Python中关于列表嵌套列表的处理
在处理列表的时候我们经常会遇到列表中嵌套列表的结构,如果我们要把所有元素放入一个新列表,或者要计算所有元素的个数的话应该怎么做呢?
第一个例子
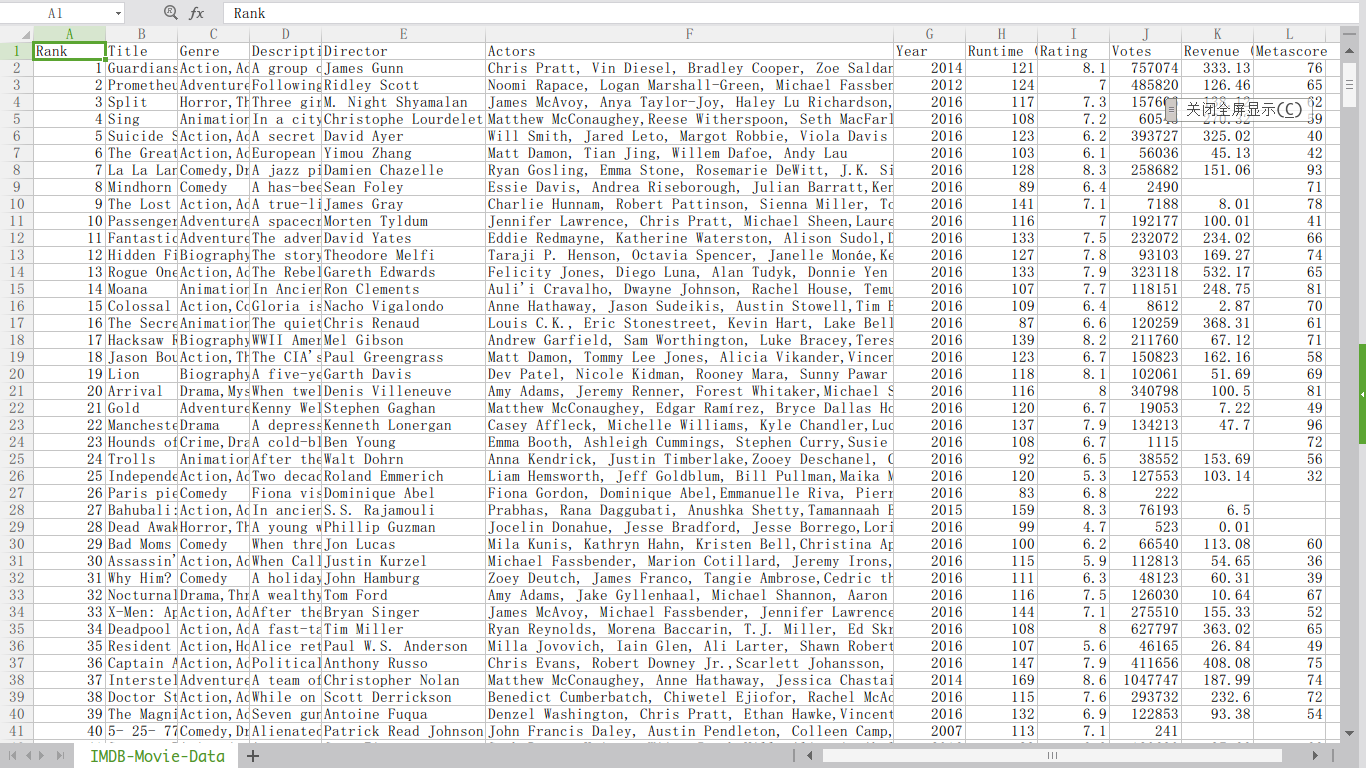
对于上图中的这样一组数据,如果我们要知道这个CSV文件中所有演员的数量(同一个人只能出现一次)应该怎么做呢?
在pandas中我们可以先取Actors这一列,但是取出来之后我们会发现这是一个列表中嵌套列表的结构,要想将所有元素提取出来我们可以使用两个for循环来解决这一问题。代码如下:
# encoding = utf-8
import pandas as pd
file_path = "d:/learning/pandas/IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df.head(1))
# 读平均评分
print(df["Rating"].mean())
# 导演的人数(下面两个操作达到的效果是一样的)
print(len(set(df["Director"].tolist())))
print(len(df["Director"].unique()))
# 获取演员的人数
temp_list = df["Actors"].str.split(", ").tolist()
# 将列表套列表转为单列表
actors_list = [i for j in temp_list for i in j]
# set函数是对列表作集合操作,可以去重
print(len(set(actors_list)))
第二个例子
我们再来看第二组例子,还是上图中的数据,如果我们想要统计各个分类的电影的数量,应该怎么做呢?核心思想是:
- 先处理列表嵌套列表,将所有的分类统计出来;
- 建立一个值全为0的数组,这个数组的行数等于电影数,列数等于分类数;
- 在这个数组的列方向上进行求和,得出结果。
# coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = "~/桌面/IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
# 新建临时列表,将数组中分类列读取
temp_list = df["Genre"].str.split(",").tolist()
# 处理列表嵌套列表的结构,去除重复元素
Genre_list = set([i for j in temp_list for i in j])
# 新建一个统计数组,即上文所说的第二步
a = pd.DataFrame(np.zeros((df.shape[0], len(Genre_list))), columns=Genre_list, dtype=int)
# 赋值,将上述列表中对应的位置的值变为1
for i in range(len(temp_list)):
a.loc[i, temp_list[i]] = 1
# 求和,统计每个分类的电影的数量
sum = a.sum(axis=0)
sum = sum.sort_values(ascending=False)
# 绘制条形统计图
_x = sum.index
_y = sum.values
plt.figure(figsize=(20, 8), dpi=80)
plt.yticks(range(max(sum.values)+50)[::50])
plt.bar(_x, _y)
plt.show()
结果如图:
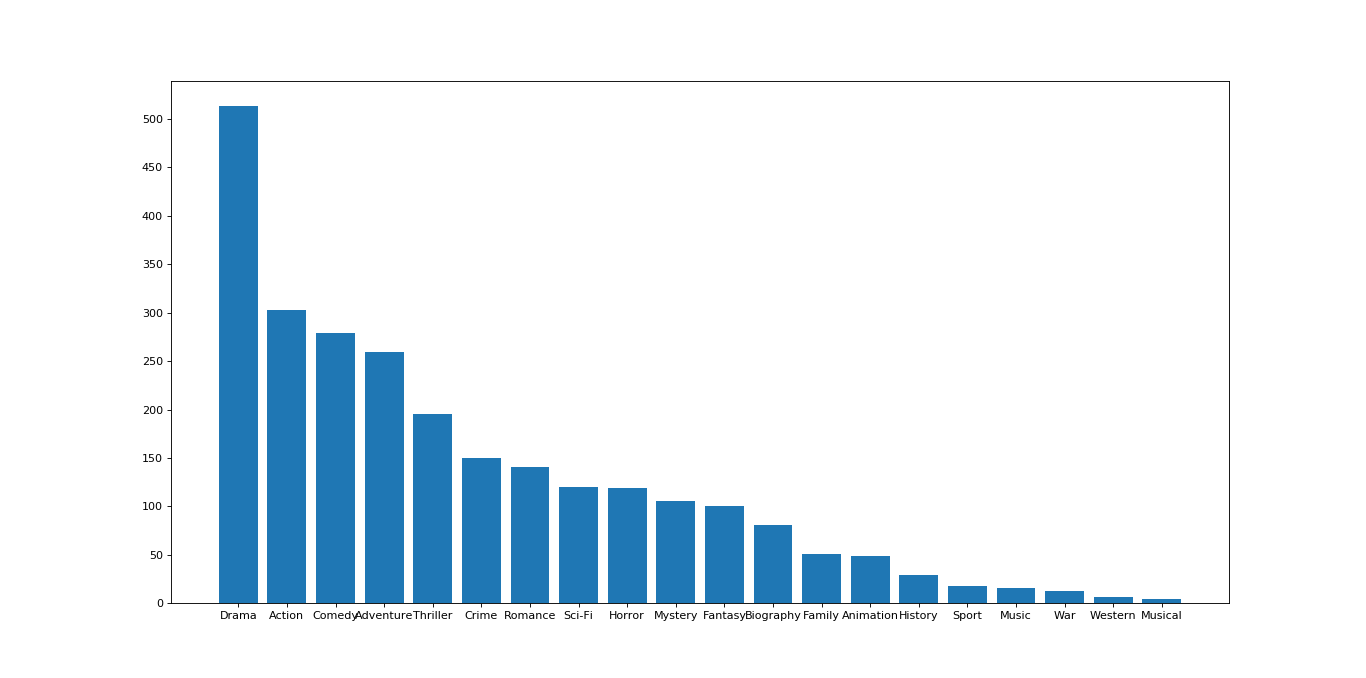
这里有一个重要的问题,如果原始数据的行数特别多,再采用for循环进行行遍历就会耗费特别长的时间
解决办法见这里的第三个例子。
Python中关于列表嵌套列表的处理的更多相关文章
- python中字典排序,列表中的字典排序
python中字典排序,列表中的字典排序 一.使用python模块:operator import operator #首先要导入模块operator x = {1:2, 3:4, 4:3, 2:1, ...
- Python中元祖,列表,字典的区别
Python中有3种內建的数据结构:列表.元祖和字典: 1.列表 list是处理一组有序项目的数据结构,即你可以在一个列表中存储一个序列的项目. 列表中的项目应该包括在方括号中,这样Python就知道 ...
- Python中的两种列表
python中有两种类型的列表:其中一种是用[]创建的列表,这种列表具有伸缩性,可以动态改变,而另外一种列表是用()创建,成为元组,元组一旦创建,在任何状况下都不能再改变,是一种常量列表. movie ...
- python中sorted方法和列表的sort方法使用详解
一.基本形式 列表有自己的sort方法,其对列表进行原址排序,既然是原址排序,那显然元组不可能拥有这种方法,因为元组是不可修改的. 排序,数字.字符串按照ASCII,中文按照unicode从小到大排序 ...
- python中sorted方法和列表的sort方法使用
一.基本形式 列表有自己的sort方法,器对列表进行原值排序,既然是原址排序,那显然元组不可能拥有这个方法,因为元组是不可修改的. 排序,数字.字符串按照ASCII,中文按照unicode从小到大排序 ...
- python中的数组和列表
####转自:模式识别实验室主任 #环境win64+anaconda+python3.6 list & array (1)list不具有array的全部属性(如维度.转置等) 代码1: # ...
- 如何在python中把两个列表的各项分别合并为列表
[ [a,b] for a,b in zip(list1,list2)] 生成一个以列表list1,list2各项合并列表为元素的列表
- python中强大优雅的列表推导表达式
推导表达式其实就是简化一些循环判断操作等 生成一个数字1-10的列表,可以有多少种方法? >>> l = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ] > ...
- python中range函数与列表中删除元素
一.range函数使用 range(1,5) 代表从1到4(不包含5),结果为:1,2,3,4 ,默认步长为1 range(1,5,2) 结果为:1, 3 (同样不包含5) ,步长为2 ...
随机推荐
- 一、大体认识jspxcms
声明:jspxcms的license写明,允许将jspxcms用于商业和非商业用途.此处只是作为研究.分享使用心德,并不涉及商用. 使用版本:jspxcms 9.5.0 一.下载源码,并部署到ecl ...
- HBuilder打包vue项目app后空白,并请求不到数据
(解决空白问题)在打包之前一定要修改 config 目录下的 index.js 文件中的 bulid 模块打包配置项,否则会出现空白,如图 修改前 assetsPublicPath= '/',. ...
- SQL SERVER 基本操作语句
Sql 是一种结构化的查询语言:Sql是一种数据库查询和程序设计语言,用于存取数据以及查询.更新和管理‘关系型数据库’系统:Sql对大小写不敏感:Sql不是数据库,是行业标准,是结构化的查询语言 In ...
- 虚拟机中linux系统的安装教程
虚拟机是什么? 虚拟机(Virtual Machine)是指一种特殊的软件,可以在计算机和用户之间创建一种环境,用户可以用这个软件所创建的环境来操作.虚拟机就像像真实机器一样运行程序,满足用户的需求. ...
- CentOS系统/tmp目录里面的文件默认保留多久
一.CentOS系统/tmp目录里面的文件默认保留多久 CentOS6默认保留30天,CentOS7默认保留10天 一.CentOS7系统/tmp目录里面的文件默认保留多久 CentOS7默认保留10 ...
- 用python脚本获取运行环境中的module 列表
由于脚本运行在远程环境,总报错说一些module没有.所以决定彻底对环境进行一次摸底. 于是,用如下代码即可实现: #!/usr/bin/env python import sys try: #pri ...
- Solaris环境下使用snoop命令抓包
(1)报文抓取 Solaris中自带有snoop抓包工具,通过执行相应的命令抓取. 抓取目的地址为10.8.3.250的数据包,并存放到/opt/cap250的文件里 snoop -o /opt/ca ...
- arcgis for JavaScript API 4.5与4.3的区别
arcgis 4.5与4.3区别: 鉴于本人使用4.3时间比较久,而arcgis for JavaScript API于9月28日推出了4.5版本,但是直接更换4.5的init.js会出现意想不到的错 ...
- webpack入门文档教程
.octicon{margin-right:2px}a.tabnav-extra:hover{color:#4078c0;text-decoration:none}.tabnav-btn{margin ...
- winsock I/O模型的分析
几种winsock I/O模型的分析 套接字是通信的基础,是支持网络协议数据通信的基本接口.Winsocket 提供了一些有趣的I/O模型,有助于应用程序通过一种“异步”方式,一次对一个或者多个套接字 ...