【Spark篇】---Spark解决数据倾斜问题
一、前述
数据倾斜问题是大数据中的头号问题,所以解决数据清洗尤为重要,本文只针对几个常见的应用场景做些分析 。
二。具体方法
1、使用Hive ETL预处理数据
方案适用场景:
如果导致数据倾斜的是Hive表。如果该Hive表中的数据本身很不均匀(比如某个key对应了100万数据,其他key才对应了10条数据),而且业务场景需要频繁使用Spark对Hive表执行某个分析操作,那么比较适合使用这种技术方案。
方案实现思路:
此时可以评估一下,是否可以通过Hive来进行数据预处理(即通过Hive ETL预先对数据按照key进行聚合,或者是预先和其他表进行join),然后在Spark作业中针对的数据源就不是原来的Hive表了,而是预处理后的Hive表。此时由于数据已经预先进行过聚合或join操作了,那么在Spark作业中也就不需要使用原先的shuffle类算子执行这类操作了。
方案实现原理:
这种方案从根源上解决了数据倾斜,因为彻底避免了在Spark中执行shuffle类算子,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以Hive ETL中进行group by或者join等shuffle操作时,还是会出现数据倾斜,导致Hive ETL的速度很慢。我们只是把数据倾斜的发生提前到了Hive ETL中,避免Spark程序发生数据倾斜而已。
2、过滤少数导致倾斜的key
方案适用场景:
如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
方案实现思路:
如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
方案实现原理:
将导致数据倾斜的key给过滤掉之后,这些key就不会参与计算了,自然不可能产生数据倾斜。
3、提高shuffle操作的并行度
方案实现思路:
在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量。对于Spark SQL中的shuffle类语句,比如group by、join等,需要设置一个参数,即spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,该值默认是200,对于很多场景来说都有点过小。
方案实现原理:
增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个不同的key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了。
4、双重聚合
方案适用场景:
对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案。
方案实现思路:
这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
方案实现原理:
将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。如果一个RDD中有一个key导致数据倾斜,同时还有其他的key,那么一般先对数据集进行抽样,然后找出倾斜的key,再使用filter对原始的RDD进行分离为两个RDD,一个是由倾斜的key组成的RDD1,一个是由其他的key组成的RDD2,那么对于RDD1可以使用加随机前缀进行多分区多task计算,对于另一个RDD2正常聚合计算,最后将结果再合并起来。
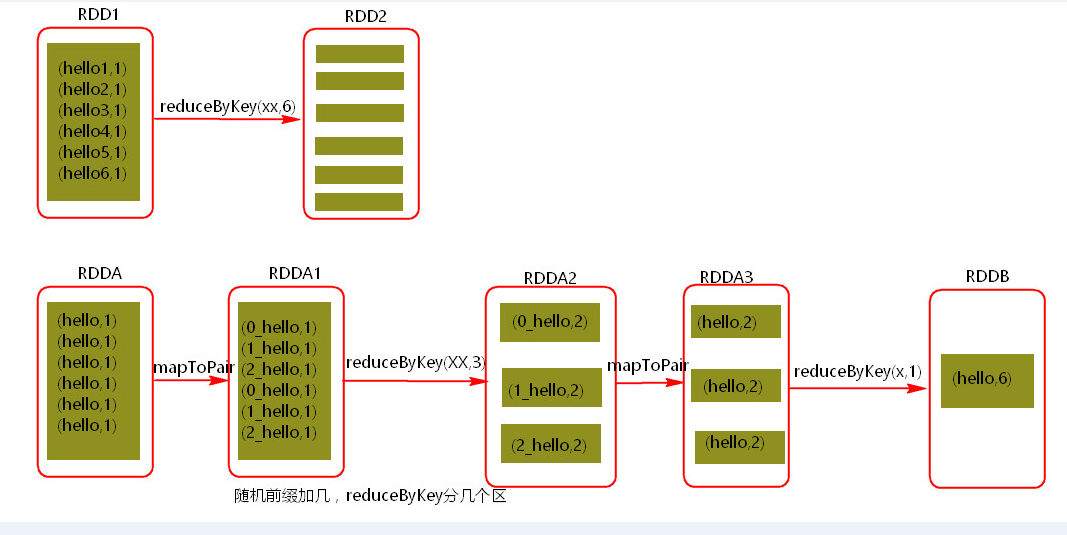
随机前缀加几,ReduceByKey分几个区。
5、将reduce join转为map join(彻底避免数据倾斜)
BroadCast+filter(或者map)
方案适用场景:
在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
方案实现思路:
不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
方案实现原理:
普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。
6、采样倾斜key并分拆join操作
方案适用场景:
两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:
对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。而另外两个普通的RDD就照常join即可。最后将两次join的结果使用union算子合并起来即可,就是最终的join结果 。
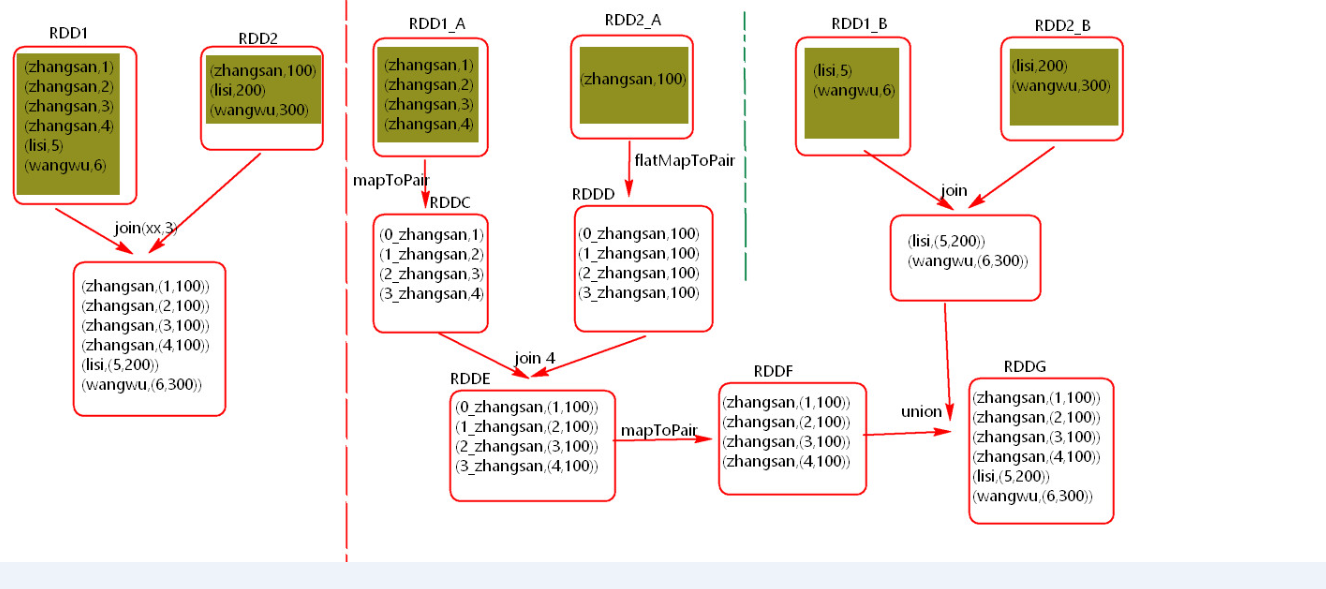
7、使用随机前缀和扩容RDD进行join
方案适用场景:
如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义,此时就只能使用最后一种方案来解决问题了。
方案实现思路:
该方案的实现思路基本和“解决方案六”类似,首先查看RDD/Hive表中的数据分布情况,找到那个造成数据倾斜的RDD/Hive表,比如有多个key都对应了超过1万条数据。然后将该RDD的每条数据都打上一个n以内的随机前缀。同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。最后将两个处理后的RDD进行join即可。
【Spark篇】---Spark解决数据倾斜问题的更多相关文章
- Spark性能调优之解决数据倾斜
Spark性能调优之解决数据倾斜 数据倾斜七种解决方案 shuffle的过程最容易引起数据倾斜 1.使用Hive ETL预处理数据 • 方案适用场景:如果导致数据倾斜的是Hive表.如果该Hiv ...
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark 调优之数据倾斜
什么是数据倾斜? Spark 的计算抽象如下 数据倾斜指的是:并行处理的数据集中,某一部分(如 Spark 或 Kafka 的一个 Partition)的数据显著多于其它部分,从而使得该部分的处理速度 ...
- [MapReduce_add_3] MapReduce 通过分区解决数据倾斜
0. 说明 数据倾斜及解决方法的介绍与代码实现 1. 介绍 [1.1 数据倾斜的含义] 大量数据发送到同一个节点进行处理,造成此节点繁忙甚至瘫痪,而其他节点资源空闲 [1.2 解决数据倾斜的方式] 重 ...
- Hadoop_22_MapReduce map端join实现方式解决数据倾斜(DistributedCache)
1.Map端Join解决数据倾斜 1.Mapreduce中会将map输出的kv对,按照相同key分组(调用getPartition),然后分发给不同的reducetask 2.Map输出结果的时候 ...
- 解决spark中遇到的数据倾斜问题
一. 数据倾斜的现象 多数task执行速度较快,少数task执行时间非常长,或者等待很长时间后提示你内存不足,执行失败. 二. 数据倾斜的原因 常见于各种shuffle操作,例如reduceByKey ...
- 【Spark调优】数据倾斜及排查
[数据倾斜及调优概述] 大数据分布式计算中一个常见的棘手问题——数据倾斜: 在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或j ...
- spark复习笔记(6):数据倾斜
一.数据倾斜 spark数据倾斜,map阶段对key进行重新划分.大量的数据在经过hash计算之后,进入到相同的分区中,zao
- 专访周金可:我们更倾向于Greenplum来解决数据倾斜的问题
周金可,就职于听云,维护MySQL和GreenPlum的正常运行,以及调研适合听云业务场景的数据库技术方案. 听云周金可 9月24日,周金可将参加在北京举办的线下活动,并做主题为<GreenPl ...
随机推荐
- [linux]使用curl进行GET、POST和网页调试
以前在win下开发的时候,习惯用的调试工具是谷歌自带控制台和postman,谷歌控制台比较方便,但不能对请求进行重发,post虽然很好用,但是感觉还是有点'大'.在linux下,其实完全没有那么麻烦, ...
- RESTful-4使用教程
一.REST起源REST(Representational State Transfer)表象化状态转变(表述性状态转变),在2000年被提出,基于HTTP.URI.XML.JSON等标准和协议,支持 ...
- java 模拟浏览器爬虫
- Android进阶:一、日志打印和保存策略
前言: 项目开始没有做好日志统计工作,每次有问题后端都得找前端对接,严重影响工作效率.最近特地在项目中加上日志保存策略,在此分享,供需要的人学习. 一.更详细的日志信息 既然决定自定义一个log,那我 ...
- windows与linux多线程对比
一.创建线程 1>windows HANDLE aThread[MAX_THREAD]; 函数原型: HANDLE WINAPI CreateThread( _In_opt_ LPSECUR ...
- 2018-2019 ICPC, NEERC, Southern Subregional Contest
目录 2018-2019 ICPC, NEERC, Southern Subregional Contest (Codeforces 1070) A.Find a Number(BFS) C.Clou ...
- 多项式与三角函数求导——BUAA OO 第一单元作业总结
第一次作业 需求简要说明 针对符合规定的多项式表达式输出其符合格式规定的导函数多项式,格式错误输出WRONG FORMAT! 带符号整数 支持前导0的带符号整数,符号可省略,如: +02.-16> ...
- 完整版本的推箱子小游戏,最简单的纯C语言打造
/* 推箱子小游戏 1.定义绘制样式 用二维数组的方式 2.绘制图像 3.找出当前位置 4.逻辑判断,制造动作 根据数学xy轴的规律,这里使用ij 上移,行轴上升,行数减少 下移,行数下降,函数增加 ...
- windows server 远程桌面连接问题。
远程桌面连接相当于 linux 服务器root权限连接 mstsc /admin /v:目标IP mstsc /admin /
- Windows10用fiddler抓包Android应用(解决手机设置代理后无法上网,设置只抓app包)
1.环境准备 1.电脑上安装fiddler 2.手机和电脑在同一个局域网内 2.设置 1.fiddler>Tools>Fiddler Options>Connections 勾选Al ...