java多线程:线程池原理、阻塞队列
一、线程池定义和使用
jdk 1.5 之后就引入了线程池。
1.1 定义
从上面的空间切换看得出来,线程是稀缺资源,它的创建与销毁是一个相对偏重且耗资源的操作,而Java线程依赖于内核线程,创建线程需要进行操作系统状态切换。为避免资源过度消耗需要设法重用线程执行多个任务。线程池就是一个线程缓存,负责对线程进行统一分配、调优与监控。(数据库连接池也是一样的道理)
什么时候使用线程池?
单个任务处理时间比较短;需要处理的任务数量很大。
线程池优势?
- 重用存在的线程,减少线程创建、消亡的开销,提高性能、提高响应速度。
- 当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性,可统一分配,调优和监控。
1.2 线程池在 jdk 已有的实现
- 在 juc 包下,有一个接口:Executor :
- Executor 又有两个子接口:ExecutorService 和 ScheduledExecutorService,常用的接口是 ExecutorService。
- 同时常用的线程池的工具类叫 Executors。
例如:
ExecutorService service = Executors.newCachedThreadPool();
Executor 框架虽然提供了如 newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()、newScheduledThreadPool() 等创建线程池的方法,但都有其局限性,不够灵活。
上面的几种方式点进去会发现,都是用 ThreadPoolExecutor 进行创建的:
- newSingleThreadExecutor 字面意思简单线程执行器。

2. newFixedThreadPool 字面意思**固定的线程池**,传参就是线程固定数目,适用于执行长期任务的场景。

3. newCachedThreadPool 字面意思**缓存线程池**,核心线程0,最大线程非常大,动态创建的特点。
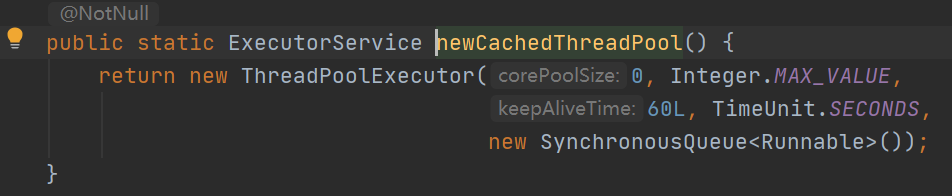
4. newScheduledThreadPool 字面意思**时间安排线程池**,指定核心线程数。

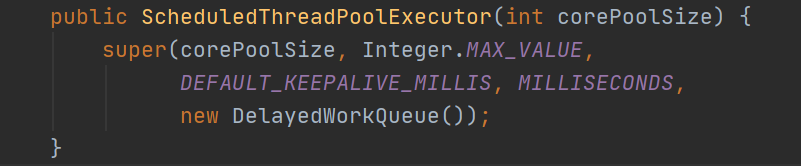
5. newSingleThreadScheduledExecutor 字面意思**单线程安排执行器**,也就是基于只有一个核心线程的执行器之外,又可以扩展。其中又用 DelegatedExecutorService 委托执行器服务进行了包装。

可以看到,上面直接用 Executors 工具类默认的一些实现 new 出来的线程池都是用的 ThreadPoolExecutor 线程执行器这个类进行构造的,不过参数不同,导致了效果的侧重点不同。
因此,自己创建线程池推荐的方法就是,直接使用 ThreadPoolExecutor 进行个性化的创建:
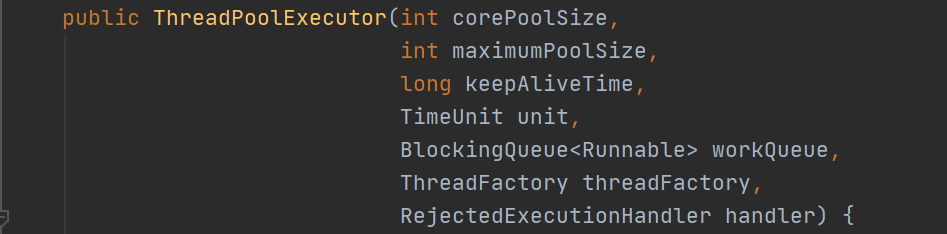
构造方法种的参数有 7 个:
- corePoolSize:线程池维护线程的最少数量 (core : 核心)
- maximumPoolSize:线程池维护线程的最大数量,显然必须>=1
- keepAliveTime:线程池维护的多余的线程所允许的空闲时间,最长可以空闲多久,时间到了,如果超过 corePoolSize 的线程一直空闲,他们就会被销毁。
- unit:线程池维护线程所允许的空闲时间的单位
- workQueue:线程池所使用的缓冲队列,已经提交但是没有执行的任务会放进这里
- threadFactory:生成线程池种工作线程的线程工厂,一般使用默认
- handler:线程池对拒绝任务的处理策略,当队列满且工作线程已经达到maximumPoolSize。
阿里的 java 开发手册,强制要求,通过 ThreadPoolExecutor 来自定义,不能使用内置的,避免资源耗尽。这个很好理解,1 的类型就只有一个核心线程和最大现场,2 没有扩展性,3、4、5的最大线程数太大,内存会爆炸。
1.3 线程池使用方法
这里我们用固定线程池来测试,传入核心线程数为 5,最大数量自然就也是 5,
public static void main(String[] args) {
ExecutorService threadPool = Executors.newFixedThreadPool(5);
try {
//模拟10个顾客办理业务
for (int i = 0; i < 10; i++){
//execute 执行方法,传入参数为实现了 Runnable 接口的类
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"号线程办理业务");
});
}
} catch (Exception e){
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
其中,execute 方法就是将任务提交的方法,我们用 lambda 表达式给 execute 方法传入了参数,实际上相当于一个完整的实现了 Runnable 接口的类。
执行结果:

可以看到,我们循环了 10 次,执行任务,但是线程只用到了 1-5 ,其中有多次复用。
再比如,我们按照各种类型的线程池,自己定义一个线程池,核心线程数 2, 最大线程数 5,阻塞队列长度为 3:
public static void main(String[] args) {
ExecutorService threadPool = new ThreadPoolExecutor(
2,
5,
2L,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
try {
//模拟10个顾客办理业务
for (int i = 0; i < 10; i++){
//execute 执行方法,传入参数为实现了 Runnable 接口的类
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"号线程办理业务");
});
}
} catch (Exception e){
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
同样 10 个线程,执行起来:
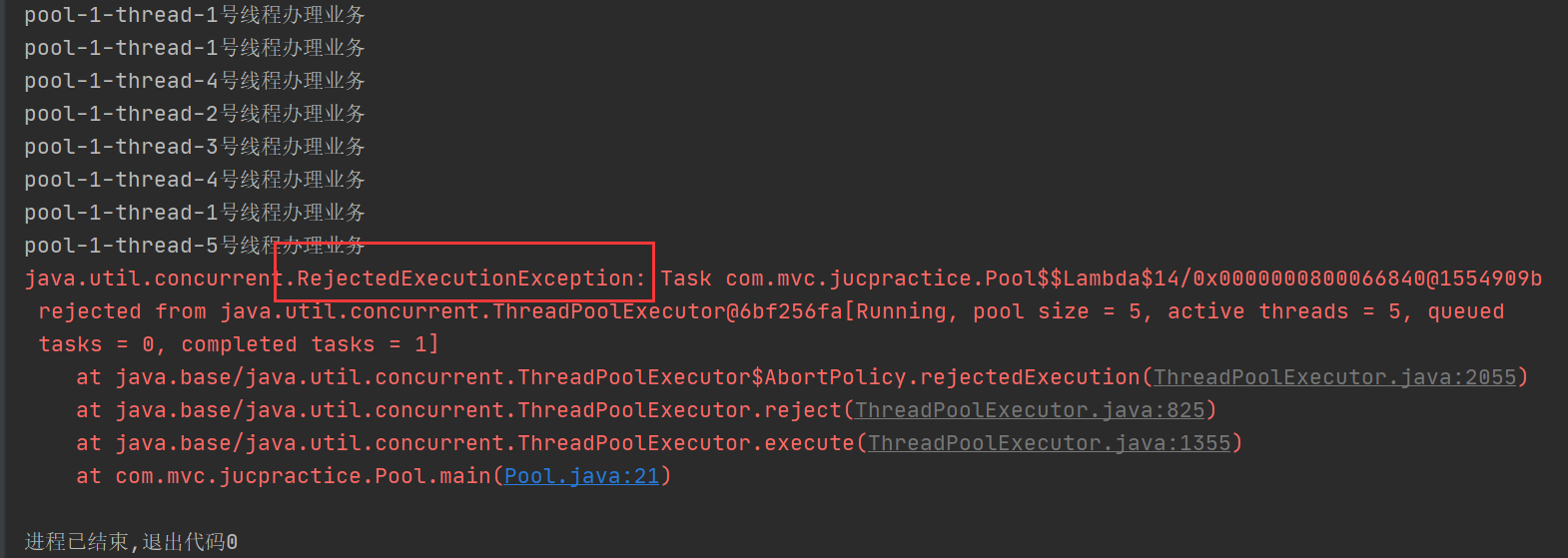
可以看到,执行了 8 个任务后,就抛出了异常,说明执行了拒绝策略。
上面两个示例,我们的任务本身都是没有返回值的,如果创建的任务本身需要有返回值就需要实现 Callable 接口,然后搭配FutureTask 来传入任务,那么线程池就应该调用 submit 方法而不是 execute。
二、线程池底层原理
2.1 线程池执行逻辑
处理的流程核心就 execute() 方法,他接收一个实现了 Runnable 接口的任务,决定对这个任务的处理策略。
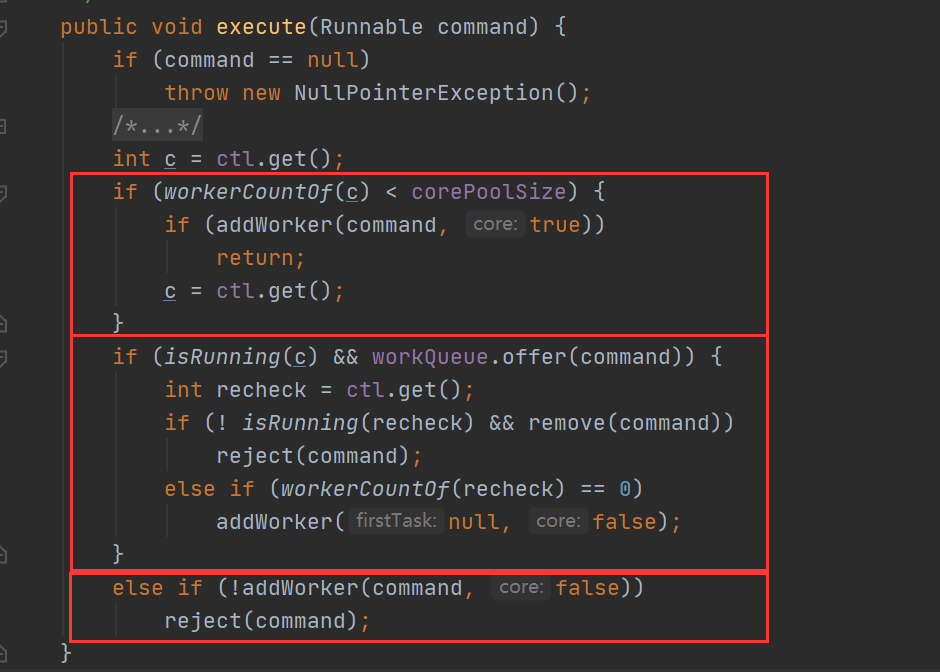
下图是一个比较形象的策略流程:
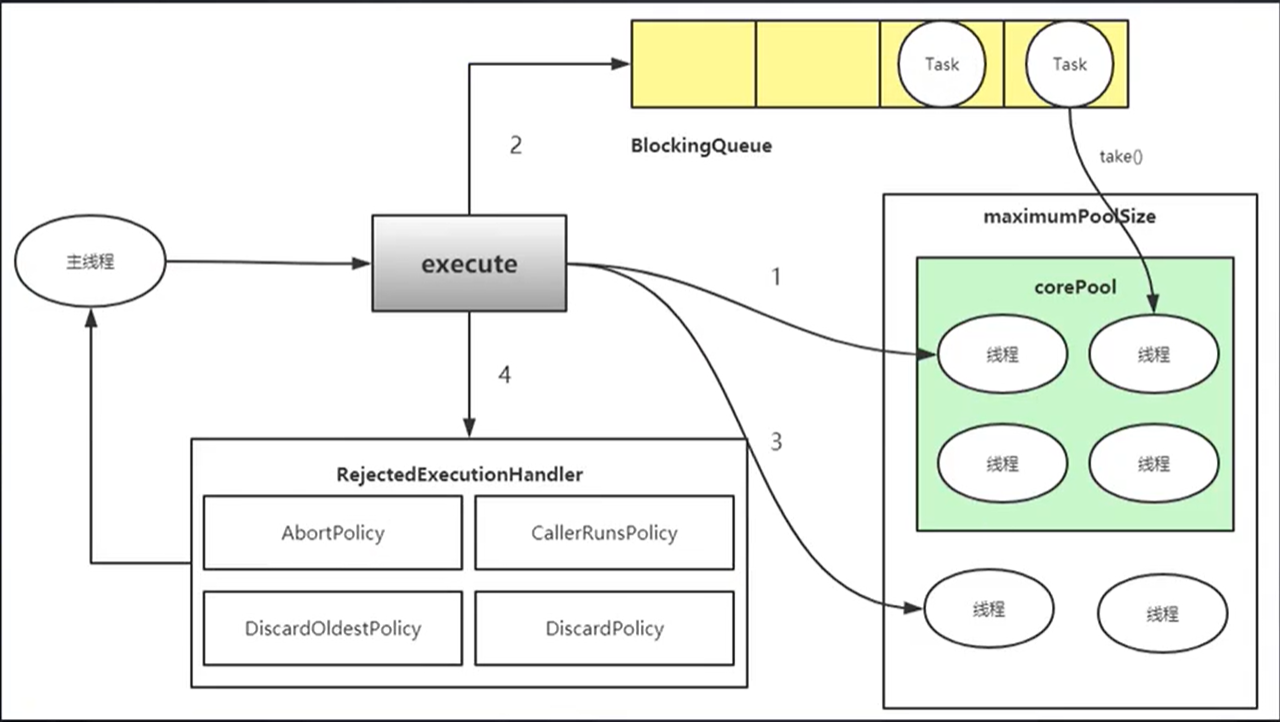
可能的情况有四种,也就是图中的1234:
- 如果线程池中的线程数量少于corePoolSize,就创建新的核心线程来执行新添加的任务
- 如果线程池中的线程数量大于等于corePoolSize,但队列workQueue未满,则将新添加的任务放到队列workQueue中
- 如果线程池中的线程数量大于等于corePoolSize,且队列workQueue已满,但线程池中的线程数量小于maximumPoolSize,则会创建新的非核心线程来处理被添加的任务
- 如果线程池中的线程数量等于了maximumPoolSize,就用RejectedExecutionHandler来执行拒绝策略。会抛出异常,一般的拒绝策略是RejectedExecutionException
注意,执行的顺序,在 java 里有一个不合理的地方:
在池里安排任务的时候,我们的核心线程,队列,非核心线程里面排的任务顺序应该是 1 2 3;
但是真正实现上,如果三个都满了,开始执行的时候,依次执行的顺序却是 核心线程,非核心线程,队列。也就是执行顺序会变成 1 3 2
2.2 拒绝策略
有些时候,我们并不希望拒绝策略是直接抛出异常,那么 jdk 里面提供的默认拒绝策略有 4 种,他们体现在代码中就是 ThreadPoolExecutor 的四个静态内部类:
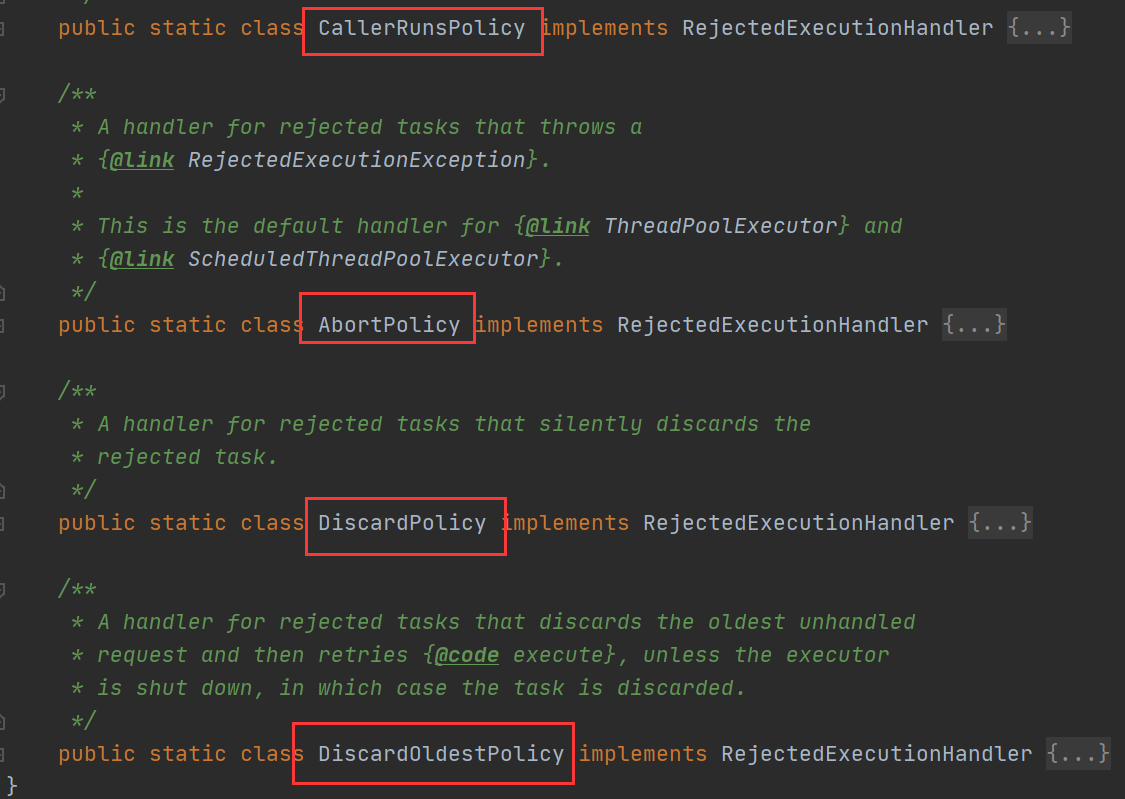
2.2.1 CallerRunsPolicy:调用者运行策略。
这种策略不会抛弃任务,也不抛出异常,而是将某些任务回退给调用者,从而降低新任务的流量。
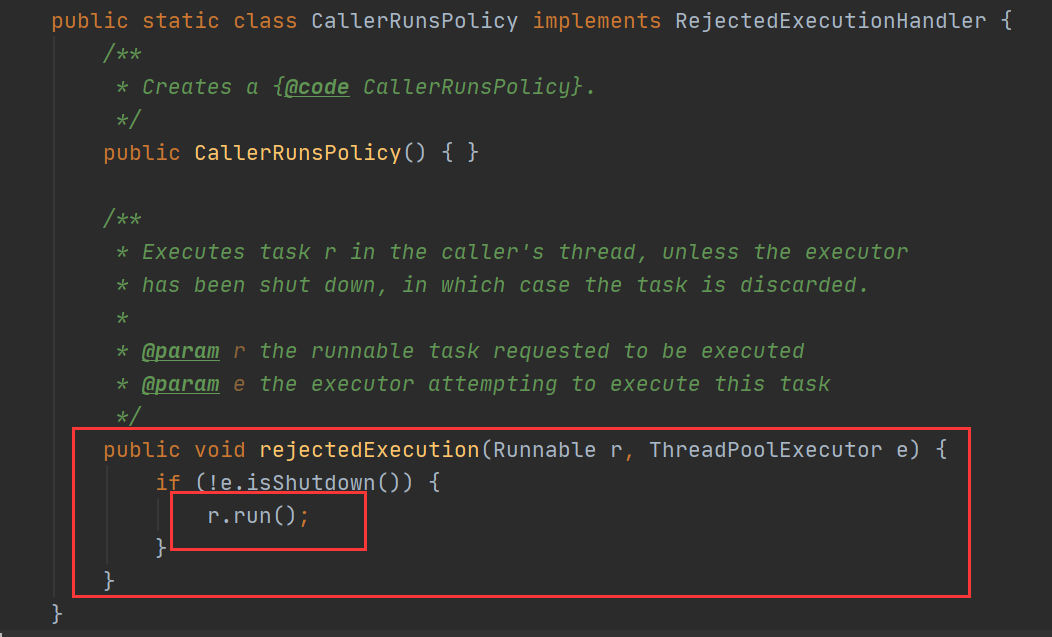
实现非常简单,那就是如果说 e 这个线程池已经 shutdown 了,那么就什么也不干,也就是这个任务直接丢了;否则,r.run() ,相当于调用这个方法的线程里直接执行了这个 Runnable 任务。
此时我们可以把 1.3 里的代码修改一下,只修改策略为
CallerRunsPolicy:
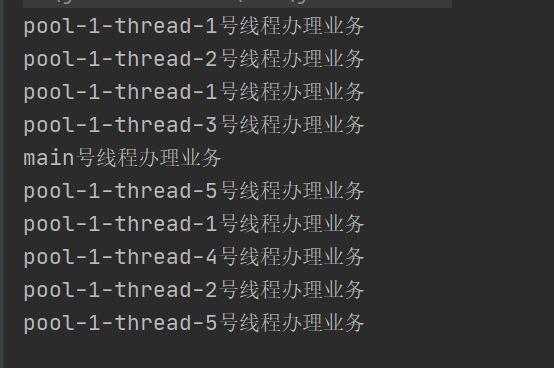
可以看到,有些任务会在 main 线程里处理。
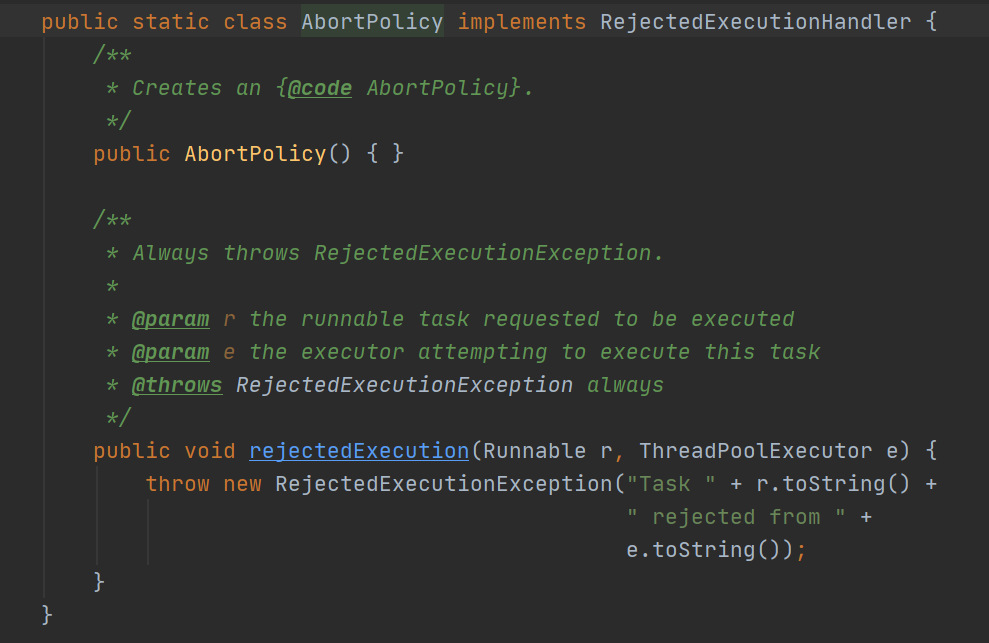
2.2.2 AbortPolicy:终止策略。
抛异常。前面已经试过了,这个是默认的拒绝策略。
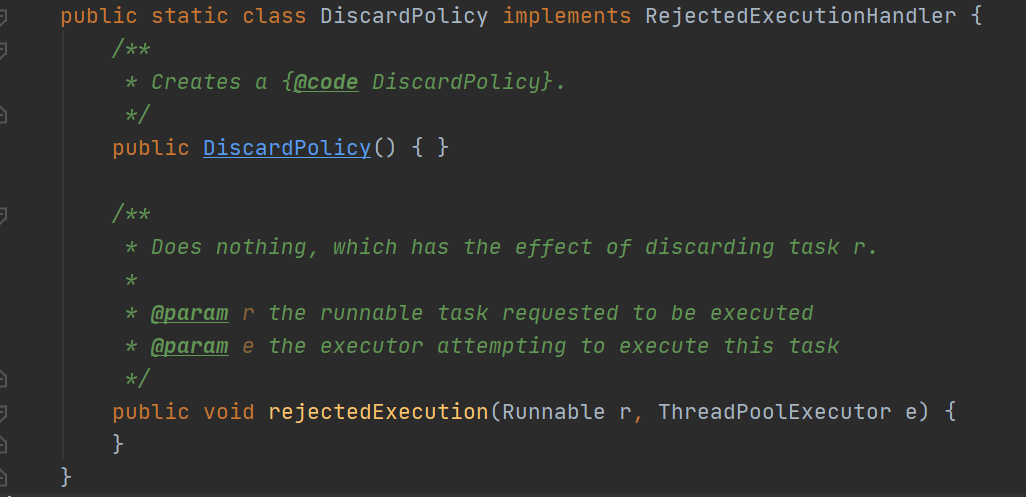
2.2.3 DiscardPolicy:丢弃任务。
可以看到,源码里就是是什么也不做。如果场景中允许任务丢失,这个是最好的策略。
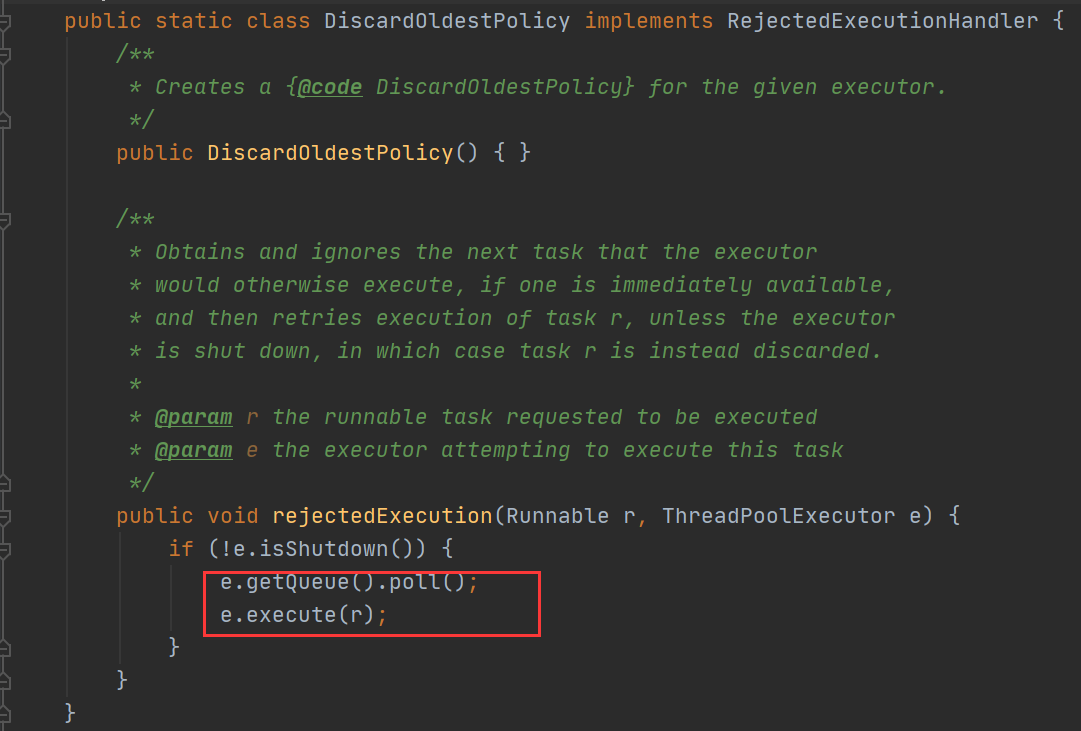
2.2.4 DiscardOldestPolicy:抛弃队列中等待最久的任务。
抛弃队列中等待最久的任务,然后把当前的任务加入队列中,尝试再次提交当前任务。
源码里也就是利用队列操作,进行一次出队操作,然后重新调用 execute 方法。
2.3 线程池的五种状态
和一个正常的线程的生命周期区别开,这个是线程池里线程的状态。
- Running,能接受新任务以及处理已添加的任务;
- Shutdown,不接受新任务,可以处理已经添加的任务,也就是不能再调用execute或者submit了;
- Stop,不接受新任务,不处理已经添加的任务,并且中断正在处理的任务;
- Tidying,所有的任务已经终止,CTL记录的任务数量为0,CTL负责记录线程池的运行状态与活动线程数量;
- Terminated,线程池彻底终止,则线程池转变为terminated的状态。
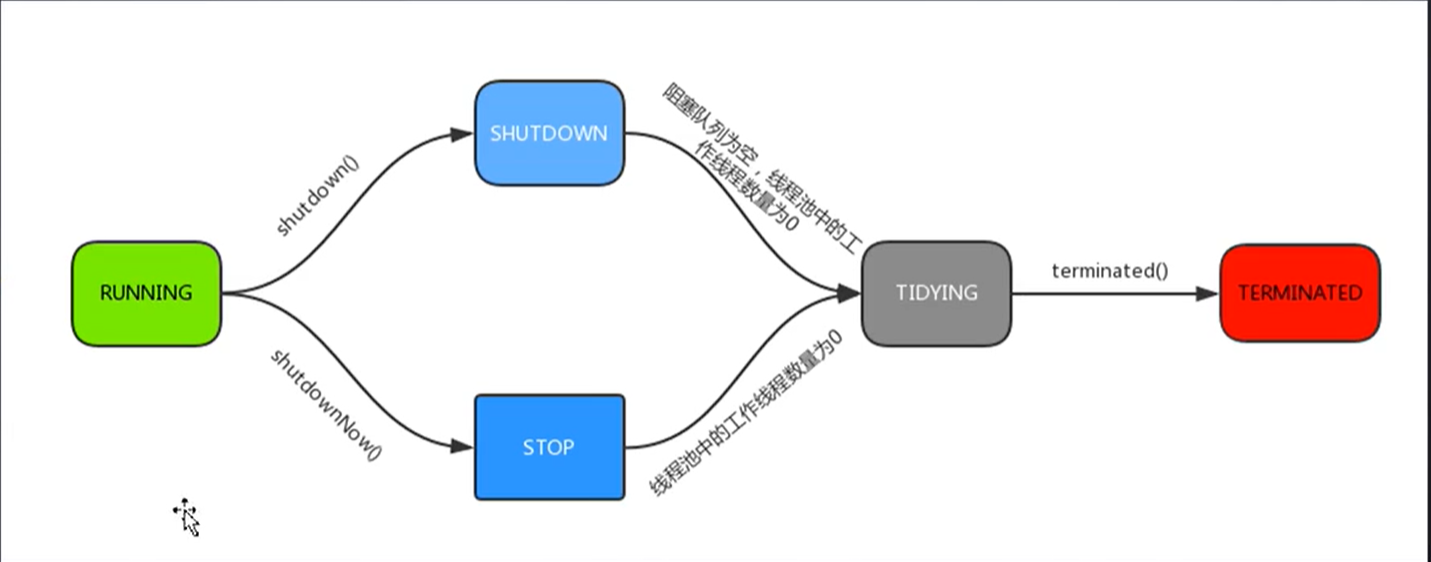
如图所示,从running状态转换为 shutdown,调用 shutdown()方法;如果调用shutdownNow()方法,就直接会变成stop。
terminated()是钩子函数,默认是什么也不做的,我们可以重写,然后决定结束之前要做一些别的处理逻辑。这个钩子函数,就是模板模式的方法。
三、阻塞队列
线程池里的 BlockingQueue,阻塞队列,事实上在消费者生产者问题里的管程法实现,我们的策略也是类似阻塞队列的,用它来做一个缓存池的作用。
阻塞队列:任意时刻,不管并发有多高,永远保证只有一个线程能够进行队列的入队或出队操作。也就意味着他是能够保证线程安全的。
另外,阻塞队列分为有界和无界队列,理论上来说一个是队列的size有固定,另一个是无界的。对于有界队列来说,如果队列存满,只能出队了,入队操作就只能阻塞。
在 juc 包里,阻塞队列的实现有很多:
- ArrayBlockingQueue:有界阻塞队列;
- LinkedBlockingQueue:链表结构(大小默认值为Integer.MAX_VALUE)的阻塞队列;
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列;
- DelayQueue:使用优先级队列实现的延迟无界阻塞队列;
- SynchronousQueue:不存储元素的阻塞队列,相当于只有一个元素;
- LinkedTransferQueue:链表组成的无界阻塞队列;
- LinkedBlockingDeque:链表组成的双向阻塞队列。
对于 BlockingQueue 来说,核心操作主要有几类:插入、删除、查找。
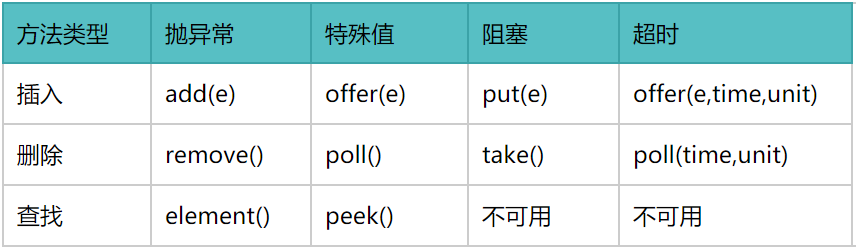
其中的四种异常策略:
- 抛异常:如果阻塞队列满,再往队列里 add 插入元素会抛 IllegalStateException:Queue full,如果阻塞队列空,再 remove 就会抛 NoSuchElementException。
- 特殊值:offer 方法:成功 true,失败 false,poll 方法,成功就返回元素,没有就返回 null。
- 阻塞:阻塞队列满的时候,生产者线程继续 put 元素,队列就会阻塞直到可以 put 数据或者响应中断然后退出,阻塞队列空的时候,消费者线程继续 take 元素,队列就会一直阻塞直到有元素可以 take。
- 超时退出:阻塞队列满的时候,会阻塞生产者线程且超时退出,空的时候会阻塞消费者线程且超时退出。
那么使用的时候,增删的方法按对应的同一组使用比较合理。(其实这个策略的设计对应的在单线程集合里也有,那就是Deque接口的实现类 LinkedList 使用的时候,不同的增删方法策略不同)
java多线程:线程池原理、阻塞队列的更多相关文章
- 跟我学Java多线程——线程池与堵塞队列
前言 上一篇文章中我们将ThreadPoolExecutor进行了深入的学习和介绍,实际上我们在项目中应用的时候非常少有直接应用ThreadPoolExecutor来创建线程池的.在jdk的api中有 ...
- 一天十道Java面试题----第三天(对线程安全的理解------>线程池中阻塞队列的作用)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 21.对线程安全的理解 22.Thread和Runnable的区别 23.说说你对守护线程的理解 24.ThreadLoc ...
- Java并发——线程池原理
"池"技术对我们来说是非常熟悉的一个概念,它的引入是为了在某些场景下提高系统某些关键节点性能,最典型的例子就是数据库连接池,JDBC是一种服务供应接口(SPI),具体的数据库连接实 ...
- 【java】-- 线程池原理分析
1.为什么要学习使用多线程? 多线程的异步执行方式,虽然能够最大限度发挥多核计算机的计算能力,但是如果不加控制,反而会对系统造成负担. 线程本身也要占用内存空间,大量的线程会占用内存资源并且可能会导致 ...
- java多线程----线程池源码分析
http://www.cnblogs.com/skywang12345/p/3509954.html 线程池示例 在分析线程池之前,先看一个简单的线程池示例. 1 import java.util.c ...
- [Java多线程]-线程池的基本使用和部分源码解析(创建,执行原理)
前面的文章:多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类) 多线程爬坑之路-Thread和Runable源码解析 多线 ...
- 最全java多线程总结3——了解阻塞队列和线程安全集合不
看了前两篇你肯定已经理解了 java 并发编程的低层构建.然而,在实际编程中,应该经可能的远离低层结构,毕竟太底层的东西用起来是比较容易出错的,特别是并发编程,既难以调试,也难以发现问题,我们还是 ...
- java多线程——线程池源码分析(一)
本文首发于cdream的个人博客,点击获得更好的阅读体验! 欢迎转载,转载请注明出处. 通常应用多线程技术时,我们并不会直接创建一个线程,因为系统启动一个新线程的成本是比较高的,涉及与操作系统的交互, ...
- <关于并发框架>Java原生线程池原理及Guava与之的补充
原创博客,转载请联系博主! 转眼快两个月没有更新自己的博客了. 一来感觉自己要学的东西还是太多,与其花几个小时写下经验分享倒不如多看几点技术书. 二来放眼网上已经有很多成熟的中文文章介绍这些用法,自己 ...
- Java ThreadPoolExecutor线程池原理及源码分析
一.源码分析(基于JDK1.6) ThreadExecutorPool是使用最多的线程池组件,了解它的原始资料最好是从从设计者(Doug Lea)的口中知道它的来龙去脉.在Jdk1.6中,Thread ...
随机推荐
- 没想到,Git居然有3种“后悔药”!
没想到,Git居然有后悔药! 你知道Git版本控制系统中都有哪些"后悔药"吗? 本文通过案例讲解git reset . git revert . git checkout在版本控制 ...
- Sql 注入----学习笔记
先了解下CRLF,CRLF常用在分隔符之间,CR是carriage retum(ASCII 13,\r) LF是Line Feed (ASCII 10,\n), \r\n这两个字符类似于回车是用于换行 ...
- springboot配置ssl访问
第一步:########################################### # 端口设置 ########################################### s ...
- vue引入 lodash
vue main.js引入 // main.js 全局引入lodash import _ from 'lodash' Vue.prototype._ = _ // 使用 this._.debounce ...
- 09 promise then
then() 方法返回一个 Promise 链式调用:then里面回调函数(成功回调和失败回调),凡事这两个回调函数里面抛出错误或者返回一个已经是拒绝状态的 Promise. 那么 then 返回的 ...
- 当this碰到return会发生什么
当this碰到return时 function fn(params) { this.user = 'fzy' return {} } var a = new fn console.log(a.user ...
- 剑指 Offer 44. 数字序列中某一位的数字
题目描述 数字以0123456789101112131415-的格式序列化到一个字符序列中.在这个序列中,第5位(从下标0开始计数)是5,第13位是1,第19位是4,等等. 请写一个函数,求任意第n位 ...
- 手写mybatis框架-增加缓存&事务功能
前言 在学习mybatis源码之余,自己完成了一个简单的ORM框架.已完成基本SQL的执行和对象关系映射.本周在此基础上,又加入了缓存和事务功能.所有代码都没有copy,如果也对此感兴趣,请赏个Sta ...
- Java单例模式的实现与破坏
单例模式是一种设计模式,是在整个运行过程中只需要产生一个实例.那么怎样去创建呢,以下提供了几种方案. 一.创建单例对象 懒汉式 public class TestSingleton { // 构造方法 ...
- python中eval()
eval()执行简单的python代码(个人感觉像是执行表达式)