我的Python分析成长之路5
一、装饰器:
本质是函数,装饰其他函数,为其他函数添加附加功能。
原则:
1.不能修改被装饰函数的源代码。
2.不能修改被装饰函数的调用方式。
装饰器用到的知识:
1.函数即变量 (把函数体赋值给函数名)
2.高阶函数 (1.一个函数接受另一个函数名作为实参2.返回值中含有函数名)
3.嵌套函数(一个函数嵌套这另一个函数)
先看高阶函数 :
1。要实现不修改被装饰函数的源代码,就要使用一个函数接受另一个函数名作为实参
2.要实现不修改源代码的调用方式,使用返回值中包含函数名

嵌套函数:
def test1():
print("in the test1")
def test2():
print("in the test2")
test2()
test1() #一个函数中包含另一个函数,而且内部的函数只能在内部调用
装饰器的实现
#给计算test的运行时间
def timer(func):
def wrapper():
start_time = time.time()
func()
end_time = time.time()
print("函数运行时间:%s"%(end_time-start_time))
return wrapper
@timer
def test():
time.sleep(1)
# test = timer(test)
test()
import time
def timer(func):
def wrapper(n):
start_time = time.time()
func(n)
end_time = time.time()
print("函数运行时间:%s"%(end_time-start_time))
return wrapper
@timer
def test(n): #当函数中含有参数时
time.sleep(1)
print("打印的值为:%s"%n)
# test = timer(test)
test(5)
import time
def timer(func):
def wrapper(*args,**kwargs): #当函数中含有任意多个参数参数时
start_time = time.time()
func(*args,**kwargs)
end_time = time.time()
print("函数运行时间:%s"%(end_time-start_time))
return wrapper
@timer
def test(age,name):
time.sleep(1)
# print("打印的值为:%s")
print("年龄是%s,名字是%s"%(name,age))
# test = timer(test)
test(24,name='小明')
二、迭代器与生成器
列表生成式 [i *2 for i in range(10)]
生成器 1.只有在调用的时候才会生成数据。2.只记录当前位置。3.只有next方法,直到最后抛出stopiteration才终止
第一种形式
[i *2 for i in range(10)] #列表生成式
x = (i *2 for i in range(10)) #生成器
print(x.__next__())
print(x.__next__())
print(next(x))
第二种形式
def f(maxiter):
n,a,b = 0,0,1
while n<maxiter:
yield b #用函数形成生成器 含有 yield
a,b = b,a+b
n += 1
x = f(10)
print(x.__next__()) #要想生成数据,需要调用next方法
print(x.__next__())
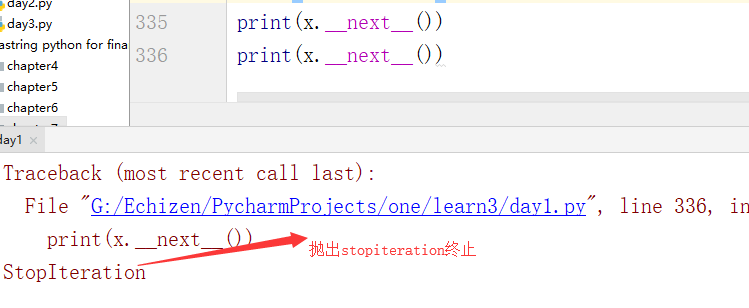
如果要获取生成器的值,就要捕获stopiteration异常
def f(maxiter):
n,a,b = 0,0,1
while n<maxiter:
yield b
a,b = b,a+b
n += 1
return "done" #如果要获取函数的返回值,就要捕获stopiteration异常
x = f(3)
while True:
try:
print("x:",x.__next__())
except StopIteration as e:
print("生成器返回值:",e.value)
break
#最简单的生产者消费者模型
import time
def consumer(name):
print("%s要准备吃包子了"%name)
while True:
baozi = yield
print("%s包子被%s吃了"%(baozi,name))
def produser(name):
c1 = consumer('A')
c2 = consumer('B')
c1.__next__()
c2.__next__()
for i in range(10):
time.sleep(1)
print("%s做了2个包子"%name)
c1.send(i)
c2.send(i)
produser('xiaoming')
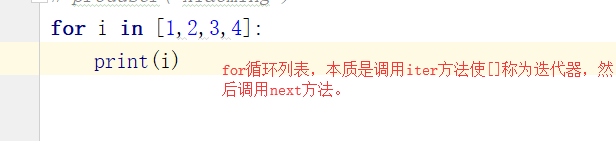
迭代器iterator:可以调用next方法,并不断返回下一个值的对象 生成器都是迭代器,list、dict、str 都是可迭代对象,但不是迭代器。可用iter方法使之称为迭代器
三、map、filter、reduce函数
print(map(lambda x:x*2,range(10)))
print(list(map(lambda x:x*2,range(10))))
#map(func,iterable)对iterable调用func 得到的是
print(list(filter(lambda x:x>5,range(10))))
#filter(func,iterable) #对可迭代对象进行筛选
print(list(filter(lambda x:x.startswith('m'),['mn','mb','b'])))
from functools import reduce
print(reduce(lambda x,y:x+y,range(10))) #进行累加操作
# reduce(func,iterable)
四、json和pickle模块
data ={'name':'zqq','age':8,'sex':"boy"}
f = open("file.json","r")
# f.write(str(data))
import json
x = json.dumps(data) #序列化 或 json.dump(data,f) dump可以多次,load只能一次
f.write(x)
data = json.loads(f.read()) #反序列化 或json.load(f)
print(data)
f.close()
f = open("ddd.txt","wb")
import pickle
x = pickle.dumps(data) #序列化 pickle.dump(data,f)
f.write(x)
f.close()
f = open("ddd.txt","rb")
import pickle
data = pickle.loads(f.read()) #反序列化 pickle.load(f)
print(data)
我的Python分析成长之路5的更多相关文章
- 我的Python分析成长之路7
类 一.编程范式: 1.函数式编程 def 2.面向过程编程 (Procedural Programming) 基本设计思路就是程序一开始是要着手解决一个大的问题,然后把一个大问题分解成很多个 ...
- 我的Python分析成长之路6
模块:本质就是.py结尾的文件.从逻辑上组织python代码. 包: 本质就是一个目录,带有__init__.py文件,从逻辑上组织模块. 模块的分类: 1.标准库(内置的模块) 2.开源库(第三方库 ...
- 我的Python分析成长之路10
matplot数据可视化基础 制作提供信息的可视化(有时称作绘图)是数据分析中最重要任务之一. 1.图片(画布)与子图 plt.figure :创建一张空白的图片,可以指定图片的大小.像素. figu ...
- 我的Python分析成长之路8
Numpy数值计算基础 Numpy:是Numerical Python的简称,它是目前Python数值计算中最为基础的工具包,Numpy是用于数值科学计算的基础模块,不但能够完成科学计算的任而且能够用 ...
- 我的Python分析成长之路11
数据预处理 如何对数据进行预处理,提高数据质量,是数据分析中重要的问题. 1.数据合并 堆叠合并数据,堆叠就是简单地把两个表拼在一起,也被称为轴向链接,绑定或连接.依照轴的方向,数据堆叠可分为横向堆叠 ...
- 我的Python分析成长之路2
2018-12-29 一.python数据类型: 1.数字 int(整形) float(浮点型) complex(复数型) 2.布尔值(bool) 真或假 True or False 3.字符 ...
- 我的Python分析成长之路1
Python是什么? ...
- 我的Python分析成长之路9
pandas入门 统计分析是数据分析的重要组成部分,它几乎贯穿整个数据分析的流程.运用统计方法,将定量与定性结合,进行的研究活动叫做统计分析.而pandas是统计分析的重要库. 1.pandas数据结 ...
- 我的Python分析成长之路4
一.函数 1.什么是函数?:函数是带名字的代码块,调用函数,只要调用函数名就可以. 2.函数的性质:1.减少重复代码 2.使程序变得可扩展 3.使程序变得易维护 3.编程范示: 1.面向对象编程 ...
随机推荐
- 前端开发---css样式的使用方式
css使用方式: 1.内联样式表: <body style="background-color:green" margin:0 ; padding:0;> 2.嵌入式样 ...
- odoo filter 日期
<!--日期--> <filter name="before_twodays" string="前天" domain="[('dat ...
- oracle删除数据库表空间
步骤一: 删除user drop user ×× cascade 说明: 删除了user,只是删除了该user下的schema objects,是不会删除相应的tablespace的. 步骤二: 删 ...
- TCP简单程序
服务器段: package com.dcz.socket; import java.io.IOException; import java.io.OutputStream; import java.n ...
- CF1062D Fun with Integers
思路: 找规律. 实现: #include <bits/stdc++.h> using namespace std; typedef long long ll; int main() { ...
- AJAX的JSON方式传回方法
AJAX返回数据的类型有两种,一种是TEXT类型,一种是JSON类型. 使用TEXT类型,访问数据库后将结果拼接成字符串,返回时在拆分成数组使用. JSON直接将结果转成JSON数据,返回时直接使用. ...
- Java 语言中一个字符占几个字节?
Java中理论说是一个字符(汉字 字母)占用两个字节. 但是在UTF-8的时候 new String("字").getBytes().length 返回的是3 表示3个字节 作者: ...
- python-mysql软件下载地址
http://sourceforge.net/projects/mysql-python/?source=dlp
- 线程池 Threadlocal 使用注意
线程池中的线程是重复使用的,即一次使用完后,会被重新放回线程池,可被重新分配使用. 因此,ThreadLocal线程变量,如果保存的信息只是针对一次请求的,放回线程池之前需要清空这些Threadloc ...
- c#将本地文件上传至服务器(内网)
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...