关键词提取算法-TextRank
今天要介绍的TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要。因为TextRank是基于PageRank的,所以首先简要介绍下PageRank算法。
1.PageRank算法
PageRank设计之初是用于Google的网页排名的,以该公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。PageRank通过互联网中的超链接关系来确定一个网页的排名,其公式是通过一种投票的思想来设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道有哪些网页链接到网页A,也就是要首先得到网页A的入链,然后通过入链给网页A的投票来计算网页A的PR值。这样设计可以保证达到这样一个效果:当某些高质量的网页指向网页A的时候,那么网页A的PR值会因为这些高质量的投票而变大,而网页A被较少网页指向或被一些PR值较低的网页指向的时候,A的PR值也不会很大,这样可以合理地反映一个网页的质量水平。那么根据以上思想,佩奇设计了下面的公式:
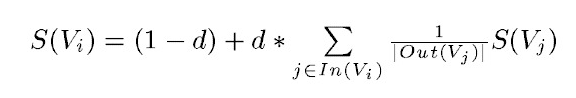
该公式中,Vi表示某个网页,Vj表示链接到Vi的网页(即Vi的入链),S(Vi)表示网页Vi的PR值,In(Vi)表示网页Vi的所有入链的集合,Out(Vj)表示网页,d表示阻尼系数,是用来克服这个公式中“d *”后面的部分的固有缺陷用的:如果仅仅有求和的部分,那么该公式将无法处理没有入链的网页的PR值,因为这时,根据该公式这些网页的PR值为0,但实际情况却不是这样,所有加入了一个阻尼系数来确保每个网页都有一个大于0的PR值,根据实验的结果,在0.85的阻尼系数下,大约100多次迭代PR值就能收敛到一个稳定的值,而当阻尼系数接近1时,需要的迭代次数会陡然增加很多,且排序不稳定。公式中S(Vj)前面的分数指的是Vj所有出链指向的网页应该平分Vj的PR值,这样才算是把自己的票分给了自己链接到的网页。
2.1 TextRank算法提取关键词
TextRank是由PageRank改进而来,其公式有颇多相似之处,这里给出TextRank的公式:
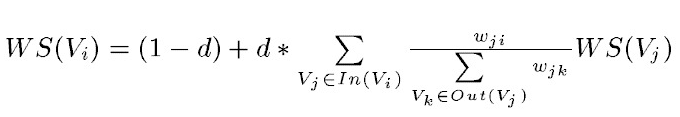
可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度。TextRank用于关键词提取的算法如下:
1)把给定的文本T按照完整句子进行分割,即

2)对于每个句子 ,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即
,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即 ,其中 ti,j 是保留后的候选关键词。
,其中 ti,j 是保留后的候选关键词。
3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
4)根据上面公式,迭代传播各节点的权重,直至收敛。
5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
6)由5得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
2.2 TextRank算法提取关键词短语
提取关键词短语的方法基于关键词提取,可以简单认为:如果提取出的若干关键词在文本中相邻,那么构成一个被提取的关键短语。
2.3TextRank生成摘要
将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边。考察句子相似度的方法是下面这个公式:
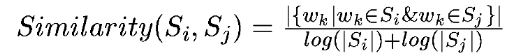
公式中,Si,Sj分别表示两个句子,Wk表示句子中的词,那么分子部分的意思是同时出现在两个句子中的同一个词的个数,分母是对句子中词的个数求对数之和。分母这样设计可以遏制较长的句子在相似度计算上的优势。
我们可以根据以上相似度公式循环计算任意两个节点之间的相似度,根据阈值去掉两个节点之间相似度较低的边连接,构建出节点连接图,然后计算TextRank值,最后对所有TextRank值排序,选出TextRank值最高的几个节点对应的句子作为摘要。
参考 http://blog.csdn.net/u013041398/article/details/52473994
关键词提取算法-TextRank的更多相关文章
- 关键词提取算法TextRank
很久以前,我用过TFIDF做过行业关键词提取.TFIDF仅仅从词的统计信息出发,而没有充分考虑词之间的语义信息.现在本文将介绍一种考虑了相邻词的语义关系.基于图排序的关键词提取算法TextRank. ...
- TextRank:关键词提取算法中的PageRank
很久以前,我用过TFIDF做过行业关键词提取.TFIDF仅仅从词的统计信息出发,而没有充分考虑词之间的语义信息.现在本文将介绍一种考虑了相邻词的语义关系.基于图排序的关键词提取算法TextRank [ ...
- 自然语言处理工具hanlp关键词提取图解TextRank算法
看一个博主(亚当-adam)的关于hanlp关键词提取算法TextRank的文章,还是非常好的一篇实操经验分享,分享一下给各位需要的朋友一起学习一下! TextRank是在Google的PageRan ...
- 关键词提取算法TF-IDF与TextRank
一.前言 随着互联网的发展,数据的海量增长使得文本信息的分析与处理需求日益突显,而文本处理工作中关键词提取是基础工作之一. TF-IDF与TextRank是经典的关键词提取算法,需要掌握. 二.TF- ...
- 关键字提取算法TF-IDF和TextRank(python3)————实现TF-IDF并jieba中的TF-IDF对比,使用jieba中的实现TextRank
关键词: TF-IDF实现.TextRank.jieba.关键词提取数据来源: 语料数据来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据 数据处 ...
- NLP之关键词提取(TF-IDF、Text-Rank)
1.文本关键词抽取的种类: 关键词提取方法分为有监督.半监督和无监督三种,有监督和半监督的关键词抽取方法需要浪费人力资源,所以现在使用的大多是无监督的关键词提取方法. 无监督的关键词提取方法又可以分为 ...
- TF-IDF算法之关键词提取
(注:本文转载自阮一峰老师的博文,原文地址:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html) 这个标题看上去好像很复杂,其实我要谈的是一个很简单的 ...
- HanLP 关键词提取算法分析
HanLP 关键词提取算法分析 参考论文:<TextRank: Bringing Order into Texts> TextRank算法提取关键词的Java实现 TextRank算法自动 ...
- HanLP 关键词提取算法分析详解
HanLP 关键词提取算法分析详解 l 参考论文:<TextRank: Bringing Order into Texts> l TextRank算法提取关键词的Java实现 l Text ...
随机推荐
- Deep Learning(5)
五.应用实例 1.计算机视觉. ImageNet Classification with Deep Convolutional Neural Networks, Alex Krizhevsky, Il ...
- CentOS软件的安装,更新与卸载命令
Linux常见的安装为tar,zip,gz,rpm,deb,bin等.我们可以简单的分为三类. 第一:打包或压缩文件tar,zip,gz等,一般解压后即可,或者解压后运行sh文件: 第二:对应的有管理 ...
- 小型网站MYSQL问题二:Percona Xtrabackup实现数据库备份和恢复
1.安装软件仓库(不要问我为什么不用源码安装,好吧,其实我懒.) 1 2 3 4 5 6 7 8 wget https://www.percona.com/downloads/percona-rele ...
- Flask 使用富文本输入框
模板 <script src="{{ url_for('static', filename='ckeditor/ckeditor.js') }}"></scrip ...
- mongo增删改查封装(C#)
Framework版本:.Net Framework 4 ConnectionUtil源码参见:https://www.cnblogs.com/threadj/p/10536273.html usin ...
- Vue学习笔记之Nodejs中的NPM使用
0x00 NPM是什么 简单的说,npm就是JavaScript的包管理工具.类似Java语法中的maven,gradle,python中的pip. 0x01 NPM安装 傻瓜式的安装. 第一步:打开 ...
- Javaworkers团队第四周项目总结
本周项目进展 本周是我们的项目开发的第四周,在之前的一周,我们小组在合作的情况下基本完成了项目代码的框架编写,我们组的项目课题,小游戏--贪吃蛇以及可以运行,可以进行简单的游戏,但是我们在思考之后发现 ...
- 如何解决ubuntu报的错误:You must put some 'source' URIs in your sources.list
答:添加deb-src开头的源,如 deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic-updates multiverse
- HDU 5934 Bomb(tarjan/SCC缩点)题解
思路:建一个有向图,指向能引爆对象,把强连通分量缩成一点,只要点燃图中入度为0的点即可.因为入度为0没人能引爆,不为0可以由别人引爆. 思路很简单,但是早上写的一直错,改了半天了,推倒重来才过了... ...
- python StringIO类
python的stringIO类用来处理字符串,由于其操作类似文件操作,可以视为内存中的文件. 1.创建stringIO 2.常用操作: write,writelines.getvalue.seek. ...