Database | 浅谈Query Optimization (2)
为什么选择左深连接树
对于n个表的连接,数量为卡特兰数,近似\(4^n\),因此为了减少枚举空间,早期的优化器仅考虑左深连接树,将数量减少为\(n!\)
但为什么是左深连接树,而不是其他样式呢?
如果join算法为index join或者hash join,当两张表进行连接的时候,需要为左表建立哈希映射或者搜索索引,连接时直接寻找对应的元素:
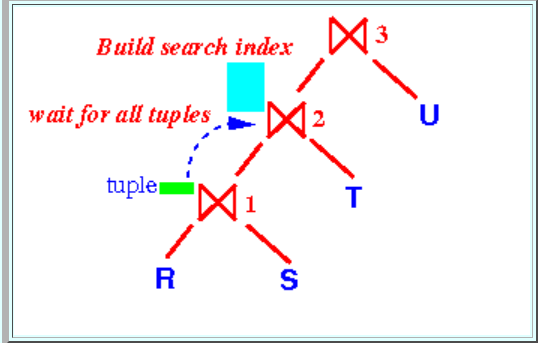
join ⋈2 必须等到⋈1 的全部元组输出之后才能生成它的映射表/索引。即只有⋈1 结束后,⋈2才能开始输出元组。而此时⋈3必须等待,直到⋈2完成。
对于多个表的连接,当⋈i正在执行时,⋈i+1处于半活跃的状态,它累积⋈i的输出到缓冲区并建立映射,而后面的⋈i+2到⋈n均处于空闲状态。
当执行连接⋈1时,需要为⋈1中的表分配内存,然后将输出的元组同样储存在内存中。而如前所述,只有⋈1结束时⋈2才能开始,因此⋈1结束时可以直接释放掉之前占用的内存空间。
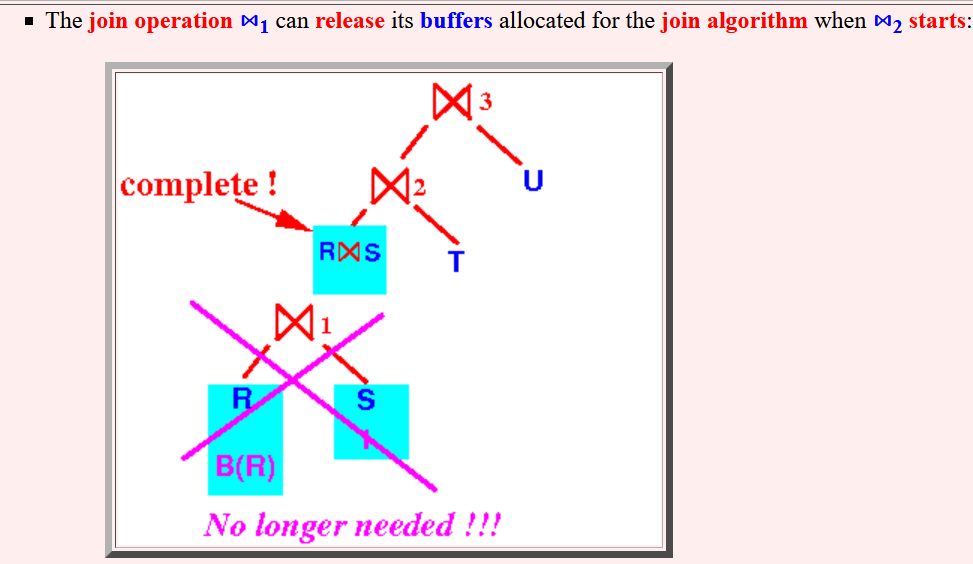
而对于其他形式的树,例如右深连接树,因为左侧的操作数都是一个关系,所有的join连接符都可以为左表建立映射表/索引,会占用大量的内存空间。
因此对于Hash Join,采用左深连接树可以减少执行计划对内存的需求。
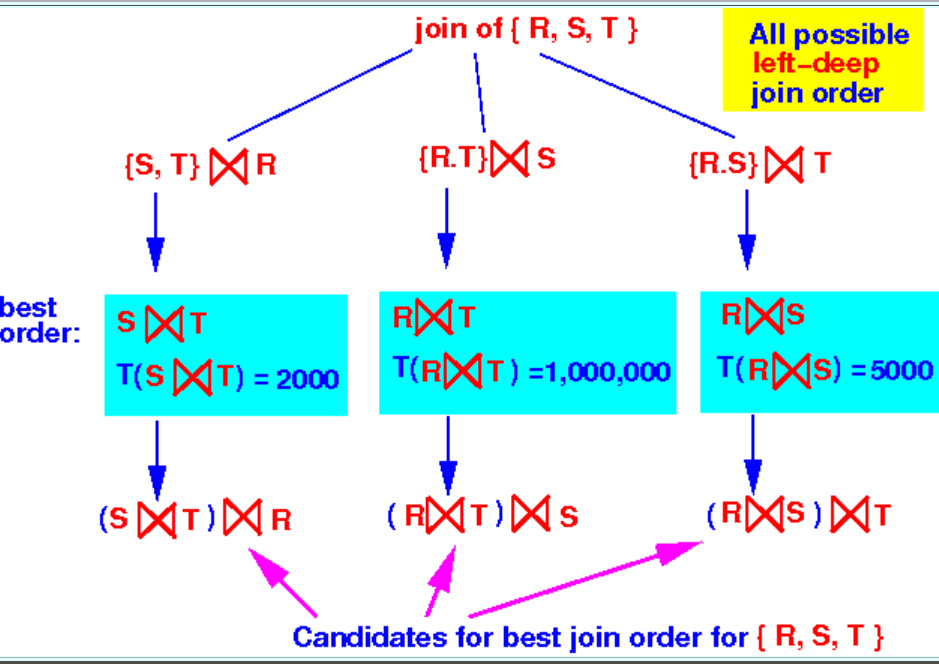
当join算法为nested-loop join时,如果采用右深连接树,结果会更糟糕:
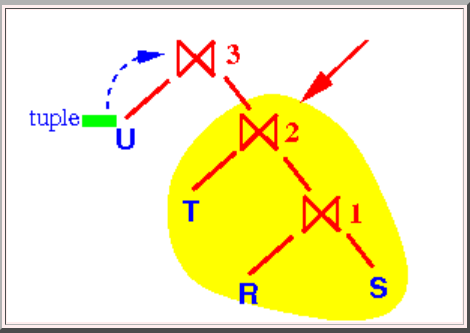
如图,执行⋈3时会导致多次访问⋈3的第二个操作数,使得该子查询多次执行,会多次访问表T、R、S增加读取磁盘的次数。
寻找最佳连接顺序
最佳的连接顺序即是中间结果中产生最少元组数量的连接顺序
因为不同的连接顺序都会访问每个表一次,而表连接的中间结果往往需要写入磁盘中暂时储存,因此中间结果元组数量越少,读取磁盘次数越少。
因此我们定义 cost for join 即是指连接后产生的中间结果的个数。
而不去连接怎么知道中间结果的个数呢?那就需要用到上一篇博客中提到的谓词的选择性和数据直方图,估算连接后产生的元组个数。
对于三个关系的连接,需要维护如下的数据图:
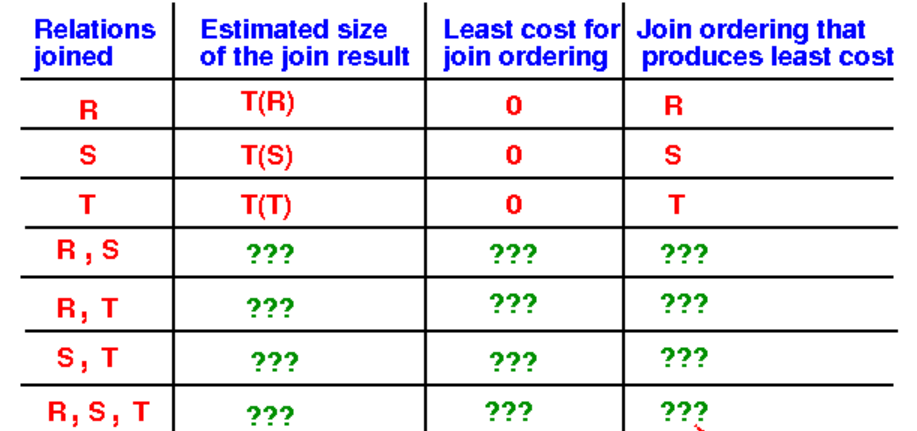
首先是相互连接关系的列表,然后是连接后的元组总数和连接的cost,以及这几个关系的最佳连接顺序。
然后对给定的n个表,将其分解成n个n-1的表的连接,再逐层分解,先求得两个关系的最佳连接方式。最优解即是这些子问题的组合。
算法的伪代码如下:
j = set of join nodes
for (i in 1...|j|): //一开始寻找单个join的最佳方案,再向上延伸
for s in {all length i subsets of j} //寻找s的最优连接
bestPlan = {}
//i-1的最优解都已经储存在optjoin中
//只需要考虑再加一个表的情况
for ss in {all length i-1 subsets of s}
subplan = optjoin(ss)
//optjoin 可以理解为一个哈希表,储存对应ss的最优连接
plan = best way to join (s-ss) to subplan
if (cost(plan) < cost(bestPlan))
bestPlan = plan
optjoin(s) = bestPlan
return optjoin(j)
具体而言,假设现在是R、S、T、U四个关系相连接,我们已经得出两个关系的最优解如下图所示:
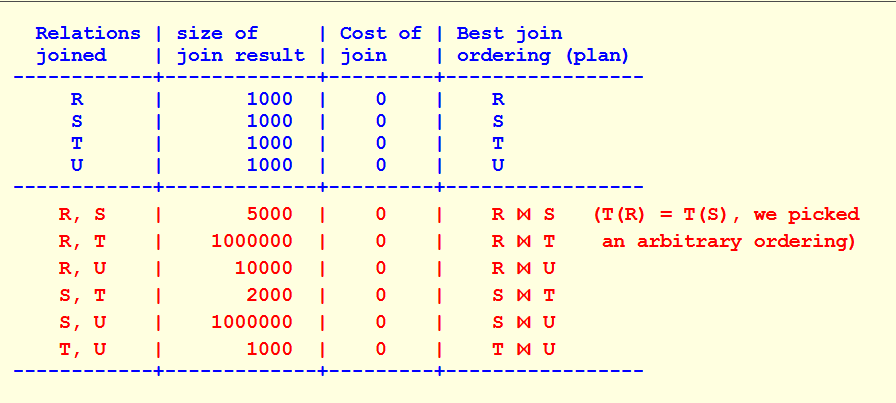
那么假设现在有
i=3, s=R,S,T
//那么对于ss
ss=R,S or R,T or S,T
计算出三种s的cost,找出bestplan,则
optjoin(R,S,T) = bestplan
我们先不考虑谓词选择性,直接将生成的元组个数作为cost,那么
因为 T(S ⋈ T) = 2000, 因此 {S, T} ⋈ R 即为 s=R, S, T 的最优顺序。
将length(s)=3的四种情况依次计算,再求得四个关系相连接的最优顺序。
动态规划算法的缺点
- 缺乏扩展性:当需要加入新的join方法时,需要修改大量代码。如果增加新的operator,比如aggregation,那么修改就更加困难。
- 对Join顺序优化的问题非常适合,但是却不容易适用其他的优化方法,比如对GroupBy或者Union的优化。
动态规划的主要意义还是寻找次优的连接顺序,并且其搜索空间依然很大,需要\(O(n*2^{n-1})\),当表的数量为两位数时依然需要较长时间来响应。
参考
Database | 浅谈Query Optimization (2)的更多相关文章
- Database | 浅谈Query Optimization (1)
综述 由于SQL是声明式语言(declarative),用户只告诉了DBMS想要获取什么,但没有指出如何计算.因此,DBMS需要将SQL语句转换成可执行的查询计划(Query Plan).但是对同样的 ...
- 手撸ORM浅谈ORM框架之Query篇
快速传送 手撸ORM浅谈ORM框架之基础篇 手撸ORM浅谈ORM框架之Add篇 手撸ORM浅谈ORM框架之Update篇 手撸ORM浅谈ORM框架之Delete篇 手撸ORM浅谈ORM框架之Query ...
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
- 浅谈php生成静态页面
一.引 言 在速度上,静态页面要比动态页面的比方php快很多,这是毫无疑问的,但是由于静态页面的灵活性较差,如果不借助数据库或其他的设备保存相关信息的话,整体的管理上比较繁琐,比方修改编辑.比方阅读权 ...
- 浅谈一下SSI+Oracle框架的整合搭建
浅谈一下SSI+Oracle框架的整合搭建 最近换了一家公司,公司几乎所有的项目都采用的是Struts2+Spring+Ibatis+Oracle的架构,上一个东家一般用的就是JSF+Spring,所 ...
- MYSQL优化浅谈,工具及优化点介绍,mysqldumpslow,pt-query-digest,explain等
MYSQL优化浅谈 msyql是开发常用的关系型数据库,快速.稳定.开源等优点就不说了. 个人认为,项目上线,标志着一个项目真正的开始.从运维,到反馈,到再分析,再版本迭代,再优化… 这是一个漫长且考 ...
- 【转】.NET(C#):浅谈程序集清单资源和RESX资源 关于单元测试的思考--Asp.Net Core单元测试最佳实践 封装自己的dapper lambda扩展-设计篇 编写自己的dapper lambda扩展-使用篇 正确理解CAP定理 Quartz.NET的使用(附源码) 整理自己的.net工具库 GC的前世与今生 Visual Studio Package 插件开发之自动生
[转].NET(C#):浅谈程序集清单资源和RESX资源 目录 程序集清单资源 RESX资源文件 使用ResourceReader和ResourceSet解析二进制资源文件 使用ResourceM ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 手撸ORM浅谈ORM框架之基础篇
好奇害死猫 一直觉得ORM框架好用.功能强大集众多优点于一身,当然ORM并非完美无缺,任何事物优缺点并存!我曾一度认为以为使用了ORM框架根本不需要关注Sql语句如何执行的,更不用关心优化的问题!!! ...
随机推荐
- 【.NET 与树莓派】控制舵机
不管是小马达,还是大马达,嗯,也就是电机,相信大伙伴们也不会陌生.四驱车是一种很优秀的玩具,从老周小时候就开始流行(动画片<四驱兄弟>估计很多大朋友都看过),直到现在还能看到很多卖四驱车的 ...
- GET和POST两者的区别
GET 和 POST 是 HTTP 协议中的两种发送请求的基本方法,对于前端开发者而言,几乎每天都在使用它们,再熟悉不过了,一般也都能说出几点两者的区别. 如果面试中被问到这个问题,先回答一下几点,肯 ...
- Oracle数据库的函数
一.字符函数upper和lower (1).upper和lower upper把小写的字符转换成大小的字符 ,lower把大写字符变成小写字符 . select upper('yes') from d ...
- Java 8 中Sort排序原理:
总的来说,java中Arrays.sort使用了两种排序方法,快速排序和优化的合并排序.Collections.sort方法底层就是调用的Arrays.sort方法. 快速排序主要是对那些基本类型数据 ...
- Linux磁盘分区格式化和扩容
Note:根据各系统上磁盘的类型不同,磁盘命名规则也会不同:例如/dev/xvd,/dev/sd,/dev/vd,/dev/hd 目录 磁盘格式化 MBR格式 GPT分区 磁盘扩容 MBR格式扩容 G ...
- MySQL深入研究--学习总结(1)
前言 本文是笔者学习"林晓斌"老师的<MySQL实战45讲>过程中的,对知识点的总结归纳以及对问题的思考记录,课程18年11月就出了,当时连载形式,我就上班途中一边开车 ...
- 网络地址转换NAT的两种模式(概念浅析)& IP溯源
由于全球IPv4地址越来越少.越来越贵,因此大到一个组织,小到一个家庭一个人都很难获得公网IP地址,所以只能使用内网地址,从而和别人共享一个公网IP地址.在这种情况下,NAT技术诞生. 翻译 NAT( ...
- C语言之结构体内存的对齐
C语言之结构体内存的对齐 大纲: 零.引例 一.结构体内存对齐规则 二.怎样计算结构体的大小 三.设计结构体时要注意的方面 四.为什么存在内存对齐 五.修改默认对齐数 在前面的章节中,我们谈到了C ...
- 【RocketMQ源码分析】深入消息存储(1)
最近在学习RocketMQ相关的东西,在学习之余沉淀几篇笔记. RocketMQ有很多值得关注的设计点,消息发送.消息消费.路由中心NameServer.消息过滤.消息存储.主从同步.事务消息等等. ...
- rest framework Views
基于类的意见 Django的基于类的意见是从旧式的观点颇受欢迎. - Reinout面包车里斯 REST框架提供了一个APIView类,它的子类Django的View类. APIView类是从正规不同 ...