MapReduce之MapJoin案例
@
使用场景
Map Join 适用于一张表十分小、一张表很大的场景。
优点
思考:在Reduce 端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map 端业务,减少Reduce 端数据的压力,尽可能的减少数据倾斜。
具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在驱动函数中加载缓存。
/缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file://e:/cache/pd.txt");
案例
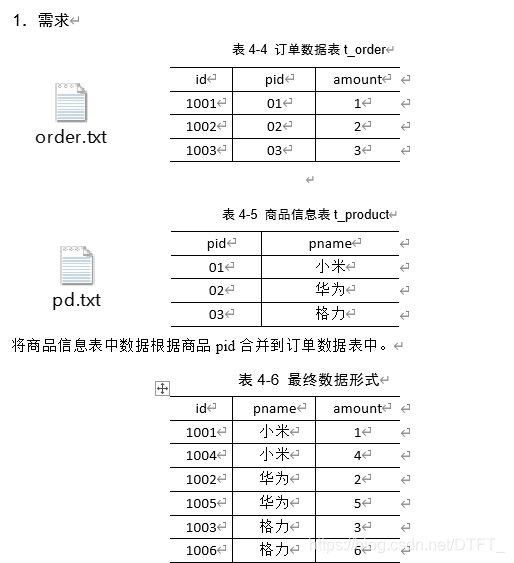
每个MapTask在map()中完成Join
注意:
- 只需要将要Join的数据order.txt作为切片,让MapTask读取
- pd.txt不以切片形式读入,而直接在MapTask中使用HDFS下载此文件,下载后,使用输入流手动读取其中的数据
- 在map()之前通常是将大文件以切片形式读取,小文件手动读取!
order.txt---->切片(orderId,pid,amount)----JoinMapper.map()
pd.txt----->切片(pid,pname)----JoinMapper.map()
需求分析
MapJoin适用于关联表中有小表的情形
代码实现
JoinBean.java
public class JoinBean {
private String orderId;
private String pid;
private String pname;
private String amount;
@Override
public String toString() {
return orderId + "\t" + pname + "\t" + amount ;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
public String getAmount() {
return amount;
}
public void setAmount(String amount) {
this.amount = amount;
}
}
MapJoinMapper.java
/*
* 1. 在Hadoop中,hadoop为MR提供了分布式缓存
* ①用来缓存一些Job运行期间的需要的文件(普通文件,jar,归档文件(har))
* ②通过在Job的Configuration中,使用uri代替要缓存的文件
* ③分布式缓存会假设当前的文件已经上传到了HDFS,并且在集群的任意一台机器都可以访问到这个URI所代表的文件
* ④分布式缓存会在每个节点的task运行之前,提前将文件发送到节点
* ⑤分布式缓存的高效是由于每个Job只会复制一次文件,且可以自动在从节点对归档文件解归档
*
*
*
*
*/
public class MapJoinMapper extends Mapper<LongWritable, Text, JoinBean, NullWritable>{
private JoinBean out_key=new JoinBean();
private Map<String, String> pdDatas=new HashMap<String, String>();
//在map之前手动读取pd.txt中的内容
@Override
protected void setup(Mapper<LongWritable, Text, JoinBean, NullWritable>.Context context)
throws IOException, InterruptedException {
//从分布式缓存中读取数据
URI[] files = context.getCacheFiles();
for (URI uri : files) {
BufferedReader reader = new BufferedReader(new FileReader(new File(uri)));
String line="";
//循环读取pd.txt中的每一行
while(StringUtils.isNotBlank(line=reader.readLine())) {
String[] words = line.split("\t");
pdDatas.put(words[0], words[1]);
}
reader.close();
}
}
//对切片中order.txt的数据进行join,输出
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, JoinBean, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
out_key.setOrderId(words[0]);
out_key.setPname(pdDatas.get(words[1]));
out_key.setAmount(words[2]);
context.write(out_key, NullWritable.get());
}
}
MapJoinDriver.java
public class MapJoinDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/mapjoin");
Path outputPath=new Path("e:/mroutput/mapjoin");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
job.setJarByClass(MapJoinDriver.class);
// 为Job创建一个名字
job.setJobName("wordcount");
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(MapJoinMapper.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置分布式缓存
job.addCacheFile(new URI("file:///e:/pd.txt"));
//取消reduce阶段
job.setNumReduceTasks(0);
// ③运行Job
job.waitForCompletion(true);
}
}
MapReduce之MapJoin案例的更多相关文章
- MapReduce 单词统计案例编程
MapReduce 单词统计案例编程 一.在Linux环境安装Eclipse软件 1. 解压tar包 下载安装包eclipse-jee-kepler-SR1-linux-gtk-x86_64.ta ...
- hadoop笔记之MapReduce的应用案例(利用MapReduce进行排序)
MapReduce的应用案例(利用MapReduce进行排序) MapReduce的应用案例(利用MapReduce进行排序) 思路: Reduce之后直接进行结果合并 具体样例: 程序名:Sort. ...
- hadoop笔记之MapReduce的应用案例(WordCount单词计数)
MapReduce的应用案例(WordCount单词计数) MapReduce的应用案例(WordCount单词计数) 1. WordCount单词计数 作用: 计算文件中出现每个单词的频数 输入结果 ...
- Hadoop MapReduce编程入门案例
Hadoop入门例程简介 一个.有些指令 (1)Hadoop新与旧API差异 新API倾向于使用虚拟课堂(象类),而不是接口.由于这更easy扩展. 比如,能够无需改动类的实现而在虚类中加入一个方法( ...
- MAPREDUCE的实战案例
reduce端join算法实现 1.需求: 订单数据表t_order: id date pid amount 1001 20150710 P0001 2 1002 20150710 P0001 3 1 ...
- Mapreduce 订单分组案例
程序执行流程如下: map()-->getPartition()分区--->write()(序列化,每一行都顺序执行这三个方法)--->readFields()---->com ...
- 【HBase】HBase与MapReduce的集成案例
目录 需求 步骤 一.创建maven工程,导入jar包 二.开发MapReduce程序 三.运行结果 HBase与MapReducer集成官方帮助文档:http://archive.cloudera. ...
- 使用MapReduce运行WordCount案例
@ 目录 一.准备数据 二.MR的编程规范 三.编程步骤 四.编写程序 Mapper程序解读 一.准备数据 注意:准备的数据的格式必须是文本,每个单词之间使用制表符分割.编码必须是utf-8无bom ...
- hadoop MapReduce运营商案例关于用户基站停留数据统计
注 如果需要文件和代码的话可评论区留言邮箱,我给你发源代码 本文来自博客园,作者:Arway,转载请注明原文链接:https://www.cnblogs.com/cenjw/p/hadoop-mapR ...
随机推荐
- Crontab定时启动Supervisor任务
1. Crontab介绍 crontab的语法规则格式: 代表意义 分钟 小时 日期 月份 周 命令 数字范围 0~59 0~23 1~31 1~12 0~7 需要执行的命令 周的数字为 0 或 7 ...
- DJANGO-天天生鲜项目从0到1-013-订单-支付宝支付
本项目基于B站UP主‘神奇的老黄’的教学视频‘天天生鲜Django项目’,视频讲的非常好,推荐新手观看学习 https://www.bilibili.com/video/BV1vt41147K8?p= ...
- leetcode题库练习_左旋转字符串
题目:左旋转字符串 字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部.请定义一个函数实现字符串左旋转操作的功能.比如,输入字符串"abcdefg"和数字2,该函数将返 ...
- 毫无基础的人入门Python,Python新手入门教程2
1.6 面向对象和内存分析086.面向对象和面向过程的区别_执行者思维_设计者思维087.对象的进化故事088.类的定义_类和对象的关系089.构造函数__init__090.实例属性_内存分析091 ...
- Eclipse创建Web项目后新建Servlet时报红叉错误 or 导入别人Web项目时报红叉错误 的解决办法
如图,出现类似红叉错误. 1.在项目名称上点击右键->Build Path->Configure Build Path 2.在弹出来的框中点击Add Library,如图 3.接下来选择U ...
- redis配置密码
一. 更改配置文件 找到requirepass这行, [soft@node5 redis-3.0.6]$ grep 'requirepass' redis.conf#requirepass fooba ...
- goroutine调度源码阅读笔记
以下为本人阅读goroutine调度源码随手记的笔记,现在还是一个个知识点的形式,暂时还没整理,先发到这里,一点点更新: 1). runq [256]guintptr P 的runable队列最大 ...
- Debug HashMap
目录 1,HashMap面试必问 2,Debug源码的心得体会 3,JDK 1.7 3.1 用debug分析一个元素是如何加入到HashMap中的[jdk1.7] 3.2 用debug分析HashMa ...
- PHP preg_last_error() 函数
preg_last_error 函数用于返回最后一个 PCRE 正则执行产生的错误代码.高佣联盟 www.cgewang.com 语法 int preg_last_error ( void ) 实例 ...
- PHP acos() 函数
实例 返回不同数的反余弦: <?phpecho(acos(0.64) . "<br>");echo(acos(-0.4) . "<br>&q ...