seq2seq聊天模型(三)—— attention 模型
注意力seq2seq模型
大部分的seq2seq模型,对所有的输入,一视同仁,同等处理。
但实际上,输出是由输入的各个重点部分产生的。
比如:
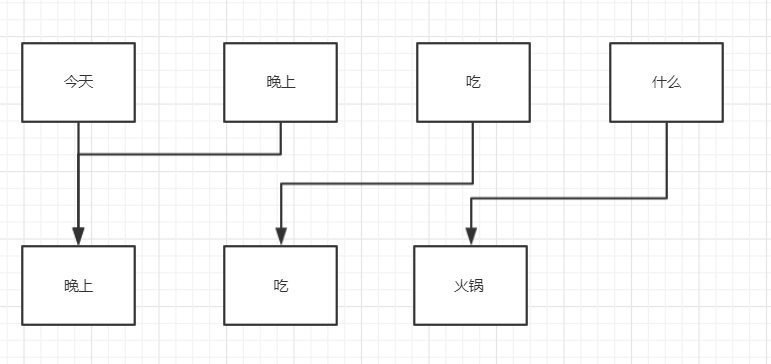
(举例使用,实际比重不是这样)
对于输出“晚上”,
各个输入所占比重: 今天-50%,晚上-50%,吃-100%,什么-0%
对于输出“吃”,
各个输入所占比重: 今天-0%,晚上-0%,吃-100%,什么-0%
特别是在seq2seq的看图说话应用情景中

睡觉还握着笔的baby
这里的重点就是baby,笔!通过这些重点,生成描述。
下面这个图,就是attention的关键原理

tensorlfow 代码
encoder 和常规的seq2seq中的encoder一样,只是在attention模型中,不再需要encoder累计的state状态,需要的是各个各个分词的outputs输出。
在训练的时候,将这个outputs与一个权重值一起拟合逼进目标值。
这个权重值,就是各个输入对目标值的贡献占比,也就是注意力机制!
dec_cell = self.cell(self.hidden_size)
attn_mech = tf.contrib.seq2seq.LuongAttention(
num_units=self.attn_size, # 注意机制权重的size
memory=self.enc_outputs, # 主体的记忆,就是decoder输出outputs
memory_sequence_length=self.enc_sequence_length,
# normalize=False,
name='LuongAttention')
dec_cell = tf.contrib.seq2seq.AttentionWrapper(
cell=dec_cell,
attention_mechanism=attn_mech,
attention_layer_size=self.attn_size,
# attention_history=False, # (in ver 1.2)
name='Attention_Wrapper')
initial_state = dec_cell.zero_state(dtype=tf.float32, batch_size=batch_size)
# output projection (replacing `OutputProjectionWrapper`)
output_layer = Dense(dec_vocab_size + 2, name='output_projection')
# lstm的隐藏层size和attention 注意机制权重的size要相同
seq2seq聊天模型(三)—— attention 模型的更多相关文章
- seq2seq聊天模型(一)
原创文章,转载请注明出处 最近完成了sqe2seq聊天模型,磕磕碰碰的遇到不少问题,最终总算是做出来了,并符合自己的预期结果. 本文目的 利用流程图,从理论方面,回顾,总结seq2seq模型, seq ...
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- 从Seq2seq到Attention模型到Self Attention
Seq2seq Seq2seq全名是Sequence-to-sequence,也就是从序列到序列的过程,是近年当红的模型之一.Seq2seq被广泛应用在机器翻译.聊天机器人甚至是图像生成文字等情境. ...
- [转] 图解Seq2Seq模型、RNN结构、Encoder-Decoder模型 到 Attention
from : https://caicai.science/2018/10/06/attention%E6%80%BB%E8%A7%88/ 一.Seq2Seq 模型 1. 简介 Sequence-to ...
- Seq2Seq模型 与 Attention 策略
Seq2Seq模型 传统的机器翻译的方法往往是基于单词与短语的统计,以及复杂的语法结构来完成的.基于序列的方式,可以看成两步,分别是 Encoder 与 Decoder,Encoder 阶段就是将输入 ...
- 文本分类实战(五)—— Bi-LSTM + Attention模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- Attention模型
李宏毅深度学习 https://www.bilibili.com/video/av9770302/?p=8 Generation 生成模型基本结构是这样的, 这个生成模型有个问题是我不能干预数据生成, ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Attention模型--训练
import tensorflow as tf # 1.参数设置. # 假设输入数据已经转换成了单词编号的格式. SRC_TRAIN_DATA = "F:\\TensorFlowGoogle ...
- SDN三种模型解析
数十年前,计算机科学家兼网络作家Andrew S. Tanenbaum讽刺标准过多难以选择,当然现在也是如此,比如软件定义网络模型的数量也很多.但是在考虑部署软件定义网络(SDN)或者试点之前,首先需 ...
随机推荐
- SAS学习笔记41 宏变量存储及间接引用
Macro Variables存储在“Symbol Table”中.它是由Macro Processor在SAS启动时自动创建并维护的.SAS提供了一张视图来供我们查看Symbol Table中的内容 ...
- 本地Pycharm将spark程序发送到远端spark集群进行处理
前言 最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置,spark集群安装并集成到hadoop集群, ...
- Luogu5327 ZJOI2019语言(树上差分+线段树合并)
暴力树剖做法显然,即使做到两个log也不那么优美. 考虑避免树剖做到一个log.那么容易想到树上差分,也即要对每个点统计所有经过他的路径产生的总贡献(显然就是所有这些路径端点所构成的斯坦纳树大小),并 ...
- C# wsdl.exe 生成类文件
wsdl.exe D:\XXX\demand\demand.\wsdl\XXX.wsdl /\wsdl\class 在 vs tools:Developer Command Prompt For VS ...
- 如何将 HTML 转换为 XHTML
1.添加一个 XHTML <!DOCTYPE> 到你的网页中 2.添加 xmlns 属性添加到每个页面的html元素中 3.改变所有的元素为小写 4.关闭所有的空元素 5.修改所有的属性名 ...
- Java Fibonacci 斐波那契亚
Java Fibonacci 斐波那契亚 /** * <html> * <body> * <P> Copyright 1994-2018 JasonInternat ...
- Swagger 实践 <一>
参考 :https://docs.microsoft.com/zh-cn/aspnet/core/tutorials/getting-started-with-nswag?view=aspnetcor ...
- ArrayList和CopyOnWriteArrayList(转载)
这篇文章的目的如下: 了解一下ArrayList和CopyOnWriteArrayList的增删改查实现原理 看看为什么说ArrayList查询快而增删慢? CopyOnWriteArrayList为 ...
- wince如何扫描条码并且在浏览器上查询数据
这个挺简单的,winform也适用 public override void OnGetBarcode(string scanStr) { try { Process.Start("iesa ...
- umi model 注册
model 分两类,一是全局 model,二是页面 model.全局 model 存于 /src/models/ 目录,所有页面都可引用:页面 model 不能被其他页面所引用. 规则如下: src/ ...