Storm环境搭建(分布式集群)
作为流计算的开篇,笔者首先给出storm的安装和部署,storm的第二篇,笔者将详细的介绍storm的工作原理。下边直接上干货,跟笔者的步伐一块儿安装storm。
原文链接:Storm环境搭建(分布式集群)
Step1:新建用户
在所有主机上新建hadoop用户,密码是Hadoop123
useradd hadoop
passwd hadoop
输入密码Hadoop123
Step2:设置免密登录
设置所有主机之间ssh免密码登录。设置主节点到从节点的免密码登录即可。
Step3:软件包下载
(1)mkdir -p /mnt/data/software
(2)将所需要的软件包放在/mnt/data/software目录下
如需要以下三个安装包,请长按文末二维码关注“大数据技术宅”,后台输入“storm安装包”获取。
jdk-8u121-linux-i586.tar.gz
apache-storm-1.0.5.tar.gz
zookeeper-3.4.10.tar.gzStep4:安装JDK
(1)卸载openjdk
rpm -qa | grep jdk
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodepscopy-jdk-configs-1.2-1.el7.noarch
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
(2)安装jdk1.8
cd /mnt/data/software
tar -zxvf jdk-8u121-linux-i586.tar.gz
配置java环境变量
vim /etc/profile在文件中写入以下内容
JAVA_HOME=/mnt/data/software/jdk1.8.0_121
JRE_HOME=/mnt/data/software/jdk1.8.0_121/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
使环境变量生效:source/etc/profile
Step5:安装zookeeper
(1)关闭三台机器上的防火墙(CentOS 7)
firewall-cmd --state 查看防火墙状态
systemctl stop firewalld.service 关闭防火墙
systemctl disable firewalld.service 禁止开机启动(2)安装
cd /mnt/data/software
tar -zxvf zookeeper-3.4.10.tar.gz
mv zookeeper-3.4.10
cd zookeeper/conf
将conf目录中的zoo_sample.cfg文件复制为zoo.cfg并利用vi命令进行修改
dataDir=/mnt/data/software/zookeeper/data
server.1=ip:2888:3888 ip为服务器的ip
server.2=ip:2888:3888 ip为服务器的ip
server.3=ip:2888:3888 ip为服务器的ip
这里的dataDir需要自己创建 mkdir命令创建,并在目录下创建一个文件:myid分别在myid上按照配置文件的server.<id>中id的数值,在不同机器上的该文件中填写相应过的值1|2|3
如[root@safe01data]# vim myid
1
保存即可
(3)添加zookeeper环境变量
vim /etc/profile
ZOOKEEPER_HOME=/mnt/data/software/zookeeper
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin
export JAVA_HOME CLASSPATH ZOOKEEPER_HOME PATH
引用环境变量:source/etc/profile
(4)测试安装
三台机器执行zkServer.shstart进行启动zookeeper
查看状态zkServer.shstatus
[root@safe01 data]# zkServer.sh status
JMX enabled by default
Using config: /mnt/data/software/zookeeper/bin/../conf/zoo.cfg
Mode: follower
两个follower一个leader就是正确的
Step6:安装Storm
(1)安装
cd /mnt/data/software
tar -zxvf apache-storm-1.0.5.tar.gz
mv apache-storm-1.0.5 storm
cd ./storm/conf
编辑storm.yaml
storm.zookeeper.servers:
- "172.16.2.27"
- "172.16.2.42"
- "172.16.2.72"
#nimbus
nimbus.host: "172.16.2.27"
ui.port: 8081
supervisor.slots.ports:
-6700
-6701
-6702
-6703
storm.local.dir:"/mnt/data/software/storm/data"
创建数据文件目录:mkdir /mnt/data/software/storm/data
将storm分发到其他主机上:
scp -r /mnt/data/software/storm/ hadoop@172.16.2.42:/mnt/data/software
scp -r /mnt/data/software/storm/ hadoop@172.16.2.72:/mnt/data/software
在所有主机上添加storm的环境变量:
STORM_HOME=/mnt/data/software/storm
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$STORM_HOME/bin:$KAFKA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH ZOOKEEPER_HOME STORM_HOME KAFKA_HOME PATH
(2)启动
在主机centos上开启nimbus进程
storm nimbus &
在另外两台机子上开启supervisor 进程
storm supervisor &
开启完按Ctrl+c
在centos主机上开启
storm ui &
storm logviewer &
这样就可以通过web查看storm部署情况了
访问http://172.16.2.27:8080/,如图:
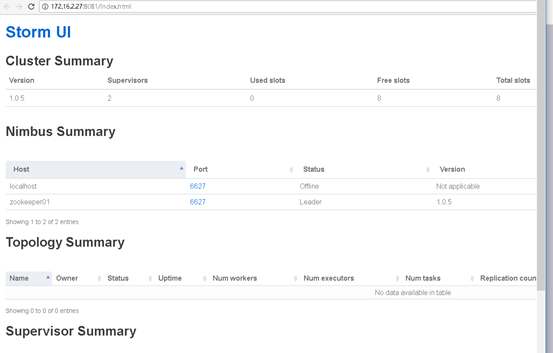
下篇。。。
Storm环境搭建(分布式集群)的更多相关文章
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境 一.环境说明 个人理解:zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hadoo ...
- Windows及Linux环境搭建Redis集群
一.Windows环境搭建Redis集群 参考资料:Windows 环境搭建Redis集群 二.Linux环境搭建Redis集群 参考资料:Redis Cluster的搭建与部署,实现redis的分布 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- 环境搭建-CentOS集群搭建
环境搭建-CentOS集群搭建 写在前面 最近有许多小伙伴问我,大数据的hadoop分布式集群该如何去搭建.所以,想着,就写一篇博客,帮助到更多刚入门大数据的人.本博客会一步一步带你实现一个Hadoo ...
- Redis.之.环境搭建(集群)
Redis.之.环境搭建(集群) 现有环境: /u01/app/ |- redis # 单机版 |- redis-3.2.12 # redis源件 所需软件:redis-3.0.0.gem -- ...
- Windows 环境搭建Redis集群(win 64位)
转: http://blog.csdn.net/zsg88/article/details/73715947 参考:https://www.cnblogs.com/tommy-huang/p/6240 ...
- CentOS 7 环境搭建kafka集群
Kafka是一个MQ服务,流行的MQ服务器有三个,分别是ActiveMQ,RabbbitMQ和Kafka 目录说明:/home/fuqinqin/packages : 安装包存放目录/home/fuq ...
- 利用vmware搭建分布式集群
背景: 我们需要至少3台服务器来实现分布式,鉴于没那么多钱买真机器,从学习和开发的角度看,只有虚拟机一条路了. 软件选择: 虚拟机使用VMware软件,因为主流而且资料比较多,学习成 ...
- Windows 环境搭建Redis集群
环境以及引用资料 1.windows server 2008 r2 enterprise (木有办法,公司的服务器全是如此,就这种环境搭建吧) 2.redis官方资料下载: https://redi ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
随机推荐
- appium定位
一.链接基本信息 二.在appium界面中 三,定位 三.通过ui automator viewer抓取手机页面元素,点击红框按钮会抓取当前手机界面app全部元素;路径在sdk>tools下面的 ...
- jenkins安装配置
一.下载Jenkins 官网地址:https://jenkins.io/,图如下所示,点击下载可下载最新版本. 点击下载之后,我们可以看到下面的图,我这边选择的Jenkins.war 文件. 下面,使 ...
- Vue(三十二)SSR服务端渲染Nuxt.js
初始化Nuxt.js项目步骤 1.使用脚手架工具 create-nuxt-app 创建Nuxt项目 使用yarn或者npm $ yarn create nuxt-app <项目名> 注:根 ...
- JS DOM事件学习
DOM查找方法: document.getElementByID("id") document.getElementsByTagName("tag") 返回一个 ...
- Android系统架构及内核简介
(来源于ThinkPHP) Android是Google公司开发的基于Linux平台的开源手机操作系统,它包括操作系统.中间件.用户界面和应用程序,而且不存在任何以往阻碍移 动产业创新的专利权障碍,并 ...
- SpringMVC的配置和使用
SpringMVC的配置和使用 什么是SpringMVC? SpringMVC是Spring家族的一员,Spring是将现在开发中流行的组件进行组合而成的一个框架!它用在基于MVC的表现层开发,类似于 ...
- Ubuntu 16.04下sublime text3安装
安装方法 在确保Ubuntu更新了国内镜像源的前提下,使用ppa安装: sudo add-apt-repository ppa:webupd8team/sublime-text-3 sudo apt- ...
- Hadoop 操作常见问题解决
1. 安全模式下不可操作 提示信息: Hadoop "Cannot create directory .Name node is in safe mode." 解决方法: $ ha ...
- [Swift]LeetCode309. 最佳买卖股票时机含冷冻期 | Best Time to Buy and Sell Stock with Cooldown
Say you have an array for which the ith element is the price of a given stock on day i. Design an al ...
- [Swift]LeetCode319. 灯泡开关 | Bulb Switcher
There are n bulbs that are initially off. You first turn on all the bulbs. Then, you turn off every ...