hive优化实战
2019年1月8日,付哥给了我一份公司以前的一份SQL优化方案文档。十分感谢。记录了许多在公司以前优化的案例。
--------------------------------------------------------------------------------------------------------------------------------------------------------
一、表TMP_c(58分钟)
表来源:
1.IML_a 这张表在2018年11月某一天的数据量是22025054
2.TMP_b 这表数据量是12条
优化点:
1.两张表关联的时候把BATCH_DATE的字段放在on后面,不要放在where后面。
2.大表关联小表可以使用MAPJOIN,指定MAPJOIN使用/*+mapjoin(b)+/
3.代码使用了三层嵌套查询,还可以把每一层提出放到临时表并行运行
第一点以前也用过但是具体为什么一直也没注意。今天要总结一下:
通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
在使用left jion时,on和where条件的区别如下:
我们假设有如下两张表

两条SQL:
1、select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name=’AAA’
2、select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name=’AAA’)
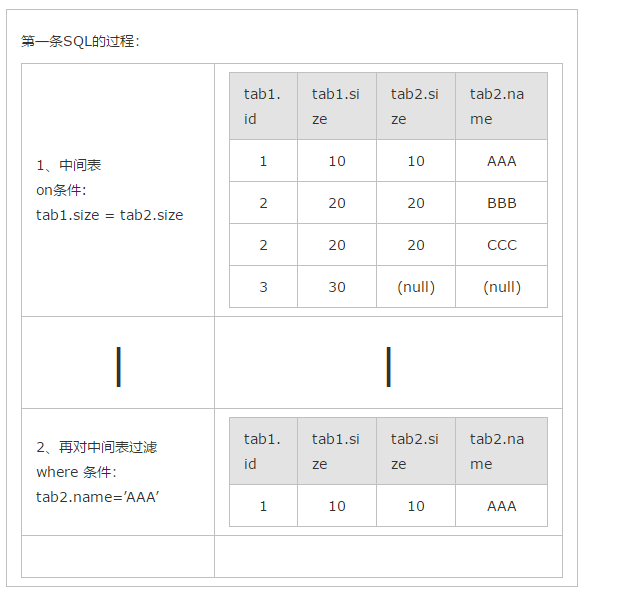
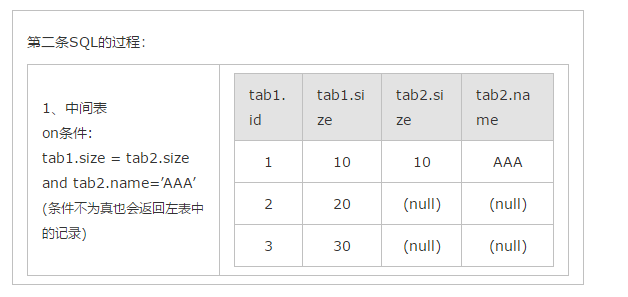
其实以上结果的关键原因就是left join,right join,full join的特殊性,不管on上的条件是否为真都会返回left或right表中的记录,full则具有left和right的特性的并集。
而inner jion没这个特殊性,则条件放在on中和where中,返回的结果集是相同的。
使用第二种中间表确实小了很多。减少了内存使用。======》》》可能是这样吧。
二、表TMP_c(58分钟)
hive优化实战的更多相关文章
- 大数据开发实战:Hive优化实战3-大表join大表优化
5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个具体的问题场景,然后基于此介绍各自优 ...
- 大数据开发实战:Hive优化实战1-数据倾斜及join无关的优化
Hive SQL的各种优化方法基本 都和数据倾斜密切相关. Hive的优化分为join相关的优化和join无关的优化,从项目的实际来说,join相关的优化占了Hive优化的大部分内容,而join相关的 ...
- 大数据开发实战:Hive优化实战2-大表join小表优化
4.大表join小表优化 和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦. 首 ...
- Hive优化-大表join大表优化
Hive优化-大表join大表优化 5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个 ...
- hive优化分享
粘贴一下我在部门中的一次hive优化的分享. 简述 hive构建在hadoop基础上,利用分布式存储,通过mr引擎实现对大数据的计算.MR会频繁地读写磁盘而且MR任务的启动成本很高.对于hive优化显 ...
- 【C#】项目优化实战
[C#]项目优化实战 一. 数据库设计 1. 常量的枚举值直接存中文不要存数字(注意是常量,如果显示值可变就不能) 例如:男女,在数据库中不要存1和0,直接存男和女. 这样的好处:读取数据的时候可以避 ...
- Android UI性能优化实战, 识别View中的性能问题
出自:[张鸿洋的博客]来源:http://blog.csdn.net/lmj623565791/article/details/45556391 1.概述 2015年初google发布了Android ...
- UNITY3d在移动设备上的一些优化实战(一)-概述
转自:UNITY3d在移动设备上的一些优化实战(一)-概述 http://blog.csdn.net/leonwei/article/details/39233921 项目进入了中期之后,就需要对程序 ...
- Hive 12、Hive优化
要点:优化时,把hive sql当做map reduce程序来读,会有意想不到的惊喜. 理解hadoop的核心能力,是hive优化的根本. 长期观察hadoop处理数据的过程,有几个显著的特征: 1. ...
随机推荐
- String类基础的那些事!
第三阶段 JAVA常见对象的学习 第一章 常见对象--String类 (一) String 类的概述及其构造方法 (1) 概述 多个字符组成的一串数据,例如 "abc" 也可以看成 ...
- yum源 epel源 替换及安装
#!/bin/sh # 备份yum源 zip -r /etc/yum.repos.d/yum_resource_back_up.zip /etc/yum.repos.d/* # 替换yum源 wget ...
- servlet获取checkbox的值出现选中的值为on。问题所在。。。
<form action="/Http/request06" method="post"> 用户名:<input type="tex ...
- fontmin字体子集
怕忘了做个记录 链接:http://ecomfe.github.io/fontmin/#feature 特点:方便,快捷.
- 【php设计模式】单例模式
实现单例的三个关键点: 1.使用一个静态成员来保持一个单例实例 2.一个私有的构造方法使得该类只能在类的内部方法中被实例化 3.在实例化对象的静态方法中,先判断静态变量是否已经被赋值,如果赋值则返回该 ...
- python学习-5 python基础-2 条件语句(if的简单用法2---elif)
1.if的基本语句 if条件: 内部代码块 else: ........ print(‘.......’) 2.if语句支持嵌套 if条件: 内部代码块 if条件: 内部代码块 else: ..... ...
- python3 虚拟环境的创建
创建虚拟环境的方法有很多种,我来分享一下我最常用的虚拟环境的创建方法和一些命令的使用, 什么是虚拟环境? 知道的可以略过,不知道的可以听我简单的说下.虚拟环境这四个字,一听你就明白什么意思了,首先理解 ...
- 代理模式与动态代理之JDK实现和CGlib实现
静态代理 静态代理中的代理类和委托类会实现同一接口或是派生自相同的父类. 由业务实现类.业务代理类 两部分组成.业务实现类 负责实现主要的业务方法,业务代理类负责对调用的业务方法作拦截.过滤.预处理, ...
- IntelliJ IDEA热部署插件JRebel免费激活图文教程(持续更新)转载
之前教了大家如何免费激活IDEA,大家学会了吗?今天再来教大家如何免费激活JRebel插件,实现真正的热部署,无论是改了代码片段还是配置文件,都可以做到不用重新启动就生效,这种酸爽,谁用谁知道! 这次 ...
- CDN内容分发
什么是CDN内容分发: CDN的全称是Content Delivery Network,即内容分发网络.CDN是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡.内容分 ...