可以参考爬虫第一章! 整体上介绍该技术包含技能,具体能做什么 ...
- PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二手急速响应捡垃圾平台_3(附源码持续更新)
说明 文章首发于HURUWO的博客小站,本平台做同步备份发布. 如有浏览或访问异常图片加载失败或者相关疑问可前往原博客下评论浏览. 原文链接 PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二 ...
- 【Python3爬虫】最新的12306爬虫
一.写在前面 我在以前写过一次12306网站的爬虫,当时实现了模拟登录和查询车票,但是感觉还不太够,所以对之前的代码加以修改,还实现了一个订购车票的功能. 二.主要思路 在使用Selenium做模拟登 ...
随机推荐
- 简单的dfs题 --- POJ1321 棋盘问题
题目链接: http://poj.org/problem?id=1321 题目大意: 你有k个棋子,若干个可以填的位置,要求填下一个棋子后其行和列不能填棋子. 思路: dfs策略 画图理解更好些: 填 ...
- CSS空心圆
CSS代码:改变border的大小控制空心的大小 div { width: 100px; height: 100px; background: #ffffff; border-radius: 50%; ...
- [CF1132G]Greedy Subsequences
[CF1132G]Greedy Subsequences 题目大意: 定义一个序列的最长贪心严格上升子序列为:任意选择第一个元素后,每次选择右侧第一个大于它的元素,直到不能选为止. 给定一个长度为\( ...
- C++ 用变量定义数组
较早的编译器是不同意这样做的,所以一些书籍比方以Tc解说的书本都说数组的下标不能是变量.在vc6.0下亦是如此. 只是在一些较新的编译器如dev c++已经支持了,例如以下代码不会报错 #includ ...
- vijos搭建踩坑
nodejs我用的8.x版本,可以工作. 和制作组交谈之后他们说最好榨汁机和主机不要在同一系统下. vj4/vj4/handler/base.py的第343行 从 super(Connection, ...
- react生命周期函数
如图,可以把组件生命周期大致分为三个阶段: 第一阶段:是组件第一次绘制阶段,如图中的上面虚线框内,在这里完成了组件的加载和初始化: 第二阶段:是组件在运行和交互阶段,如图中左下角虚线框,这个阶段组 ...
- codeforces 13 D
给你500个红点和蓝点,让你找多少点红点构成的三角形里没有蓝点. 巧妙啊!我们考虑一个很远位置的点,不妨设这个为O,然后n^2枚举红点,考虑Oij里面蓝点的个数, 然后 对于 ijk这个三角形,我们可 ...
- 老桂.net core系列课程
为了支持"首届dnc开源峰会"(dncNew.com)顺利举办,本人<.net core系列课程>进行一波优惠,每个课程优惠在立即购买上方,领取现金券即可.课程地址为腾 ...
- 基于 TensorFlow 在手机端实现文档检测
作者:冯牮 前言 本文不是神经网络或机器学习的入门教学,而是通过一个真实的产品案例,展示了在手机客户端上运行一个神经网络的关键技术点 在卷积神经网络适用的领域里,已经出现了一些很经典的图像分类网络,比 ...
- Python科学计算基础包-Numpy
一.Numpy概念 Numpy(Numerical Python的简称)是Python科学计算的基础包.它提供了以下功能: 快速高效的多维数组对象ndarray. 用于对数组执行元素级计算以及直接对数 ...