hive 汇率拉链表转日连续流水表
1.什么是拉链表
拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。
我们先看一个示例,这就是一张拉链表,存储的是汇率以及每条记录的生命周期。我们可以使用这张表拿到最新的当天的最新数据以及之前的历史数据。
我们首先介绍一下我们公司用到的汇率分区拉链表
每个公司的拉链表设计可能并不相同但是拉链表以记录生命周期的设计目的是不会改变的。
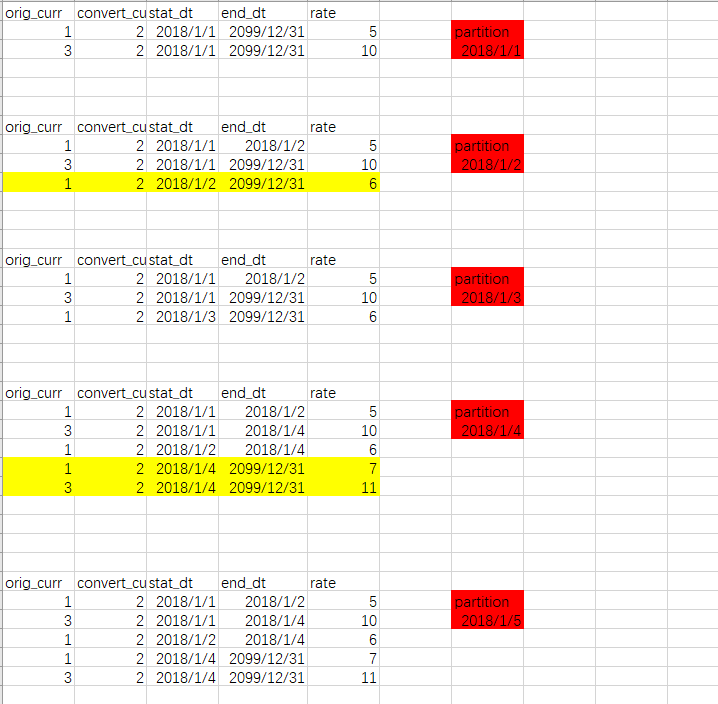
2.汇率拉链表转日连续流水表
进行对间断的时间序列补全,然后对null补全(这里的规则是取同类上一条数据的非空值)
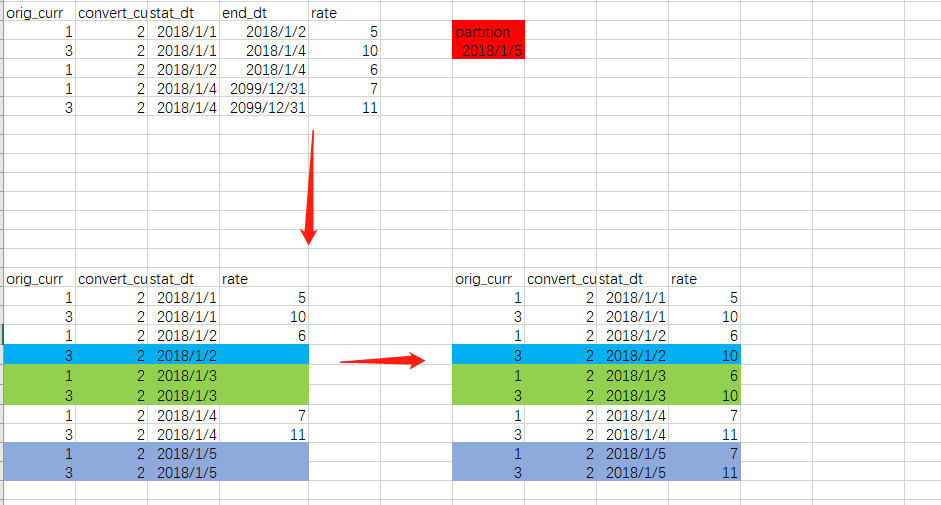
3.汇率拉链表转日连续流水表
代码实现思路是
step1.使用utf生成连续的时间序列 left join exchangeRate拉链表
step2.使用开窗函数解决补空值问题
为了简单我们用下面这个表代替
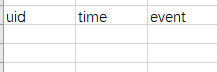
1.udtf函数
public class GenDay extends GenericUDTF {
private PrimitiveObjectInspector poi1;
private PrimitiveObjectInspector poi2;
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
if (argOIs.getAllStructFieldRefs().size() != 2) {
throw new UDFArgumentException("参数个数只能为2");
}
//如果输入字段类型非String,则抛异常
ObjectInspector oi1 = argOIs.getAllStructFieldRefs().get(0).getFieldObjectInspector();
if (oi1.getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("参数非基本类型,需要基本类型");
}
//如果输入字段类型非String,则抛异常
ObjectInspector oi2 = argOIs.getAllStructFieldRefs().get(1).getFieldObjectInspector();
if (oi2.getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("参数非基本类型,需要基本类型");
}
//强转为基本类型对象检查器
poi1 = (PrimitiveObjectInspector) oi1;
if (poi1.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentException("参数1非string,需要基本类型string");
}
poi2 = (PrimitiveObjectInspector) oi2;
if (poi2.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentException("参数1非string,需要基本类型string");
}
//构造字段名,word
List<String> fieldNames = new ArrayList<String>();
fieldNames.add("everyday");
//构造字段类型,string
List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
//通过基本数据类型工厂获取java基本类型oi
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
//构造对象检查器
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,
fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
Date dBegin=null;
Date dEnd=null;
//得到一行数据
String start = (String) poi1.getPrimitiveJavaObject(args[0]);
String end = (String) poi2.getPrimitiveJavaObject(args[1]);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
try {
dBegin = sdf.parse(start);
dEnd = sdf.parse(end);
} catch (ParseException e) {
e.printStackTrace();
}
assert dEnd != null;
List<String> lDate=getDatesBetweenTwoDate(dBegin,dEnd);
StringBuilder stringBuffer = new StringBuilder();
for (int i=0;i<lDate.size(); i += 1) {
if (i!=0){
stringBuffer.append(" ").append(lDate.get(i));
}else {
stringBuffer.append(lDate.get(i));
}
}
String s = stringBuffer.toString();
Object[] objs = new Object[1];
objs[0]= s;
forward(objs);
}
@Override
public void close() throws HiveException {
}
public List<String> getDatesBetweenTwoDate(Date beginDate, Date endDate) {
List<String> lDate = new ArrayList<String>();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
lDate.add(sdf.format(beginDate));
Calendar cal = Calendar.getInstance();
// 使用给定的 Date 设置此 Calendar 的时间
cal.setTime(beginDate);
while (true) {
// 根据日历的规则,为给定的日历字段添加或减去指定的时间量
cal.add(Calendar.DAY_OF_MONTH, 1);
// 测试此日期是否在指定日期之后
if (endDate.after(cal.getTime())) {
lDate.add(sdf.format(cal.getTime()));
} else {
break;
}
}
lDate.add(sdf.format(endDate));// 把结束时间加入集合
return lDate;
}
}
2.先用笛卡尔积找到所有的uid和连续完全的时间序列的组合,然后left join得到 时间连续但有空值的 序列。
select c.uid,c.everyday,d.event
from
(select a.uid,b.everyday from
(select uid from group by big12.test) a
join (select expode(split(everyday,' ')) as everyday select everyday from GenDay('2018-01-01','2018-12-31'))b
--笛卡尔积
on 1=1) c
left join test d
on c.uid=d.uid and c.everyday=d.time;
像是这样:
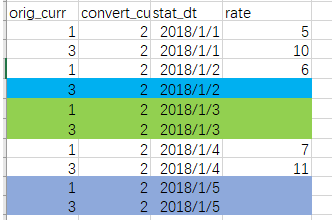
3.1用上一条数据补充字段空值(我自己想的)
不过必须单节点 对于汇率来说,一般我的口径里只用到3-5个汇率,这样最多1500条。数据量不大。有风险(自己玩吧别去生产)
package udf;
import org.apache.hadoop.hive.ql.exec.UDF;
public class GetNotNull extends UDF {
private static String lrkey = null;
private static String lrvalue = null;
public String evaluate(String key, String value) {
if (key.equals(lrkey)) {
if (value.isEmpty()) {
value = lrvalue;
}else{
lrvalue=value;
}
} else {
lrkey = key;
lrvalue = value;
}
return value;
}
}
使用静态类保存上一条非空值。
3.2用上一条数据补充字段空值
drop table if exists big12.test;
create table big12.test(
uid int,
time string,
event string
)comment ''
row format delimited
fields terminated by '\031'
stored as textfile
; insert into big12.test values(1,'2018-12-02 11:00:29','');
insert into big12.test values(1,'2018-12-02 11:00:30','');
insert into big12.test values(1,'2018-12-02 11:00:31','');
insert into big12.test values(1,'2018-12-02 11:00:32','');
insert into big12.test values(1,'2018-12-02 11:00:33','');
insert into big12.test values(2,'2018-12-02 11:00:40','');
insert into big12.test values(2,'2018-12-02 11:00:41','');
insert into big12.test values(2,'2018-12-02 11:00:42','');
insert into big12.test values(2,'2018-12-02 11:00:44',''); use big12;
select
t1.uid,
t1.time,
t2.event
from
(
select
uid,
time,
event,
row,
all_row
from
(
select
uid,
time,
event,
row_number()over(partition by case when event is not null and trim(event)<>'' then 1 else 0 end order by time asc) as row,
row_number()over( order by time asc) as all_row
from test
)t
where event is null or trim(event)=''
)t1
left join
(
select
uid,
time,
event,
row,
all_row
from
(
select
uid,
time,
event,
row_number()over(partition by case when event is not null and trim(event)<>'' then 1 else 0 end order by time asc) as row,
row_number()over( order by time asc) as all_row
from test
)t
where event is not null and trim(event)<>''
)t2
on t1.all_row-t1.row=t2.row
union all
select
uid,
time,
event
from test
where event is not null and trim(event)<>'';

hive 汇率拉链表转日连续流水表的更多相关文章
- hive 历史拉链表的处理
1. CREATE TABLE lalian_test(id int,col1 string,col2 string,dt string)--测试表COMMENT 'this is a test2' ...
- hive拉链表
前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理.设计.以及在我们大数据场景下的实现方式. 全文由下面几个部分组成:先分享一下拉链表的用途.什么是拉链表.通过一些小的使用场景来对拉链表做 ...
- 漫谈数据仓库之拉链表(原理、设计以及在Hive中的实现)
本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理.设计.以及在我们大数据场景下的实现方式. 全文由下面几个部分组成: 先分享一下拉链表的用途.什么是拉链表. 通过一些小的使用场景来对拉链表做近 ...
- hive拉链表取数
例如,一个借款用户在hive上的拉链表.(end_dt存放逻辑与普通介绍的拉链表不一致) 需要拉去它在2019-05-01日的状态, 取数逻辑是: select * from tb where sta ...
- hive拉链表以及退链例子笔记
拉链表设计: 在企业中,由于有些流水表每日有几千万条记录,数据仓库保存5年数据的话很容易不堪重负,因此可以使用拉链表的算法来节省存储空间. 例子: -- 用户信息表; 采集当日全量数据存储到 (当日 ...
- 数仓1.4 |业务数仓搭建| 拉链表| Presto
电商业务及数据结构 SKU库存量,剩余多少SPU商品聚集的最小单位,,,这类商品的抽象,提取公共的内容 订单表:周期性状态变化(order_info) id 订单编号 total_amount 订单金 ...
- DataBase 之 拉链表结构设计
一.概念 拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史.记录一个事物从开始,一直到当前状态的所有变化的信息. 在历史表中对客户的一生的记录可能就这样几条记录,避 ...
- merge实现拉链表
建表如下( 历史拉链表): 新表(每日更新的): 实现语句: MERGE INTO test_target t1 USING ( SELECT nvl(c.id, b.id) AS id ,CASE ...
- mysql执行拉链表操作
拉链表需求: 1.数据量比较大 2.变化的比例和频率比较小,例如客户的住址信息,联系方式等,比如有1千万的用户数据,每天全量存储会存储很多不变的信息,对存储也是浪费,因此可以使用拉链表的算法来节省存储 ...
随机推荐
- 3道入门字典树例题,以及模板【HDU1251/HDU1305/HDU1671】
HDU1251:http://acm.hdu.edu.cn/showproblem.php?pid=1251 题目大意:求得以该字符串为前缀的数目,注意输入格式就行了. #include<std ...
- nginx 增加认证
1.检查工具是否安装,如果未安装则使用yum安装 #htpasswd 有以上输出表示已经安装,如果没有按装,使用如下命令安装: #yum -y install httpd-tools 2.htpass ...
- 简单的搭载Spring cloud框架
大家不懂的可以在评论区给我留言
- gitlab本地部署方法(ubuntu16.04+gitlab9.5.5)
Gitlab本地部署方法 1 前期准备 电脑配置:windows7 ,内存8GB以上(因为有4GB左右要分配给虚拟机中的ubuntu) 虚拟机:VMware Linux系统:ubuntu16.04 ...
- Codeforces Round #574 (Div. 2)补题
A. Drinks Choosing 统计每种酒有多少人偏爱他们. ki 为每种酒的偏爱人数. 输出ans = (n + 1)/2 > Σki / 2 ? (n + 1)/2 - Σki / ...
- Jupyter修改默认文件保存路径
一.Jupyter安装 前提需要已经安装好python环境~ 接着,Python3x版本安装路径下执行pip命令安装 pip3 install Jupyter 看网速,安装完后会显示安装成功一段话即可 ...
- mysql在B-Tree上创建伪哈希索引
构建哈希的过程 select过程 长字符串下,构建索引可通过自定义哈希作为索引,本人通过实验,在3百多个数据记录的下,性能效果很明显,完全不是一个等级.以下为索引前后几种情况对比 无索引的url:直接 ...
- Codeforces 1240A. Save the Nature
传送门 显然可以二分答案 如果知道卖的票数,那么就能算出有多少 $a$ 倍数但不是 $b$ 倍数的位置,多少 $b$ 倍数但不是 $a$ 倍数的位置,多少既是 $a$ 又是 $b$ 倍数的位置 然后贪 ...
- asp.net 13 缓存,Session存储
1.缓存 将数据从数据库/文件取出来放在服务器的内存中,这样后面的用来获取数据,不用查询数据库,直接从内存(缓冲)中获取数据,提高了访问的速度,节省了时间,也减轻了数据库的压力. 缓冲空间换时间的技术 ...
- curl 的使用
curl 的使用 作者:与蟒唯舞链接:https://www.jianshu.com/p/f05bbd5007d9 curl 是一种命令行工具,作用是发出网络请求,然后获取数据,显示在"标准 ...