Storm环境搭建(分布式集群)
作为流计算的开篇,笔者首先给出storm的安装和部署,storm的第二篇,笔者将详细的介绍storm的工作原理。下边直接上干货,跟笔者的步伐一块儿安装storm。
原文链接:Storm环境搭建(分布式集群)
Step1:新建用户
在所有主机上新建hadoop用户,密码是Hadoop123
useradd hadoop
passwd hadoop
输入密码Hadoop123
Step2:设置免密登录
设置所有主机之间ssh免密码登录。设置主节点到从节点的免密码登录即可。
Step3:软件包下载
(1)mkdir -p /mnt/data/software
(2)将所需要的软件包放在/mnt/data/software目录下
如需要以下三个安装包,请长按文末二维码关注“大数据技术宅”,后台输入“storm安装包”获取。
jdk-8u121-linux-i586.tar.gz
apache-storm-1.0.5.tar.gz
zookeeper-3.4.10.tar.gzStep4:安装JDK
(1)卸载openjdk
rpm -qa | grep jdk
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodepscopy-jdk-configs-1.2-1.el7.noarch
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
(2)安装jdk1.8
cd /mnt/data/software
tar -zxvf jdk-8u121-linux-i586.tar.gz
配置java环境变量
vim /etc/profile在文件中写入以下内容
JAVA_HOME=/mnt/data/software/jdk1.8.0_121
JRE_HOME=/mnt/data/software/jdk1.8.0_121/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
使环境变量生效:source/etc/profile
Step5:安装zookeeper
(1)关闭三台机器上的防火墙(CentOS 7)
firewall-cmd --state 查看防火墙状态
systemctl stop firewalld.service 关闭防火墙
systemctl disable firewalld.service 禁止开机启动(2)安装
cd /mnt/data/software
tar -zxvf zookeeper-3.4.10.tar.gz
mv zookeeper-3.4.10
cd zookeeper/conf
将conf目录中的zoo_sample.cfg文件复制为zoo.cfg并利用vi命令进行修改
dataDir=/mnt/data/software/zookeeper/data
server.1=ip:2888:3888 ip为服务器的ip
server.2=ip:2888:3888 ip为服务器的ip
server.3=ip:2888:3888 ip为服务器的ip
这里的dataDir需要自己创建 mkdir命令创建,并在目录下创建一个文件:myid分别在myid上按照配置文件的server.<id>中id的数值,在不同机器上的该文件中填写相应过的值1|2|3
如[root@safe01data]# vim myid
1
保存即可
(3)添加zookeeper环境变量
vim /etc/profile
ZOOKEEPER_HOME=/mnt/data/software/zookeeper
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin
export JAVA_HOME CLASSPATH ZOOKEEPER_HOME PATH
引用环境变量:source/etc/profile
(4)测试安装
三台机器执行zkServer.shstart进行启动zookeeper
查看状态zkServer.shstatus
[root@safe01 data]# zkServer.sh status
JMX enabled by default
Using config: /mnt/data/software/zookeeper/bin/../conf/zoo.cfg
Mode: follower
两个follower一个leader就是正确的
Step6:安装Storm
(1)安装
cd /mnt/data/software
tar -zxvf apache-storm-1.0.5.tar.gz
mv apache-storm-1.0.5 storm
cd ./storm/conf
编辑storm.yaml
storm.zookeeper.servers:
- "172.16.2.27"
- "172.16.2.42"
- "172.16.2.72"
#nimbus
nimbus.host: "172.16.2.27"
ui.port: 8081
supervisor.slots.ports:
-6700
-6701
-6702
-6703
storm.local.dir:"/mnt/data/software/storm/data"
创建数据文件目录:mkdir /mnt/data/software/storm/data
将storm分发到其他主机上:
scp -r /mnt/data/software/storm/ hadoop@172.16.2.42:/mnt/data/software
scp -r /mnt/data/software/storm/ hadoop@172.16.2.72:/mnt/data/software
在所有主机上添加storm的环境变量:
STORM_HOME=/mnt/data/software/storm
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$STORM_HOME/bin:$KAFKA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH ZOOKEEPER_HOME STORM_HOME KAFKA_HOME PATH
(2)启动
在主机centos上开启nimbus进程
storm nimbus &
在另外两台机子上开启supervisor 进程
storm supervisor &
开启完按Ctrl+c
在centos主机上开启
storm ui &
storm logviewer &
这样就可以通过web查看storm部署情况了
访问http://172.16.2.27:8080/,如图:
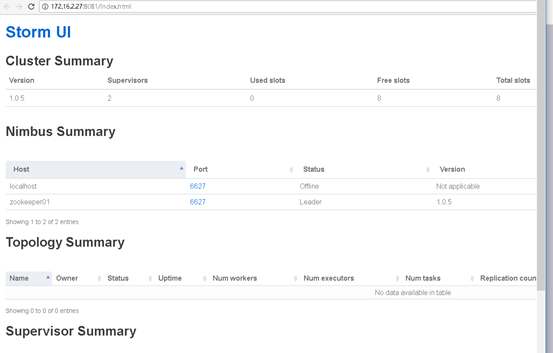
下篇。。。
Storm环境搭建(分布式集群)的更多相关文章
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境 一.环境说明 个人理解:zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hadoo ...
- Windows及Linux环境搭建Redis集群
一.Windows环境搭建Redis集群 参考资料:Windows 环境搭建Redis集群 二.Linux环境搭建Redis集群 参考资料:Redis Cluster的搭建与部署,实现redis的分布 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- 环境搭建-CentOS集群搭建
环境搭建-CentOS集群搭建 写在前面 最近有许多小伙伴问我,大数据的hadoop分布式集群该如何去搭建.所以,想着,就写一篇博客,帮助到更多刚入门大数据的人.本博客会一步一步带你实现一个Hadoo ...
- Redis.之.环境搭建(集群)
Redis.之.环境搭建(集群) 现有环境: /u01/app/ |- redis # 单机版 |- redis-3.2.12 # redis源件 所需软件:redis-3.0.0.gem -- ...
- Windows 环境搭建Redis集群(win 64位)
转: http://blog.csdn.net/zsg88/article/details/73715947 参考:https://www.cnblogs.com/tommy-huang/p/6240 ...
- CentOS 7 环境搭建kafka集群
Kafka是一个MQ服务,流行的MQ服务器有三个,分别是ActiveMQ,RabbbitMQ和Kafka 目录说明:/home/fuqinqin/packages : 安装包存放目录/home/fuq ...
- 利用vmware搭建分布式集群
背景: 我们需要至少3台服务器来实现分布式,鉴于没那么多钱买真机器,从学习和开发的角度看,只有虚拟机一条路了. 软件选择: 虚拟机使用VMware软件,因为主流而且资料比较多,学习成 ...
- Windows 环境搭建Redis集群
环境以及引用资料 1.windows server 2008 r2 enterprise (木有办法,公司的服务器全是如此,就这种环境搭建吧) 2.redis官方资料下载: https://redi ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
随机推荐
- 创建多线程的方式:继承Thread类和实现Runnable接口
1.通过继承Thread类的方式创建多线程(这里只是简单的代码演示创建多线程的方法) package com.baozi.exer; public class ThreadDemo { public ...
- Visual Studio2012 添加服务引用时,生成基于任务操作不可用原因
今天在添加服务引用时,发现 单选按钮 ”生成基于任务操作“不可用,原因项目选择的.net frame是3.5,调整为.net 4.5或.net4.6即可. 原因:.net4.5以下的环境不支持.
- [LeetCode] Mirror Reflection 镜面反射
There is a special square room with mirrors on each of the four walls. Except for the southwest cor ...
- ubuntu显卡驱动安装
1.确定显卡型号 网上有些使用lspci | grep -i nvidia可以查看显卡型号,但是我的好像查不到具体型号,如下图. 但是后来我知道了安装的是1080Ti,所以也就明确了型号.驱动在(ht ...
- python多版本管理工具(pyenv)
在学习和利用python开发的很多情况下,需要多版本的Python并存.此时需要在系统中安装多个Python,但又不能影响系统自带的 Python.pyenv 就是这样一个 Python 版本管理器. ...
- VS 2013+ ArcGIS 10.3 AddIn 断点不断异常解决
1. http://resources.arcgis.com/en/help/arcobjects-net/conceptualhelp/index.html#/How_to_debug_add_in ...
- Android Studio 去除上方标题
选中代码再Ctrl+shift+'/' 可加/***/注释 https://blog.csdn.net/wuqingsen1/article/details/78554117 styles.xml & ...
- 微信小程序学习笔记(三)
一般setData方法多用于点击后改变页面信息或者刷新后与后台交互获取最新的信息 注意: 直接修改 this.data 而不调用 this.setData 是无法改变页面的状态的,还会造成数据不一致 ...
- IIS中 flv、swf 文件无法播放
解决方案: 1.服务器安装flash,这是必须的. 2.MIME类型添加两个:名称.swf,值application/x-shockwave-flash:名称.flv,值flv-application ...
- Android 音视频开发(七): 音视频录制流程总结
在前面我们学习和使用了AudioRecord.AudioTrack.Camera.MediaExtractor.MediaMuxer API.MediaCodec. 学习和使用了上述的API之后,相信 ...