解析导航栏的url
前段时间做ui自动化测试的时候,导航栏菜单始终有点问题,最后只好直接获取到url,然后直接使用driver.get(url)进入页面;
包括做压测的时候,比如我要找出所有报表菜单的url,这样不可能手动去一个一个找出来,然后复制,这样浪费时间,并且也容易漏掉,所以我就写了个脚本来干这事;
首先说下思路:登录-->获取所有的a标签-->筛选掉不用的标签-->打印或者保存到文件中
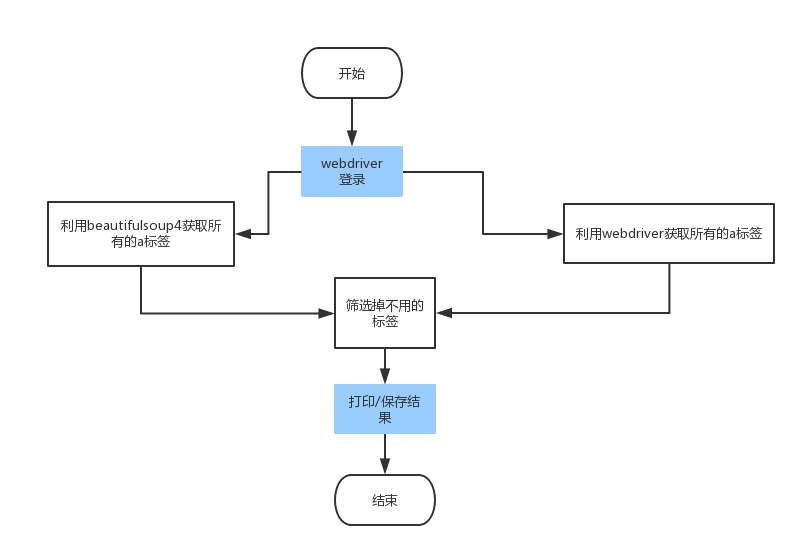
其中我获取页面所有的标签使用了两种方法,webdriver和beautifulsoup4,两种的区别:1、beautifulsoup4来解析的时候,比较稳定,并且速度快,2、webdriver可能简单一点吧,我推荐是用beautifulsoup4;之所以是用webdriver登录,是因为用webdriver登录简单,不像requests来请求的话,第一次还要分析url,参数之类的,用webdriver的话,只需要定位几个元素就ok了,何乐而不为呢。。。
下面我将两种方式的运行时间、最终的解析结果:

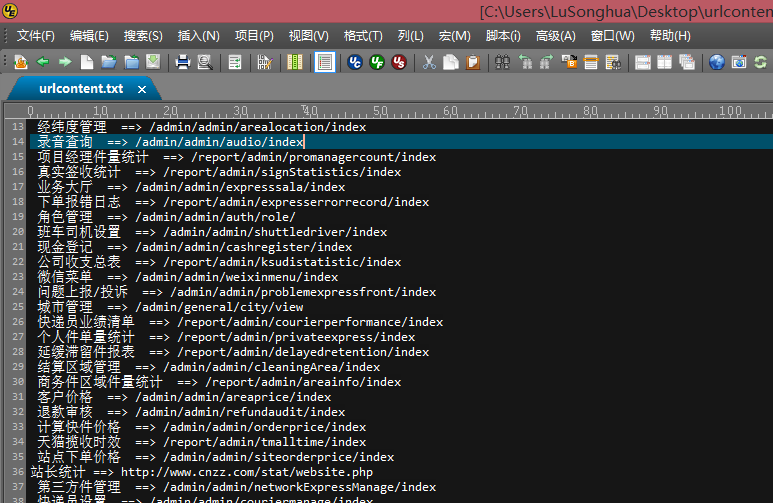
下面的是第一种方式:使用beautifulsoup4来解析:

1 #coding=utf-8
2
3 """
4 是为了获取XXX系统菜单的url
5 使用的是selenium登录,获取网页的内容,然后用beautifulsoup来解析
6 """
7 import unittest
8 import time
9 from selenium import webdriver
10 from bs4 import BeautifulSoup
11
12 # 登录url
13 url = 'http://XXXX.XXXX.com/' # 系统的url
14 username = 'XXXX'
15 password = 'XXXXX'
16
17 class GetUrl(unittest.TestCase):
18 def setUp(self):
19 self.dr = webdriver.Chrome()
20 self.dr.get(url)
21
22 def tearDown(self):
23 self.dr.quit()
24
25 def _login(self):
26 self.dr.find_element_by_id('username').send_keys(username) # 输入用户名
27 self.dr.find_element_by_id('password').send_keys(password) # 输入密码
28 # self.dr.find_element_by_id('verifycode').send_keys('XXXXX') 这里原来是需要验证码的,后来取消掉了
29 self.dr.find_element_by_id('weblogin').click() # 点击登录按钮
30 time.sleep(3)
31
32 def _gethtmlcontent(self):
33 """获取当前页面的html的所有内容"""
34 content = self.dr.page_source # 将该页面的内容 返回给content保存起来方便后面解析
35 return content
36
37 def _geturl(self,pagesource):
38 """
39 找出所有的a标签,然后筛选掉非导航连接的a标签。返回的是一个dict
40 """
41 result = dict()
42 soup = BeautifulSoup(pagesource, "lxml")
43 eles = soup.find_all("a")
44 flag = 0
45 for ele in eles:
46 if '#' in ele['href']:
47 continue
48 tmp = ele.string
49 if tmp is not None and '@' not in tmp:
50 flag += 1
51 ele_url = ele['href'].split('?')[0]
52 # print('{0} ==> {1}'.format(tmp,ele_url))
53 result[tmp] = ele_url
54
55 # print('Find out {0} datas.'.format(len(result)))
56 return result
57
58 def _writetotxt(self,contents):
59 """
60 将结果写入文件中
61 """
62 print('写入开始')
63 with open('urlcontent.txt','w') as f:
64 for title,value in contents.items():
65 f.write('{0} ==> {1}\n'.format(title,value))
66 print('写入完毕')
67
68 def test_run(self):
69 self._login()
70 pagesources = self._gethtmlcontent()
71 result = self._geturl(pagesources)
72 self._writetotxt(result)
73
74
75 if __name__ == '__main__':
76 unittest.main()
第二种全都是使用webdriver来解析的:
1 #coding=utf-8
2
3 """
4 是为了获取XXX系统菜单的url
5 使用的是selenium登录,查找元素,获取元素的属性
6 """
7 from selenium import webdriver
8 import unittest
9 import time
10
11 # 登录url
12 url = 'http://XXX.XXX.com/'
13 username = 'XXX'
14 password = 'XXX'
15
16 class GetUrl(unittest.TestCase):
17 def setUp(self):
18 self.dr = webdriver.Chrome()
19 self.dr.get(url)
20
21 def tearDown(self):
22 self.dr.quit()
23
24 def _login(self):
25 # time.sleep(2)
26 self.dr.find_element_by_id('username').send_keys(username)
27 self.dr.find_element_by_id('password').send_keys(password)
28 # self.dr.find_element_by_id('verifycode').send_keys('XXXXX')
29 self.dr.find_element_by_id('weblogin').click()
30 time.sleep(3)
31
32 def _geturl(self):
# 这里返回的是一个list,然后里面是一个个字典
33 result = list()
34 eles = self.dr.find_elements_by_css_selector('menu.u-menu a')
35 for ele in eles:
36 tmp = dict()
37 href = ele.get_attribute('href').split('?')[0]
38 # 获取菜单 的名称
39 name = ele.get_attribute('innerHTML')
40 if "<i>" not in name:
41 tmp['name'] = name.strip()
42 tmp['href'] = href
43 result.append(tmp)
44 # print('name: {0},href: {1}'.format(name,href))
45 return result
46
47 def _writetotxt(self,contents):
48 print("一共{0}条数据".format(len(contents)))
49 print('写入开始')
50 with open('urlcontent.txt','w') as f:
51 for content in contents:
52 f.write('{0} ==> {1}\n'.format(content['name'],content['href']))
53 print('写入完毕')
54
55 def test_run(self):
56 self._login()
57 self._writetotxt(self._geturl())
58
59
60 if __name__ == '__main__':
61 unittest.main()
好了,就到这里吧。。。
解析导航栏的url的更多相关文章
- 解析导航栏的url--selnium,beautifulsoup实战
前段时间做ui自动化测试的时候,导航栏菜单始终有点问题,最后只好直接获取到url,然后直接使用driver.get(url)进入页面: 包括做压测的时候,比如我要找出所有报表菜单的url,这样不可能手 ...
- day77:luffy:导航栏的实现&DjangoRestFramework JWT&多条件登录
目录 1.导航栏的实现 2.登录前戏:用户表初始化 3.DjangoRestFramework JWT 4.多条件登录 5.登录状态的判断和退出登录 1.导航栏的实现 1.设计导航栏的model模型类 ...
- Android ActionBar完全解析,使用官方推荐的最佳导航栏(下) .
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/25466665 本篇文章主要内容来自于Android Doc,我翻译之后又做了些加工 ...
- Android ActionBar完全解析,使用官方推荐的最佳导航栏(上)
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/18234477 本篇文章主要内容来自于Android Doc,我翻译之后又做了些加工 ...
- Android ActionBar全然解析,使用官方推荐的最佳导航栏(上)
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/18234477 本篇文章主要内容来自于Android Doc.我翻译之后又做了些加工 ...
- 【转】Android ActionBar完全解析,使用官方推荐的最佳导航栏(上)
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/18234477 本篇文章主要内容来自于Android Doc,我翻译之后又做了些加工 ...
- 使用jsonp形式跨域访问实现电商平台的左侧导航栏
电商平台有个具备的左侧商品类目的导航栏的结构. 通过jsonp跨域访问电商平台的后台管理系统商品分类.(主要实现后台Java代码) 实现基本步骤: 1.在后台管理系统中准备相应的json数据. poj ...
- 谈谈一些有趣的CSS题目(八)-- 纯CSS的导航栏Tab切换方案
开本系列,谈谈一些有趣的 CSS 题目,题目类型天马行空,想到什么说什么,不仅为了拓宽一下解决问题的思路,更涉及一些容易忽视的 CSS 细节. 解题不考虑兼容性,题目天马行空,想到什么说什么,如果解题 ...
- ABP(现代ASP.NET样板开发框架)系列之22、ABP展现层——导航栏设置
点这里进入ABP系列文章总目录 基于DDD的现代ASP.NET开发框架--ABP系列之22.ABP展现层——导航栏设置 ABP是“ASP.NET Boilerplate Project (ASP.NE ...
随机推荐
- 利用CMake和OpenCV源代码生成Visual Studio工程
OpenCV1.0版本有windows,linux之分,笔者曾经一直使用Opencv1.0.这个版本在下载,安装之后,在 \OpenCV\_make文件夹下面已经存在了一个opencv.dsw的工程文 ...
- 怎样设置easyui中datagrid行高
$('#face_table2').datagrid({ title: '信息', iconCls: 'icon-save', url: 'callro ...
- VS2013+opencv2.4.9配置
VS2013+opencv2.4.9(10)配置[zz] - yifeier12 - 博客园 http://www.cnblogs.com/cuteshongshong/p/4057193.html ...
- Quartz是一个完全由java编写的开源作业调度框架
http://www.quartz-scheduler.org/ 找个时间研究一下
- mybatis由浅入深day02_7.3二级缓存
7.3 二级缓存 7.3.1 原理 下图是多个sqlSession请求UserMapper的二级缓存图解. 首先开启mybatis的二级缓存. sqlSession1去查询用户id为1的用户信息,查询 ...
- ios开发之 -- 自动轮播图创建
这里是oc版本的,简单记录下: 具体代码如下: 1,准备 #define FRAME [[UIScreen mainScreen] bounds] #define WIDTH FRAME.size.w ...
- ref 属性使用eslint报错
react 使用 ref 报错 ,[eslint] Using string literals in ref attributes is deprecated. (react/no-string-re ...
- Python 数据类型:列表
一.列表介绍 1. 列表可以存储一系列的值,使用中括号来定义,每个元素之间用逗号隔开,形如 ['a', 'b', 'c', 'd']2. 列表与元组的区别是:列表中的元素是可变的,元组中的元素是不可变 ...
- IOS实例方法和类方法的区别
类方法和实例方法 实例方法是— 类开头是+ 实例方法是用实例对象访问,类方法的对象是类而不是实例,通常创建对象或者工具类. 在实例方法里,根据继承原理发送消息给self和super其实都是发送给s ...
- su命令cannot set groups: Operation not permitted的解决方法
版权声明:本文由曾倩倩原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/103 来源:腾云阁 https://www.qclo ...