Redis 设计与实现 6:五大数据类型之字符串
前文 Redis 设计与实现 2:Redis 对象 说到,五大数据类型都会封装成 RedisObject。
typedef struct redisObject {
unsigned type:4; // 类型
unsigned encoding:4; // 编码
// ...
void *ptr; // 指向具体底层数据的指针
} robj;
不同数据类型的主要区别就是 type 和 encoding 属性的差异,同一种数据类型,有不同的编码。
一、编码类型
字符串的编码有raw、embstr、int三种。
raw用于长字符串。embstr用于短字符串。int用于整数类型。
定义在 server.h 中,这里只列出 string 类型的编码
#define OBJ_ENCODING_RAW 0
#define OBJ_ENCODING_INT 1
#define OBJ_ENCODING_EMBSTR 8
编码 1:raw
raw 编码主要用来保存长度超过 44 的字符串。其真实数据,由 sdshdr 结构来表示存储,外层还是由 redisObject 包装。
sdshdr 的结构在前文 Redis 设计与实现 3:字符串 SDS 中有讲到。
sdshdr 结构大致如下:
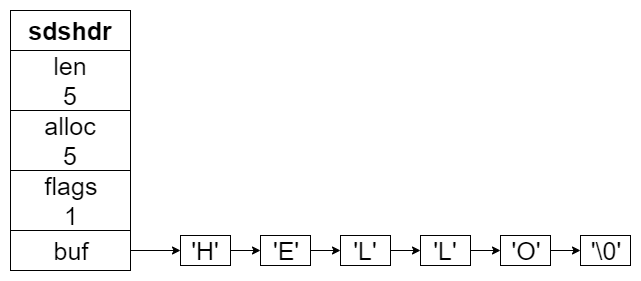
redisObject 中的 ptr 指针,就是指向 sds。

编码 2:embstr
embstr 编码是专门用于保存短字符串的一种优化编码方式。当字符串的长度小于等于 44 的时候,将采用 embstr 编码。
创建字符串对象的代码如下(object.c):
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
embstr 有个显著的特点,就是 redisObject 跟 sds 的内存是挨在一起的。挨在一起的好处:
- 分配内存的时候,只需要分配一次。而
raw编码的sds跟redisObject分离,就要分配两次内存。 - 同样,释放内存也只需要释放一次。
- 连续内存能更好利用内存带来的优势。
embstr 问题一:那么为什么 embstr 跟 raw 的界限是 44 呢?
embstr的sds使用了sdshdr8,sdshdr8头占用了 3 个字节:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 1 字节 */
uint8_t alloc; /* 1 字节 */
unsigned char flags; /* 1 字节 */
char buf[];
};
- 另外还有
redisObject占用 16 个字节 (4 + 4 + 24 + 32 + 64 = 128位):
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; // #define LRU_BITS 24
int refcount; // 32 位
void *ptr; // 64 位
} robj;
redisObject + sdshdr8 至少需要 3 + 16 = 19 字节。
redis 认为如果超过 64 字节就是大字符串,所以在 redisObject+ sdshdr8 的总长度是 64 字节的情况下,留给 buf 的长度就只剩下 45 字节,由于字符串结尾需要一个 \0 占用一个字节,所以留个字符串的长度就只有 44 字节了。
公式:64 - 3(sdshdr8 ) - 16(redisObject) - 1(\0) = 44
embstr 问题二:为什么网上有的博文说 embstr 跟 raw 的界限是 39
在 redis 3.2 版本之前,这个界限的确是 39,为什么后面改成 44 了呢?
那是因为 sdshdr 的结构在 3.2 版本的时候修改了。3.2 之前的 sdshdr 结构是:
struct sdshdr {
unsigned int len; // 4 字节
unsigned int free; // 4 字节
char buf[];
};
旧版本的 sdshdr 的头占用了 8 个字节,比新版本的多了 5 个字节,所以界限就是 44 - 5 = 39 啦!
编码 3:int
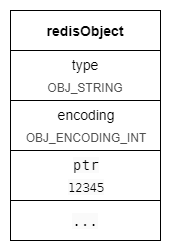
如果一个字符串对象保存的是整数值,并且这个整数值可以用 long 类型来表示,那么这个整数值将会保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long),并将字符串对象的编码设置为 int。
相对于用 raw 编码,int 编码既节省了指针占用的内存,也节省了sds结构的内存。
redis> SET int_key 12345
OK
redis> OBJECT ENCODING int_key
"int"
下图为存着 12345 的 string 示例结构:
二、编码的转换
1. int 转 raw
- 当字符串传的不是整数的时候,int 就会转成 raw 编码。
- 如果执行了一些修改的命令,如
append等(set不算),都会转成raw编码。因为这些操作只有字符串才支持。 - 一旦编码变为
raw之后,将不会再转成embstr
127.0.0.1:6379> SET num 1
OK
127.0.0.1:6379> OBJECT ENCODING num
"int"
127.0.0.1:6379> APPEND num 2
(integer) 2
127.0.0.1:6379> OBJECT ENCODING num
"raw"
127.0.0.1:6379> SET num 12
OK
127.0.0.1:6379> OBJECT ENCODING num
"int"
2. embstr 转 raw
- 如果执行了一些修改的命令,如
append等,都会转成raw编码,不管修改后字符串的长度。因为没有给embstr编码实现修改接口,所以实际上embsr是只读的。 - 一旦编码变为
raw之后,将不会再转成embstr
三、重点回顾
- 字符串对象有三种编码,
raw、embstr、int raw负责保存长字符串;embstr负责保存短字符串;int负责保存整数。int和embstr在修改的时候,会转成raw编码,并且不再转回
本文的分析没有特殊说明都是基于 Redis 6.0 版本源码
redis 6.0 源码:https://github.com/redis/redis/tree/6.0
Redis 设计与实现 6:五大数据类型之字符串的更多相关文章
- redis学习(七)——五大数据类型总结:字符串、散列、列表、集合和有序集合
目录 字符串类型(String) 散列类型(Hash) 列表类型(List) 集合类型(Set) 有序集合类型(SortedSet) 其它命令 一.字符串类型(String) 1.介绍: 字符串类型是 ...
- Redis设计与实现读书笔记——简单动态字符串
前言 项目里用到了redis数据结构,不想只是简单的调用api,这里对我的读书笔记做一下记录.原文地址: http://www.redisbook.com/en/latest/internal-dat ...
- 前端总结·基础篇·JS(一)五大数据类型之字符串(String)
前端总结系列 前端总结·基础篇·CSS(一)布局 前端总结·基础篇·CSS(二)视觉 前端总结·基础篇·CSS(二)补充 前端总结·基础篇·JS(一)五大数据类型之字符串(String) 目录 这是& ...
- 【笔记】《Redis设计与实现》chapter2 简单动态字符串
------------恢复内容开始------------ 2.1 SDS的定义 struct sdshdr{ // 记录buf数组中已使用字节的数量 // 等于SDS所保存字符串的长度(不含'\0 ...
- Redis详解(五)------ redis的五大数据类型实现原理
前面两篇博客,第一篇介绍了五大数据类型的基本用法,第二篇介绍了Redis底层的六种数据结构.在Redis中,并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这些对 ...
- Redis 详解 (五) redis的五大数据类型实现原理
目录 1.对象的类型与编码 ①.type属性 ②.encoding 属性和 *prt 指针 2.字符串对象 3.列表对象 4.哈希对象 5.集合对象 6.有序集合对象 7.五大数据类型的应用场景 8. ...
- redis五大数据类型以及常用操作命令
Redis的五大数据类型 String(字符串) string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value.string类型是二进制安全的.意 ...
- redis 五大数据类型使用
redis 五大数据类型使用 字符串str 单个值 127.0.0.1:6379> set name pp # 设置键值[O(1)] OK 127.0.0.1:6379> setex na ...
- redis的五大数据类型实现原理
1.对象的类型与编码 Redis使用前面说的五大数据类型来表示键和值,每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Redis中的每个对象都是由 redi ...
随机推荐
- 手撕HashMap
前言: 平时工作的时候,用的最多的就是ArrayList和HashMap了,今天看了遍HashMap的源码,决定自己手写一遍HashMap. 一.创建MyHashMap接口 我们首先创建一 ...
- volatile禁止重排使用场景与单例模式的Double Check Lock
普通单例模式Demo public class Demo{ private static Demo INSTANCE; private Demo(){} public static Demo getI ...
- gsap基础一[from,to,fromTo]
学了几天基础了,感觉总算有点入了一个门的感觉啦,gasp不难,想想一年前我看着官网跟天文一样,今年真的进步很大,在外网发现学习的新世界, 自己的获取知识和查看api源码的能力也增强了许多,现在国内的气 ...
- Python超全干货:【二叉树】基础知识大全
概念 二叉树是每个节点最多有两个子树的树结构.通常子树被称作"左子树"(left subtree)和"右子树"(right subtree) 二叉树的链式存储: ...
- EF Core 执行SQL语句和存储过程
无论ORM有多么强大,总会出现一些特殊的情况,它无法满足我们的要求.在这篇文章中,我们介绍几种执行SQL的方法. 表结构 在具体内容开始之前,我们先简单说明一下要使用的表结构. public clas ...
- 基于React.js网页版弹窗|react pc端自定义对话框组件RLayer
基于React.js实现PC桌面端自定义弹窗组件RLayer. 前几天有分享一个Vue网页版弹框组件,今天分享一个最新开发的React PC桌面端自定义对话框组件. RLayer 一款基于react. ...
- pycharm 2018.2.4过期-激活处理方式(Axure8.0版本到期)
参考文章:https://blog.csdn.net/HALEN001/article/details/81137092 第一种方法亲测可以 大致步骤: 1.2018.8.15更新最新破解补丁Jetb ...
- sourcetree的使用(配合git)
主要讲解sourcetree的使用,是一个git提交的可视化软件,在官网上下载(windows,mac都有) 一路下载安装 首先,为了给本地sourcetree一个私钥,我们需要先下载git,然后在g ...
- App界面
首先我直接放图,存储记录一下,自己开发的app,后端是java分布式,
- Vue--子组件互相传值,子组件来回传值,传值反复横跳
Vue--子组件传值,子组件来回传值,子组件传值反复横跳 我不不仅要子组件之间直接传值,我还要传过去再传回来,传回来再传过去,子组件直接反复横跳 解决问题 给组件传值,并不知道改值的校验结果 同一个组 ...